데이터프레임 합성
pandas는 두 개 이상의 데이터프레임을 하나로 합치는 데이터 병합 (merge)이나 연결 (concatenate)을 지원한다.
merge 함수를 사용한 데이터프레임 병합
merge 함수는 두 데이터프레임의 공통 열 혹은 인덱스를 기준으로 두 개의 테이블을 합친다. 이 때 기준이 되는 열, 행의 데이터를 키 (key)라고 한다.
df1 = pd.DataFrame({
'고객번호': [1001, 1002, 1003, 1004, 1005, 1006, 1007],
'이름': ['둘리', '도우너', '또치', '길동', '희동', '마이콜', '영희']
}, columns=['고객번호', '이름'])
df1
df2 = pd.DataFrame({
'고객번호': [1001, 1001, 1005, 1006, 1008, 1001],
'금액': [10000, 20000, 15000, 5000, 100000, 30000]
}, columns=['고객번호', '금액'])
df2
merge 함수로 위의 두 데이터프레임 df1, df2 를 합치면 공통 열인 고객번호 열을 기준으로 데이터를 찾아서 합친다. 이때 기본적으로는 양쪽 데이터프레임에 모두 키가 존재하는 데이터만 보여주는 inner join 방식을 사용한다.
pd.merge(df1, df2)
outer join 방식은 키 값이 한쪽에만 있어도 데이터를 보여준다.
pd.merge(df1, df2, how='outer')
left, right 방식은 각각 첫번째, 혹은 두번째 데이터프레임의 키 값을 모두 보여준다.
pd.merge(df1, df2, how='left')
pd.merge(df1, df2, how='right')
테이블에 키 값이 같은 데이터가 여러개 있는 경우에는 있을 수 있는 모든 경우의 수를 따져서 조합을 만들어 낸다.
df1 = pd.DataFrame({
'품종': ['setosa', 'setosa', 'virginica', 'virginica'],
'꽃잎길이': [1.4, 1.3, 1.5, 1.3]},
columns=['품종', '꽃잎길이'])
df1
df2 = pd.DataFrame({
'품종': ['setosa', 'virginica', 'virginica', 'versicolor'],
'꽃잎너비': [0.4, 0.3, 0.5, 0.3]},
columns=['품종', '꽃잎너비'])
df2
데이터에서 키 값 setosa에 대해 왼쪽 데이터프레임는 1.4와 1.3라는 2개의 데이터, 오른쪽 데이터프레임에 0.4라는 1개의 데이터가 있으므로 병합된 데이터에는 setosa가 (1.4, 0.4), (1.3, 0.4) 두 개의 데이터가 생긴다. 키 값 virginica의 경우에는 왼쪽 데이터프레임에 1.5와 1.3라는 2개의 데이터, 오른쪽 데이터프레임에 0.3와 0.5라는 2개의 데이터가 있으므로 2개와 2개의 조합에 의해 4가지 값이 생긴다.
pd.merge(df1, df2)
두 데이터프레임에서 이름이 같은 열은 모두 키가 된다. 만약 이름이 같아도 키가 되면 안되는 열이 있다면 on 인수로 기준열을 명시해야 한다. 다음 예에서 첫번째 데이터프레임의 “데이터”는 실제로는 금액을 나타내는 데이터이고 두번째 데이터프레임의 “데이터”는 실제로는 성별을 나타내는 데이터이므로 이름이 같아도 다른 데이터이다. 따라서 이 열은 기준열이 되면 안된다.
df1 = pd.DataFrame({
'고객명': ['춘향', '춘향', '몽룡'],
'날짜': ['2018-01-01', '2018-01-02', '2018-01-01'],
'데이터': ['20000', '30000', '100000']})
df1
df2 = pd.DataFrame({
'고객명': ['춘향', '몽룡'],
'데이터': ['여자', '남자']})
df2
pd.merge(df1, df2, on='고객명')
이때 기준 열이 아니면서 이름이 같은 열에는 _x 또는 _y 와 같은 접미사가 붙는다.
반대로 키가 되는 기준열의 이름이 두 데이터프레임에서 다르다면 left_on, right_on 인수를 사용하여 기준열을 명시해야 한다.
df1 = pd.DataFrame({
'이름': ['영희', '철수', '철수'],
'성적': [1, 2, 3]})
df1
df2 = pd.DataFrame({
'성명': ['영희', '영희', '철수'],
'성적2': [4, 5, 6]})
df2
pd.merge(df1, df2, left_on='이름', right_on="성명")
일반 데이터 열이 아닌 인덱스를 기준열로 사용하려면 left_index 또는 right_index 인수를 True 로 설정한다.
