데이터프레임 인덱스 설정 및 제거
데이터프레임에 인덱스로 들어가 있어야 할 데이터가 일반 데이터 열에 들어가 있거나 반대로 일반 데이터 열이어야 할 것이 인덱스로 되어 있을 수 있다. 이때 set_index 명령이나 reset_index 명령으로 인덱스와 일반 데이터 열을 교환할 수 있다.
|
np.random.seed(0)
df1 = pd.DataFrame(np.vstack([list('ABCDE'),
np.round(np.random.rand(3, 5), 2)]).T,
columns=["C1", "C2", "C3", "C4"])
df1
set_index 메서드로 특정한 열을 인덱스로 설정할 수 있다. 이때 기존의 인덱스는 없어진다.
df2 = df1.set_index("C1")
df2
C2열을 인덱스로 지정하면 기존의 인덱스는 사라진다.
df2.set_index("C2")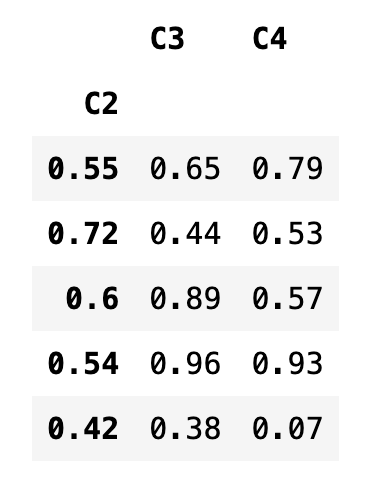
반대로 reset_index 메서드를 쓰면 인덱스를 보통의 자료열로 바꿀 수도 있다. 이때 인덱스 열은 자료열의 가장 선두로 삽입된다. 데이터프레임의 인덱스는 정수로 된 디폴트 인덱스로 바뀐다.
df2.reset_index()
다중 인덱스
행이나 열에 여러 계층을 가지는 인덱스 즉, 다중 인덱스 (multi-index)를 설정할 수도 있다. 데이터프레임을 생성할 때 columns 인수에 다음 예제처럼 리스트의 리스트 (행렬) 형태로 인덱스를 넣으면 다중 열 인덱스를 가지게 된다.
np.random.seed(0)
df3 = pd.DataFrame(np.round(np.random.randn(5, 4), 2),
columns=[["A", "A", "B", "B"],
["C1", "C2", "C1", "C2"]])
df3
다중 인덱스는 이름을 지정하면 더 편리하게 사용할 수 있다. 열 인덱스들의 이름 지정은 columns 객체의 names 속성에 리스트를 넣어서 지정한다.
df3.columns.names = ["Cidx1", "Cidx2"]
df3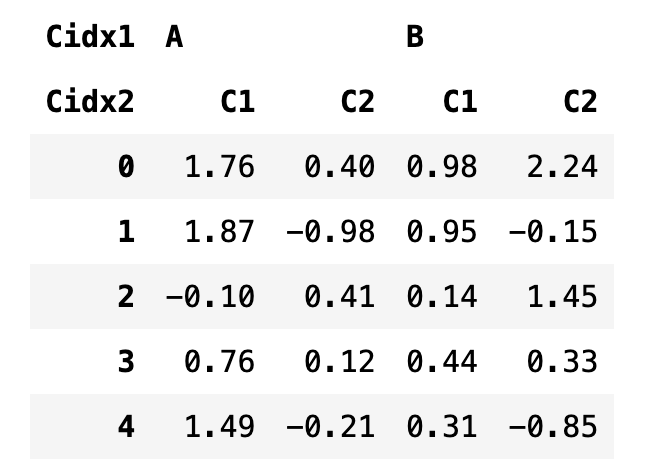
데이터프레임을 생성할 때 index 인수에 리스트의 리스트 (행렬) 형태로 인덱스를 넣으면 다중 (행) 인덱스를 가진다. 행 인덱스들의 이름 지정은 index 객체의 names 속성에 리스트를 넣어서 지정한다.
