데이터프레임의 데이터 조작
Pandas는 Numpy 2차원 배열에서 가능한 대부분의 데이터 처리가 가능하며 추가로 데이터 처리 및 변환을 위한 다양한 함수와 메서드를 제공한다.
데이터 갯수 세기
가장 간단한 데이터 분석은 데이터의 갯수를 세는 것이다. count 메서드를 사용한다. NaN 값은 세지 않는다.
s = pd.Series(range(10))
s[3] = np.nan
s
---
0 0.0
1 1.0
2 2.0
3 NaN
4 4.0
5 5.0
6 6.0
7 7.0
8 8.0
9 9.0
dtype: float64
s.count()
--> 9
데이터프레임에서는 각 열마다 별도로 데이터 갯수를 센다. 데이터에서 값이 누락된 부분을 찾을 때 유용하다.
np.random.seed(2)
df = pd.DataFrame(np.random.randint(5, size=(4, 4)), dtype=float)
df.iloc[2, 3] = np.nan
df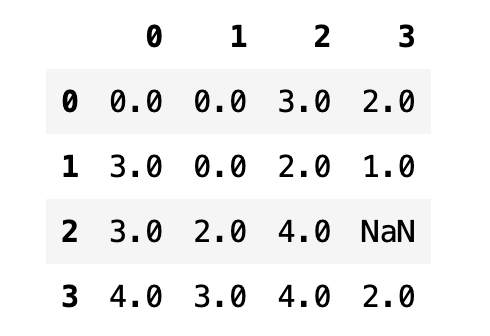
타이타닉호의 승객 데이터를 데이터프레임으로 읽어올 수 있다. 실행하려면 seaborn 패키지가 설치되어 있어야 한다.
import seaborn as sns
titanic = sns.load_dataset("titanic")
titanic.head()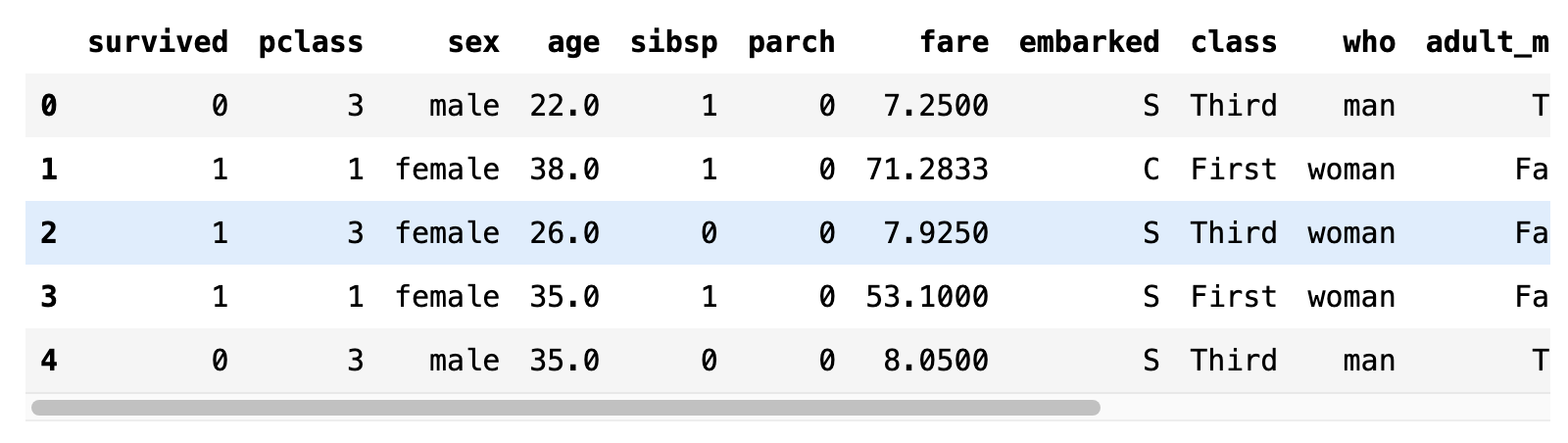
카테고리 값 세기
시리즈의 값이 정수, 문자열, 카테고리 값인 경우에는 value_counts 메서드로 각각의 값이 나온 횟수를 셀 수 있다.
