피봇테이블
피봇테이블 (pivot table)이란 데이터 열 중에서 두 개의 열을 각각 행 인덱스, 열 인덱스로 사용하여 데이터를 조회하여 펼쳐놓은 것을 말한다.
pandas는 피봇테이블을 만들기 위한 pivot 메서드를 제공한다. 첫번째 인수로는 행 인덱스로 사용할 열 이름, 두번째 인수로는 열 인덱스로 사용할 열 이름, 그리고 마지막으로 데이터로 사용할 열 이름을 넣는다.
pandas는 지정된 두 열을 각각 행 인덱스와 열 인덱스로 바꾼 후 행 인덱스의 라벨 값이 첫번째 키의 값과 같고 열 인덱스의 라벨 값이 두번째 키의 값과 같은 데이터를 찾아서 해당 칸에 넣는다. 만약 주어진 데이터가 존재하지 않으면 해당 칸에 NaN 값을 넣는다.
data = {
"도시": ["서울", "서울", "서울", "부산", "부산", "부산", "인천", "인천"],
"연도": ["2015", "2010", "2005", "2015", "2010", "2005", "2015", "2010"],
"인구": [9904312, 9631482, 9762546, 3448737, 3393191, 3512547, 2890451, 263203],
"지역": ["수도권", "수도권", "수도권", "경상권", "경상권", "경상권", "수도권", "수도권"]
}
columns = ["도시", "연도", "인구", "지역"]
df1 = pd.DataFrame(data, columns=columns)
df1
도시 이름이 열 인덱스가 되고 연도가 행 인덱스가 되어 행과 열 인덱스만 보면 어떤 도시의 어떤 시점의 인구를 쉽게 알 수 있도록 피봇테이블로 만들어보자. pivot 명령으로 사용하고 행 인덱스 인수로는 "도시", 열 인덱스 인수로는 "연도", 데이터 이름으로 "인구"를 입력하면 된다.
df1.pivot("도시", "연도", "인구")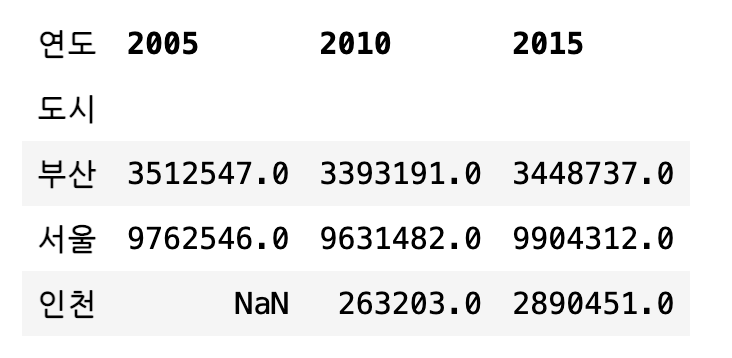
피봇테이블의 값 3512547은 “도시”가 부산이고 “연도”가 2005년인 데이터를 “인구”열에서 찾은 값이다. 2005년 인천의 인구는 데이터에 없기 때문에 NaN으로 표시된다.
피봇테이블은 다음과 같이 set_index 명령과 unstack 명령을 사용해서 만들 수도 있다.
df1.set_index(["도시", "연도"])[["인구"]].unstack()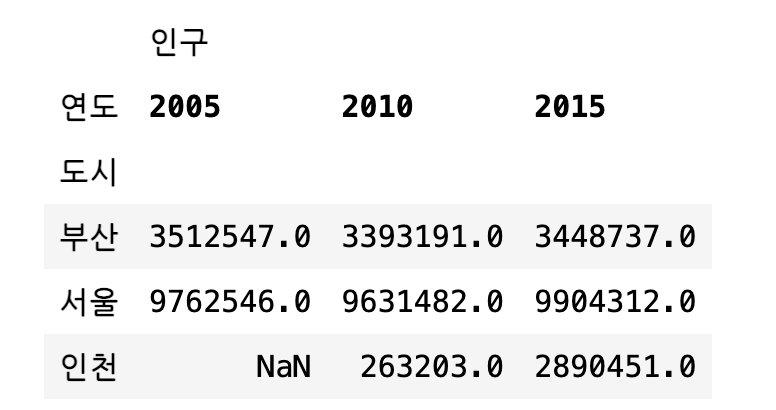
행 인덱스나 열 인덱스를 리스트로 주는 경우에는 다중 인덱스 피봇 테이블을 생성한다. (주의 : pandas 버전 1.1 미만에서는 버그로 인해 동작하지 않는다.)
df1.pivot(["지역", "도시"], "연도", "인구")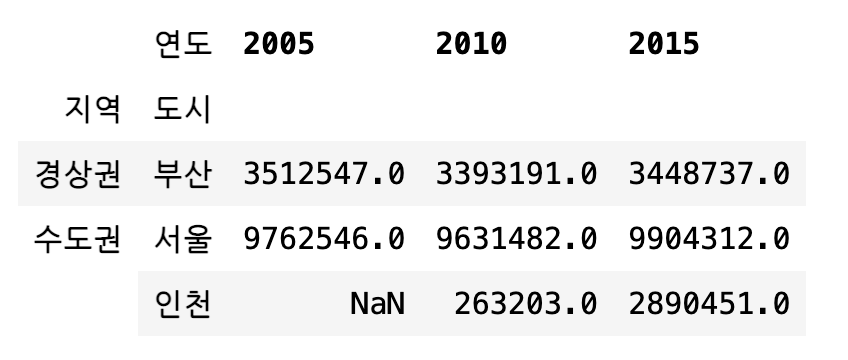
행 인덱스와 열 인덱스는 데이터를 찾는 키 (key)의 역할을 한다. 따라서 키 값으로 데이터가 단 하나만 찾아져야 한다. 만약 행 인덱스와 열 인덱스 조건을 만족하는 데이터가 2개 이상인 경우에는 에러가 발생한다. 예를 들어 위 데이터프레임에서 (“지역”, “연도”)를 키로 하면 (“수도권”, “2015”)에 해당하는 값이 두 개 이상이므로 다음과 같이 에러가 발생한다.