np.random.seed(0)
df4 = pd.DataFrame(np.round(np.random.randn(6, 4), 2),
columns=[["A", "A", "B", "B"],
["C", "D", "C", "D"]],
index=[["M", "M", "M", "F", "F", "F"],
["id_" + str(i + 1) for i in range(3)] * 2])
df4.columns.names = ["Cidx1", "Cidx2"]
df4.index.names = ["Ridx1", "Ridx2"]
df4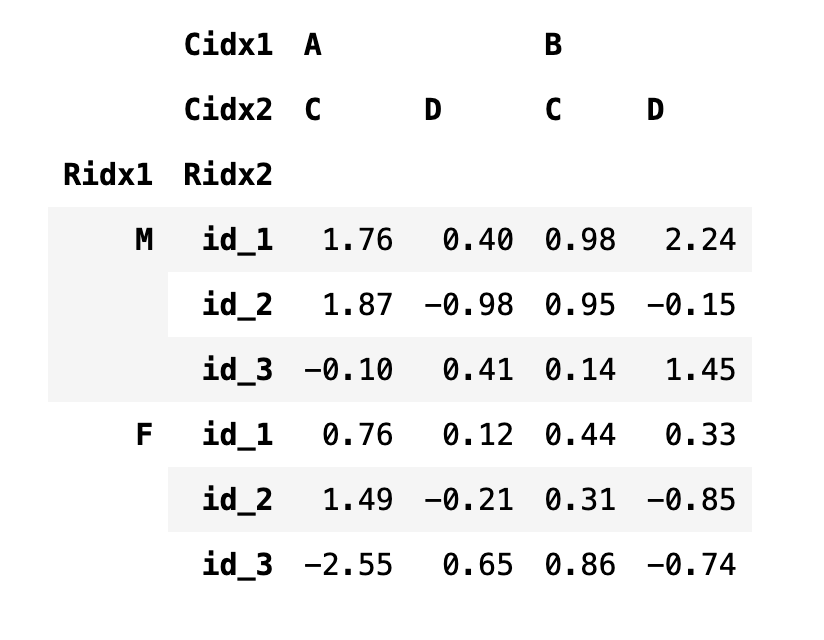
행 인덱스와 열 인덱스 교환