np.random.seed(1)
s2 = pd.Series(np.random.randint(6, size=100))
s2.tail()
---
95 4
96 5
97 2
98 4
99 3
dtype: int64
s2.value_counts()
---
1 22
0 18
4 17
5 16
3 14
2 13
dtype: int64
데이터프레임에는 value_counts 메서드가 없으므로 각 열마다 별도로 적용해야 한다.
df[0].value_counts()
---
3.0 2
4.0 1
0.0 1
Name: 0, dtype: int64
정렬
데이터를 정렬하려면 sort_index 메서드 sort_values 메서드를 사용한다. sort_index 메서드는 인덱스 값을 기준으로, sort_values 메서드는 데이터 값을 기준으로 정렬한다.
s2.value_counts().sort_index()
---
0 18
1 22
2 13
3 14
4 17
5 16
dtype: int64
NaN 값이 있는 경우에는 정렬하면 NaN값이 가장 나중으로 간다.
s.sort_values()
---
0 0.0
1 1.0
2 2.0
4 4.0
5 5.0
6 6.0
7 7.0
8 8.0
9 9.0
3 NaN
dtype: float64
큰 수에서 작은 수로 반대 방향 정렬하려면 ascending=False 인수를 지정한다.
s.sort_values(ascending=False)
---
9 9.0
8 8.0
7 7.0
6 6.0
5 5.0
4 4.0
2 2.0
1 1.0
0 0.0
3 NaN
dtype: float64
데이터프레임에서 sort_values 메서드를 사용하려면 by 인수로 정렬 기준이 되는 열을 지정해 주어야 한다.
df.sort_values(by=1)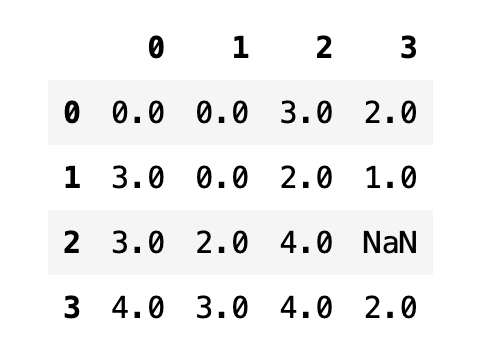
by 인수에 리스트 값을 넣으면 이 순서대로 정렬 기준의 우선 순위가 된다. 즉, 리스트의 첫번째 열을 기준으로 정렬한 후 동일한 값이 나오면 그 다음 열로 순서를 따지게 된다.
df.sort_values(by=[1, 2])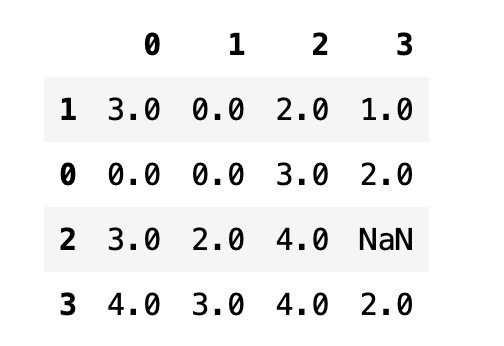
행 / 열 합계
행과 열의 합계를 구할 때는 sum(axis) 메서드를 사용한다. axis 인수에는 합계로 인해 없어지는 방향축 (0=행, 1=열)을 지정한다.
np.random.seed(1)
df2 = pd.DataFrame(np.random.randint(10, size=(4, 8)))
df2
df2["RowSum"] = df2.sum(axis=1)
df2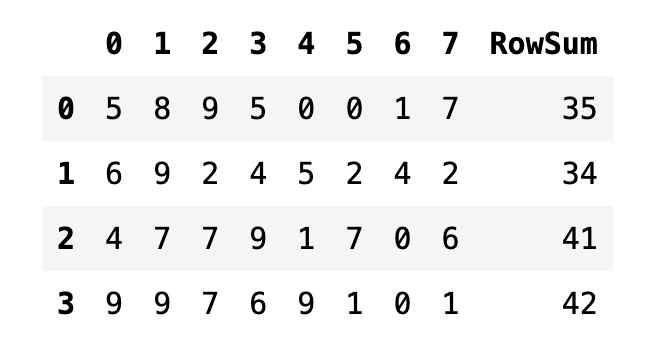
열 합계를 구할 때는 sum(axis=0) 메서드를 사용하는데 axis인수의 디폴트 값이 0이므로 axis인수를 생략할 수 있다.