df1 = pd.DataFrame({
'도시': ['서울', '서울', '서울', '부산', '부산'],
'연도': [2000, 2005, 2010, 2000, 2005],
'인구': [9853972, 9762546, 9631482, 3655437, 3512547]})
df1
df2 = pd.DataFrame(
np.arange(12).reshape((6, 2)),
index=[['부산', '부산', '서울', '서울', '서울', '서울'],
[2000, 2005, 2000, 2005, 2010, 2015]],
columns=['데이터1', '데이터2'])
df2
pd.merge(df1, df2, left_on=['도시', '연도'], right_index=True)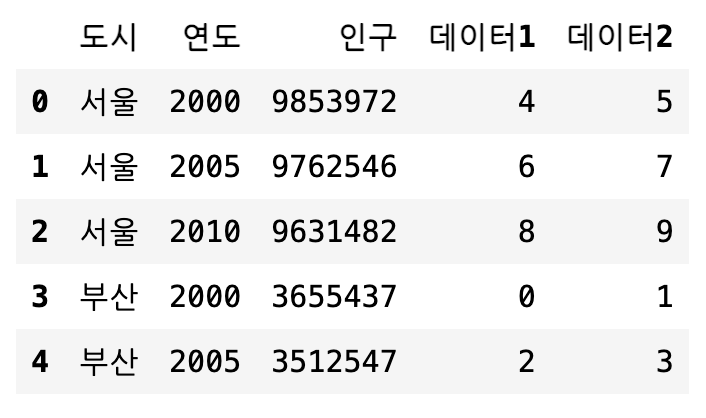
df1 = pd.DataFrame(
[[1., 2.], [3., 4.], [5., 6.]],
index=['a', 'c', 'e'],
columns=['서울', '부산'])
df1
df2 = pd.DataFrame(
[[7., 8.], [9., 10.], [11., 12.], [13, 14]],
index=['b', 'c', 'd', 'e'],
columns=['대구', '광주'])
df2
pd.merge(df1, df2, how='outer', left_index=True, right_index=True)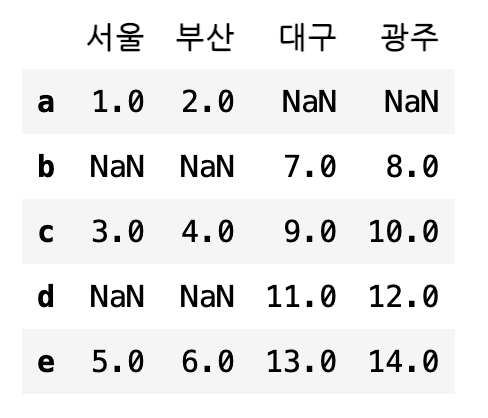
join 메서드
df1.join(df2, how='outer')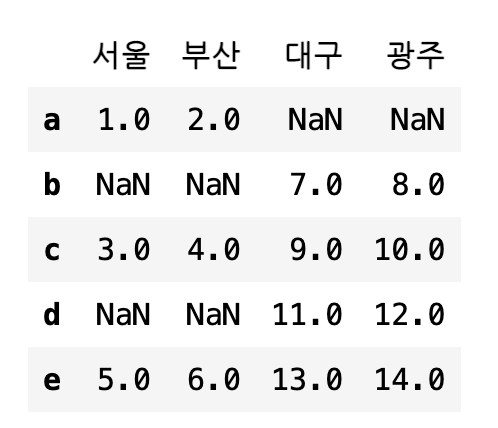
concat 함수를 사용한 데이터 연결
concat 함수를 사용하면 기준 열 (key column)을 사용하지 않고 단순히 데이터를 연결 (concatenate)한다. 기본적으로는 위 / 아래로 데이터 행을 연결한다. 단순히 두 시리즈나 데이터프레임을 연결하기 때문에 인덱스 값이 중복될 수 있다.
s1 = pd.Series([0, 1], index=['A', 'B'])
s2 = pd.Series([2, 3, 4], index=['A', 'B', 'C'])
s1
---
A 0
B 1
dtype: int64
s2
---
A 2
B 3
C 4
dtype: int64
pd.concat([s1, s2])
---
A 0
B 1
A 2
B 3
C 4
dtype: int64
옆으로 데이터 열을 연결하고 싶으면 axis=1로 인수를 설정한다.
df1 = pd.DataFrame(
np.arange(6).reshape(3, 2),
index=['a', 'b', 'c'],
columns=['데이터1', '데이터2'])
df1
df2 = pd.DataFrame(
5 + np.arange(4).reshape(2, 2),
index=['a', 'c'],
columns=['데이터3', '데이터4'])
df2

pd.concat([df1, df2], axis=1)
4.6 데이터프레임 합성 — 데이터 사이언스 스쿨
.ipynb .pdf to have style consistency -->
datascienceschool.net
'Python Library > Pandas' 카테고리의 다른 글
| [Pandas] 시계열 자료 다루기 (0) | 2022.02.22 |
|---|---|
| [Pandas] 피봇테이블과 그룹분석 (0) | 2022.02.22 |
| [Pandas] 데이터프레임 인덱스 조작 (0) | 2022.02.16 |
| [Pandas] 데이터프레임의 데이터 조작 (0) | 2022.02.16 |
| [Pandas] 데이터프레임 고급 인덱싱 (0) | 2022.02.15 |