stack 메서드나 unstack 메서드를 쓰면 열 인덱스를 행 인덱스로 바꾸거나 반대로 행 인덱스를 열 인덱스로 바꿀 수 있다.
|
stack 메서드를 실행하면 열 인덱스가 반시계 방향으로 90도 회전한 것과 비슷한 모양이 된다. 마찬가지로 unstack 메서드를 실행하면 행 인덱스가 시계 방향으로 90도 회전한 것과 비슷하다. 인덱스를 지정할 때는 문자열 이름과 순서를 표시하는 숫자 인덱스를 모두 사용할 수 있다.
df4.stack("Cidx1")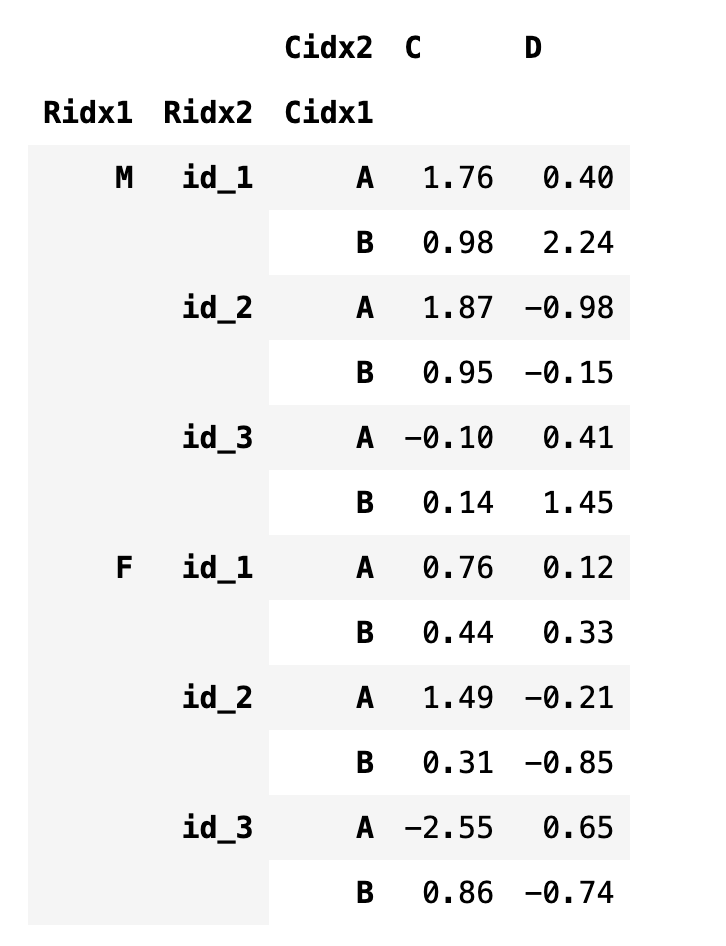
df4.stack(1)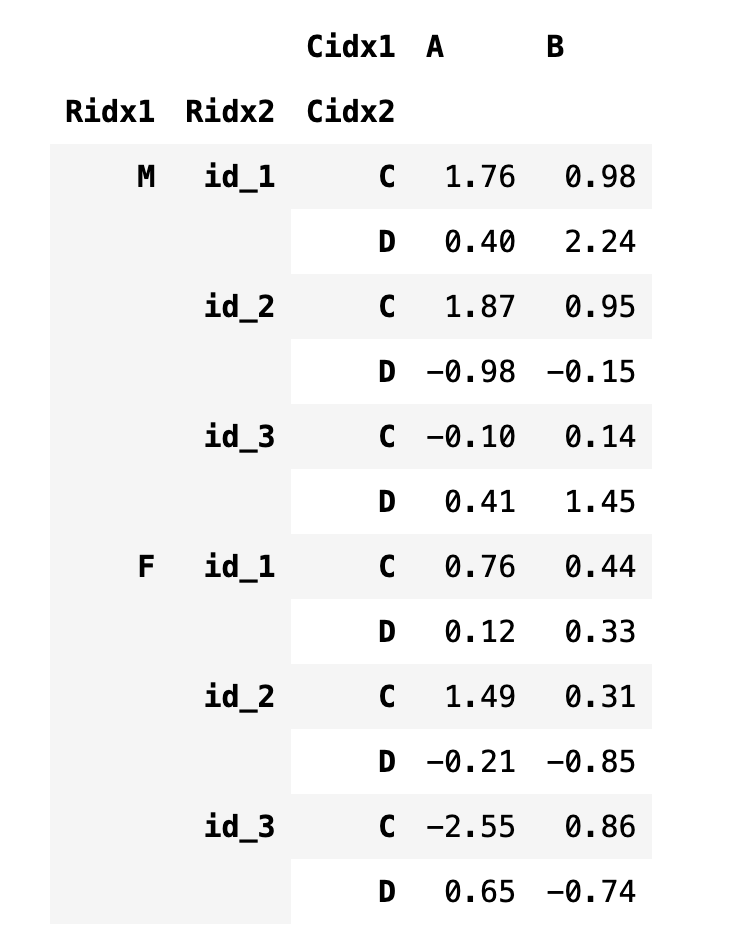
df4.unstack("Ridx2")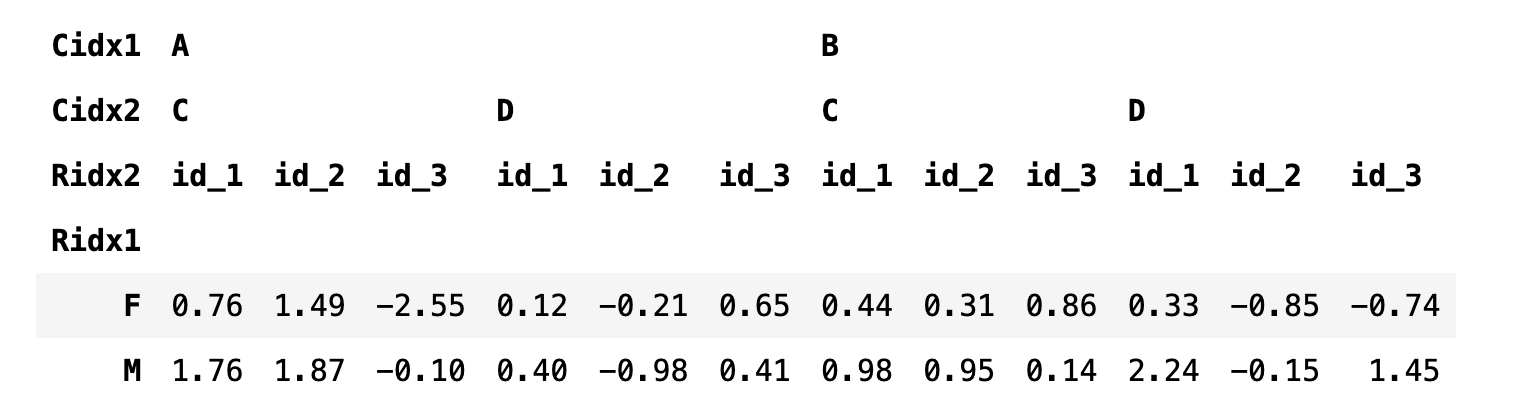