df2.sum()
---
0 24
1 33
2 25
3 24
4 15
5 10
6 5
7 16
RowSum 152
dtype: int64
df2.loc["ColTotal", :] = df2.sum()
df2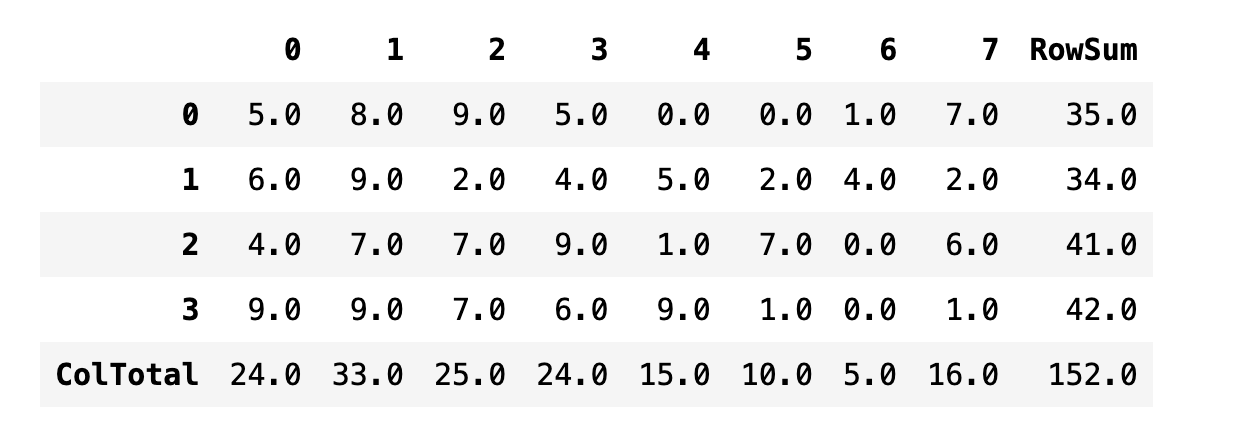
apply 변환
행이나 열 단위로 더 복잡한 처리를 하고 싶을 때는 apply 메서드를 사용한다. 인수로 행 또는 열을 받는 함수를 apply 메서드의 인수로 넣으면 각 열 (또는 행)을 반복하여 그 함수에 적용시킨다.
df3 = pd.DataFrame({
'A': [1, 3, 4, 3, 4],
'B': [2, 3, 1, 2, 3],
'C': [1, 5, 2, 4, 4]
})
df3
각 열의 최대값과 최소값의 차이를 구하고 싶으면 다음과 같은 람다 함수를 넣는다.
df3.apply(lambda x: x.max() - x.min())
---
A 3
B 2
C 4
dtype: int64
행에 대해 적용하고 싶으면 axis=1 인수를 쓴다.
df3.apply(lambda x: x.max() - x.min(), axis=1)
---
0 1
1 2
2 3
3 2
4 1
dtype: int64
각 열에 대해 어떤 값이 얼마나 사용되었는지 알고 싶다면 value_counts 함수를 넣으면 된다.
df3.apply(pd.value_counts)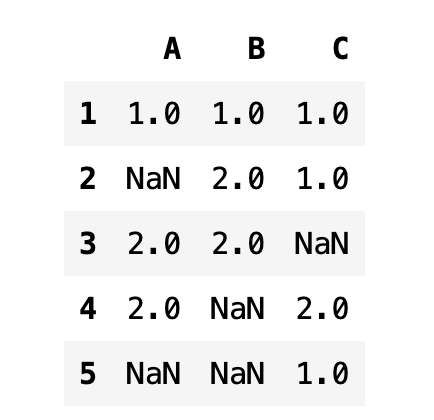
타이타닉호의 승객 중 나이 20살을 기준으로 성인 (adult)과 미성년자 (child)를 구별하는 label 열을 만들 수 있다.