df4.unstack(0)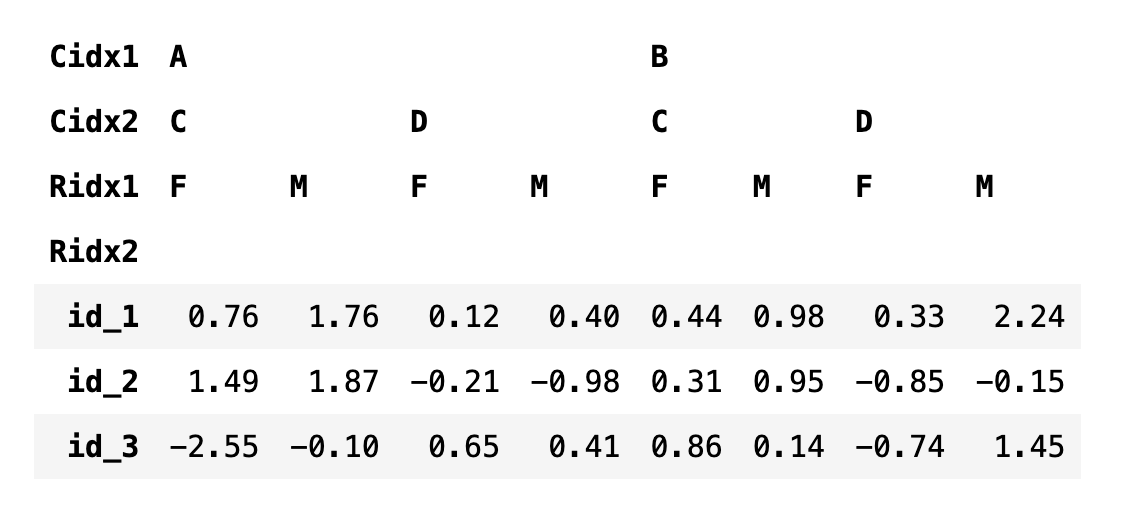
다중 인덱스가 있는 경우의 인덱싱
데이터프레임이 다중 인덱스를 가지는 경우에는 인덱스 값이 하나의 라벨이나 숫자가 아니라 ()로 둘러싸인 튜플이 되어야 한다. 예를 들어 앞에서 만든 df3 데이터프레임의 경우 다음과 같이 인덱싱할 수 있다.
df3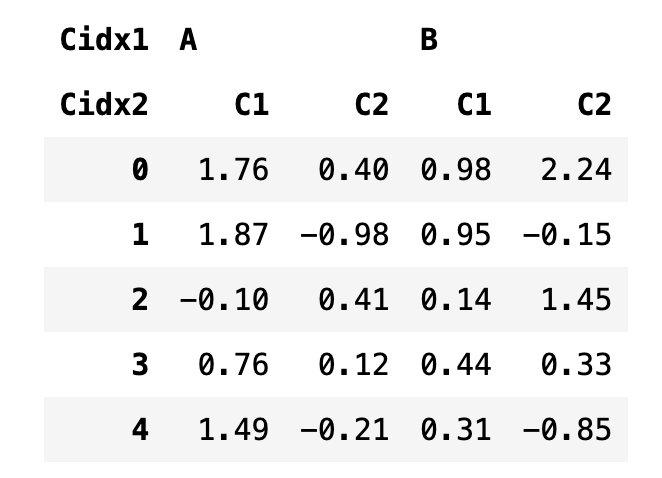
df3[("B", "C1")]
---
0 0.98
1 0.95
2 0.14
3 0.44
4 0.31
Name: (B, C1), dtype: float64
loc 인덱스를 사용하는 경우에도 마찬가지로 튜플을 써야 한다.
df3.loc[0, ("B", "C1")]
--> 0.98
df3.loc[0, ("B", "C1")] = 100
df3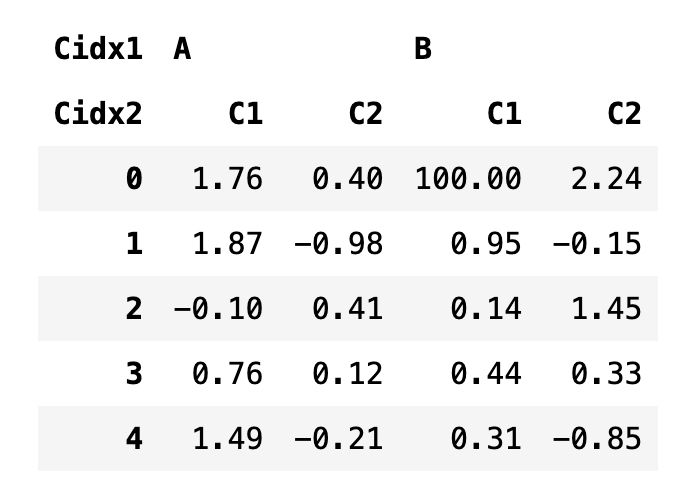
iloc 인덱서를 사용하는 경우에는 튜플 형태의 다중인덱스를 사용할 수 없다.
df3.iloc[0, 2]
--> 100.0
하나의 레벨 값만 넣으면 다중 인덱스 중에서 가장 상위의 값을 지정한 것으로 본다.
df3['A']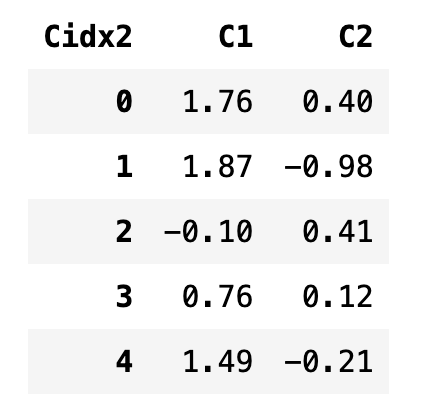
df4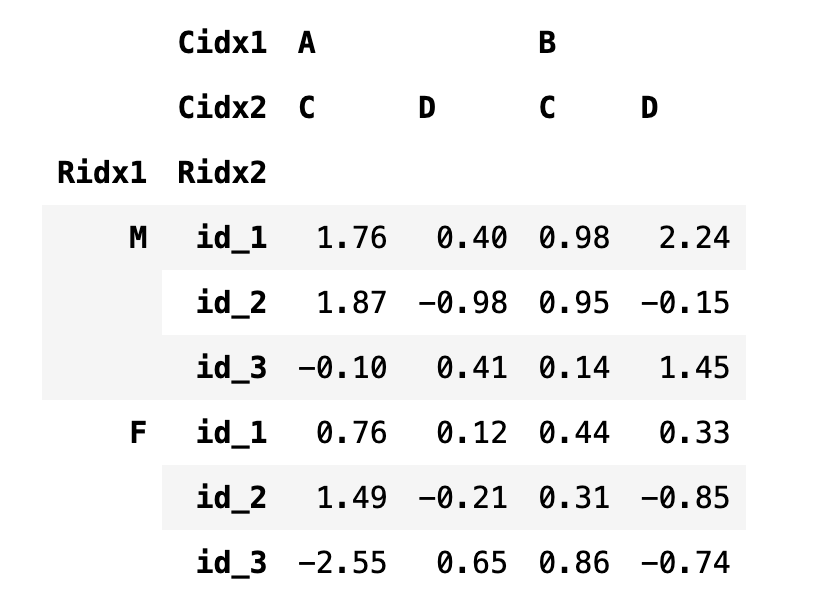
df4.loc[("M", "id_1"), ("A", "C")]
--> 1.76
df4.loc[:, ("A", "C")]
---
Ridx1 Ridx2
M id_1 1.76
id_2 1.87
id_3 -0.10
F id_1 0.76
id_2 1.49
id_3 -2.55
Name: (A, C), dtype: float64
df4.loc[("M", "id_1"), :]
---
Cidx1 Cidx2