titanic["adult/child"] = titanic.apply(lambda r: "adult" if r.age >= 20 else "child", axis=1)
titanic.tail()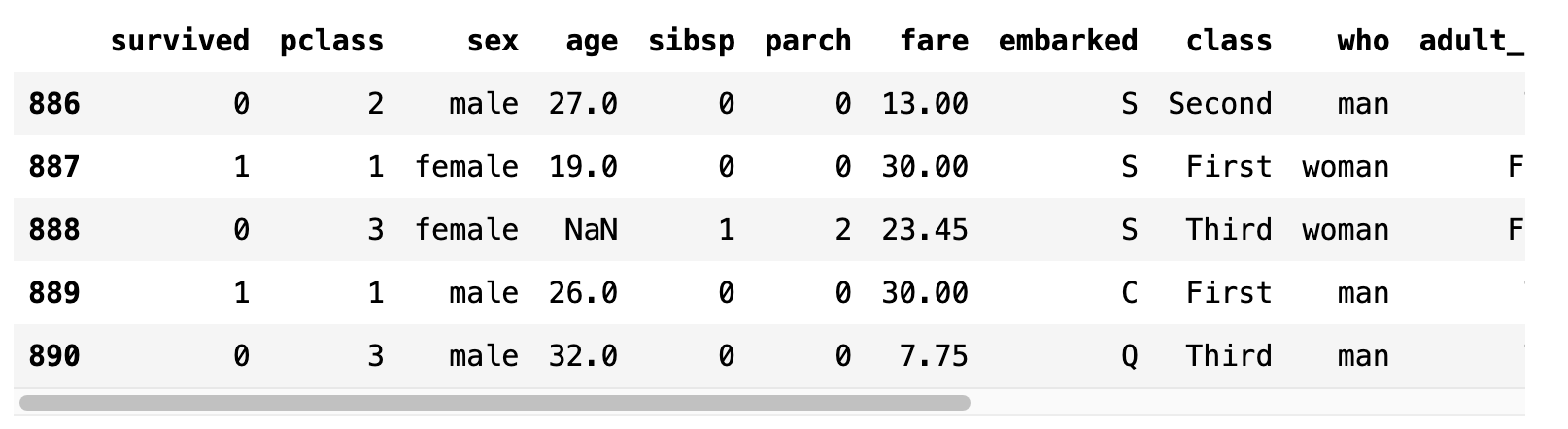
fillna 메서드
NaN 값은 fillna 메서드를 사용하여 원하는 값으로 바꿀 수 있다.
df3.apply(pd.value_counts).fillna(0.0)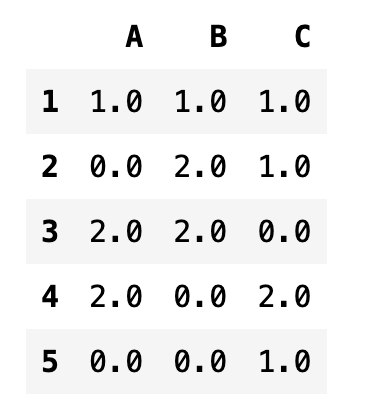
astype 메서드
astype 메서드로 전체 데이터의 자료형을 바꾸는 것도 가능하다.
df3.apply(pd.value_counts).fillna(0).astype(int)
실수 값을 카테고리 값으로 변환
실수 값을 크기 기준으로 하여 카테고리 값으로 변환한다.
|
ages = [0, 2, 10, 21, 23, 37, 31, 61, 20, 41, 32, 101]
bins = [1, 20, 30, 50, 70, 100]
labels = ["미성년자", "청년", "중년", "장년", "노년"]
cats = pd.cut(ages, bins, labels=labels)
cats
---
[NaN, 미성년자, 미성년자, 청년, 청년, ..., 장년, 미성년자, 중년, 중년, NaN]
Length: 12
Categories (5, object): [미성년자 < 청년 < 중년 < 장년 < 노년]
4.4 데이터프레임의 데이터 조작 — 데이터 사이언스 스쿨
.ipynb .pdf to have style consistency -->
datascienceschool.net
'Python Library > Pandas' 카테고리의 다른 글
| [Pandas] 데이터프레임 합성 (0) | 2022.02.21 |
|---|---|
| [Pandas] 데이터프레임 인덱스 조작 (0) | 2022.02.16 |
| [Pandas] 데이터프레임 고급 인덱싱 (0) | 2022.02.15 |
| [Pandas] 데이터 입출력 (0) | 2022.02.15 |
| [Pandas] 데이터프레임 (DataFrame) (0) | 2022.02.15 |