A C 1.76
D 0.40
B C 0.98
D 2.24
Name: (M, id_1), dtype: float64
df4.loc[("All", "All"), :] = df4.sum()
df4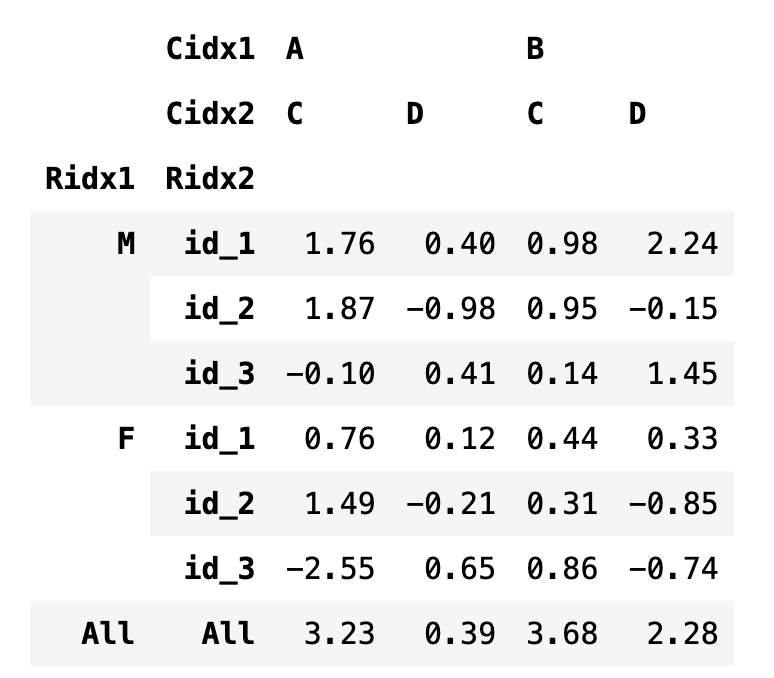
loc를 사용하는 경우에도 튜플이 아닌 하나의 값만 쓰면 가장 상위의 인덱스를 지정한 것과 같다.
df4.loc["M"]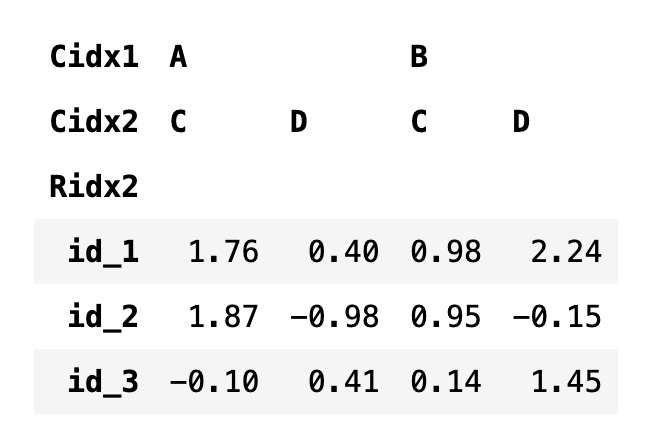
특정 레벨의 모든 인덱스 값을 인덱싱할 때는 슬라이스를 사용한다. 다만 다중 인덱스의 튜플 내에서는 : 슬라이스 기호를 사용할 수 없고 대신 slice (None) 값을 사용해야 한다.
df4.loc[("M", slice(None)), :]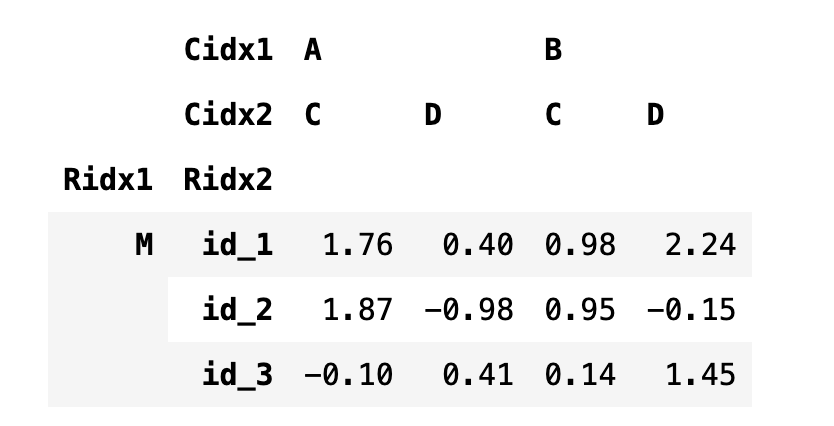
df4.loc[(slice(None), "id_1"), :]
다중 인덱스의 인덱스 순서 교환
다중 인덱스의 인덱스 순서를 바꾸고 싶으면 swaplevel 명령을 사용한다.
|
i와 j는 교환하고자 하는 인덱스 라벨( 혹은 인덱스 번호)이고 axis는 0일 때 행 인덱스, 1일 때 열 인덱스를 뜻한다. 디폴트는 행 인덱스이다.
df5 = df4.swaplevel("Ridx1", "Ridx2")
df5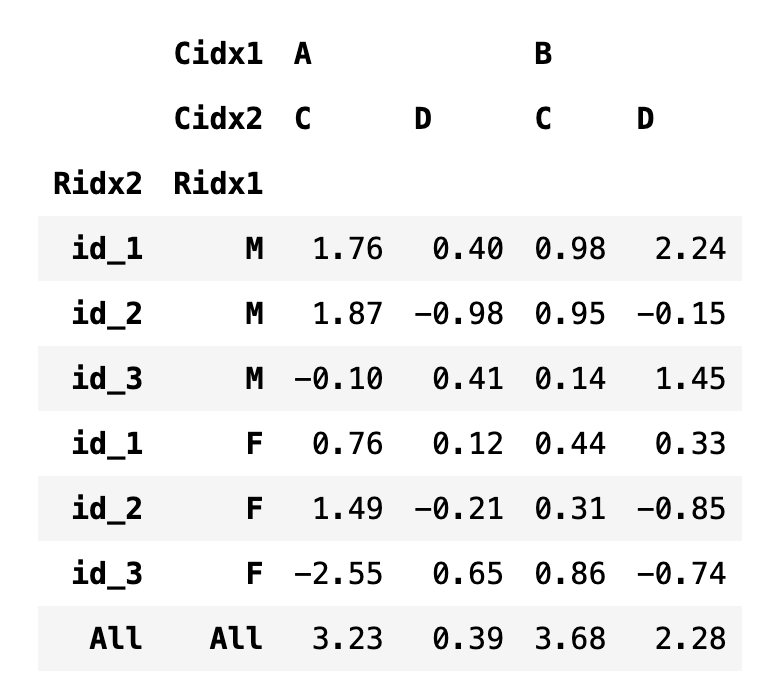
df6 = df4.swaplevel("Cidx1", "Cidx2", 1)
df6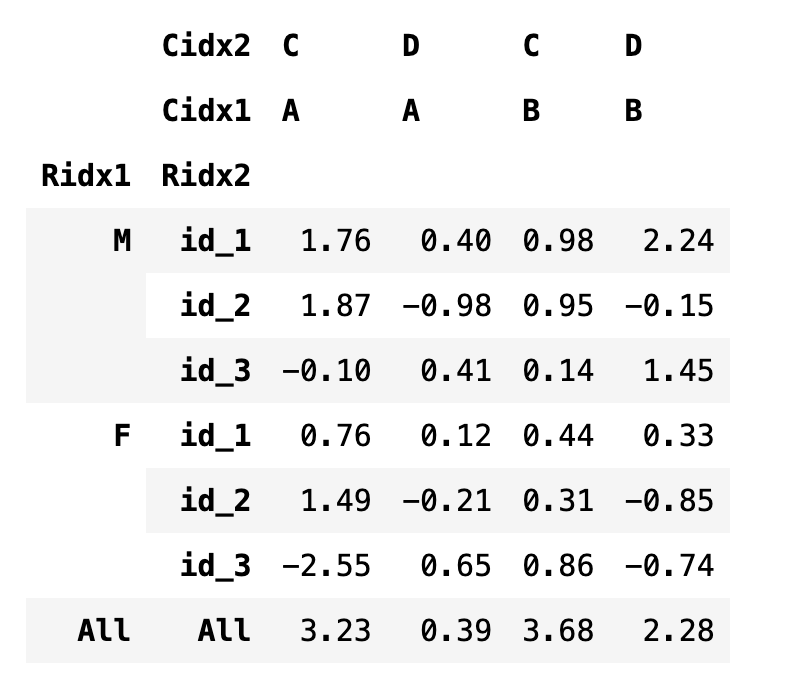
다중 인덱스가 있는 경우의 정렬
다중 인덱스가 있는 데이터프레임을 sort_index로 정렬할 때는 level 인수를 사용하여 어떤 인덱스를 기준으로 정렬하는지 알려주어야 한다.
df5.sort_index(level=0)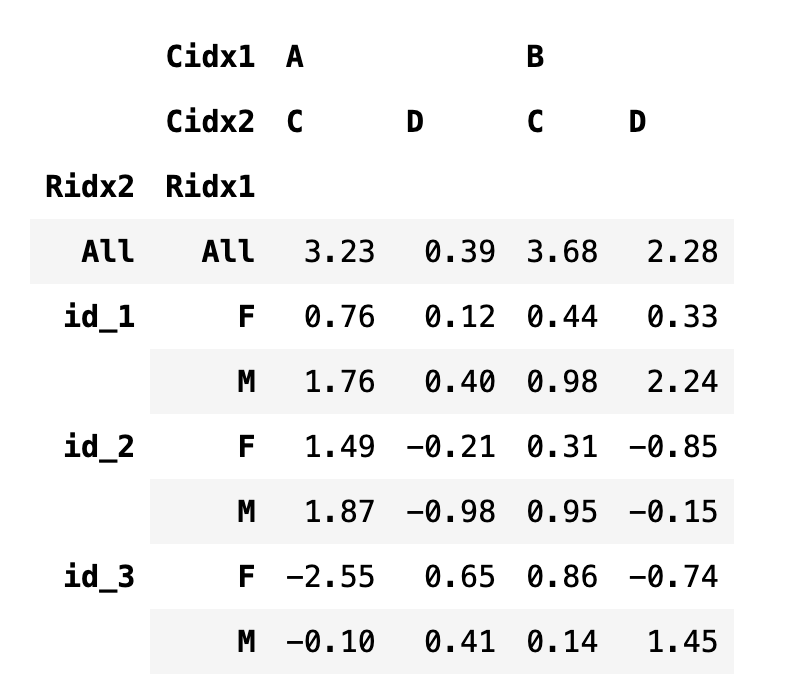
df6.sort_index(axis=1, level=0)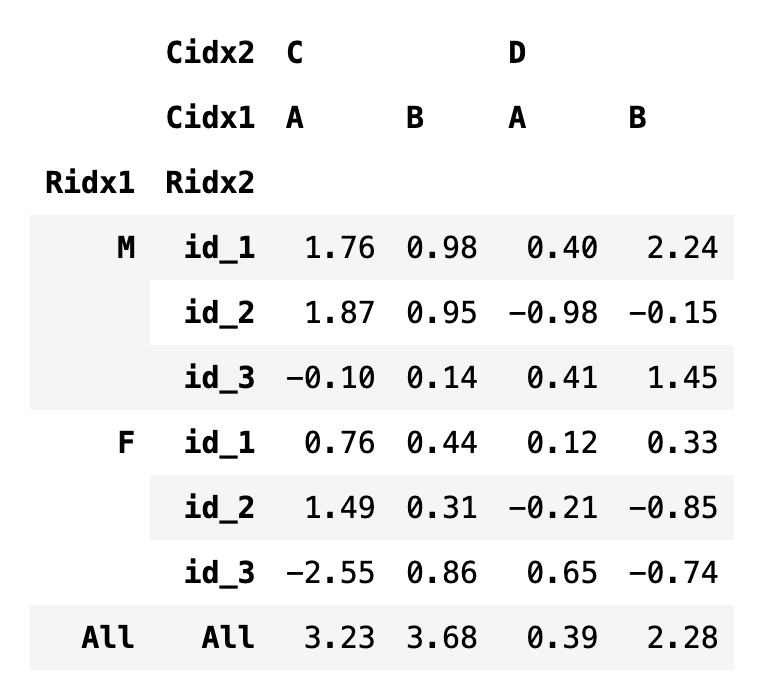
4.5 데이터프레임 인덱스 조작 — 데이터 사이언스 스쿨
.ipynb .pdf to have style consistency -->
datascienceschool.net
'Python Library > Pandas' 카테고리의 다른 글
| [Pandas] 피봇테이블과 그룹분석 (0) | 2022.02.22 |
|---|---|
| [Pandas] 데이터프레임 합성 (0) | 2022.02.21 |
| [Pandas] 데이터프레임의 데이터 조작 (0) | 2022.02.16 |
| [Pandas] 데이터프레임 고급 인덱싱 (0) | 2022.02.15 |
| [Pandas] 데이터 입출력 (0) | 2022.02.15 |