try:
df1.pivot("지역", "연도", "인구")
except ValueError as e:
print("ValueError:", e)
--> ValueError: Index contains duplicate entries, cannot reshape
그룹분석
만약 키가 지정하는 조건에 맞는 데이터가 하나 이상이라서 데이터 그룹을 이루는 경우에는 그룹의 특성을 보여주는 그룹분석 (group analysis)을 해야 한다.
그룹분석은 피봇테이블과 달리 키에 의해서 결정되는 데이터가 여러개가 있을 경우 미리 지정한 연산을 통해 그 그룹 데이터의 대표값을 계산한다. 판다스에서는 groupby 메서드를 사용하여 다음처럼 그룹분석을 한다.
|
groupby 메서드
groupby 메서드는 데이터를 그룹 별로 분류하는 역할을 한다. groupby 메서드의 인수로는 다음과 같은 값을 사용한다.
|
연산 결과로 그룹 데이터를 나타내는 GroupBy 클래스 객체를 반환한다. 이 객체에는 그룹별로 연산을 할 수 있는 그룹연산 메서드가 있다.
그룹연산 메서드
groupby 결과, 즉 GroupBy 클래스 객체의 뒤에 붙일 수 있는 그룹연산 메서드는 다양하다. 다음은 자주 사용되는 그룹연산 메서드들이다.
|
|
np.random.seed(0) # key1의 값 (A 또는 B)에 따른 data1의 평균 구하기
df2 = pd.DataFrame({
'key1': ['A', 'A', 'B', 'B', 'A'],
'key2': ['one', 'two', 'one', 'two', 'one'],
'data1': [1, 2, 3, 4, 5],
'data2': [10, 20, 30, 40, 50]
})
df2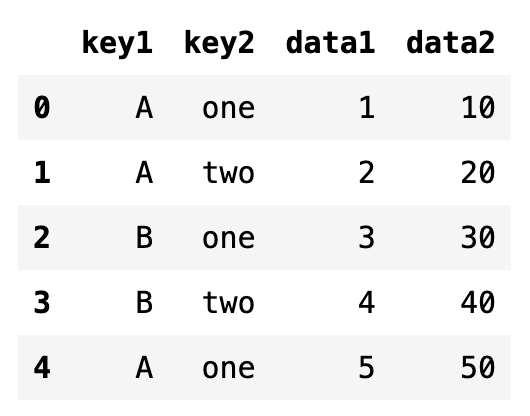
groupby 명령을 사용하여 그룹 A와 그룹 B로 구분한 그룹 데이터를 만든다.
groups = df2.groupby(df2.key1)
groups
--> <pandas.core.groupby.generic.DataFrameGroupBy object at 0x7fc4910a00d0>
GroupBy 클래스 객체에는 각 그룹 데이터의 인덱스를 저장한 groups 속성이 있다.
groups.groups
--> {'A': [0, 1, 4], 'B': [2, 3]}
A그룹과 B그룹 데이터의 합계를 구하기 위해 sum이라는 그룹연산을 한다.
groups.sum()
GroupBy 클래스 객체를 명시적으로 얻을 필요가 없다면 groupby 메서드와 그룹연산 메서드를 연속으로 호출한다. 다음 예제는 열 data1에 대해서만 그룹연산을 하는 코드이다.
df2.data1.groupby(df2.key1).sum()
---
key1
A 8
B 7
Name: data1, dtype: int64
데이터를 그룹으로 나눈 GroupBy 클래스 객체 또는 그룹분석한 결과에서 data1만 뽑아도 된다.
df2.groupby(df2.key1)["data1"].sum() # `GroupBy` 클래스 객체에서 data1만 선택하여 분석하는 경우
---
key1
A 8
B 7
Name: data1, dtype: int64
df2.groupby(df2.key1).sum()["data1"] # 전체 데이터를 분석한 후 data1만 선택한 경우
---
key1
A 8
B 7
Name: data1, dtype: int64
복합 키 (key1, key2) 값에 따른 data1의 합계를 구하자. 분석하고자 하는 키가 복수이면 리스트를 사용한다.
df2.data1.groupby([df2.key1, df2.key2]).sum()
---
key1 key2
A one 6
two 2
B one 3
two 4
Name: data1, dtype: int64
unstack 명령으로 피봇 데이블 형태로 만들수도 있다.
df2.data1.groupby([df2["key1"], df2["key2"]]).sum().unstack("key2")
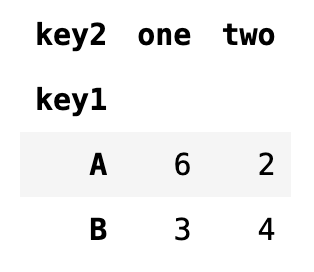
pivot_table
pandas는 pivot 명령과 groupby 명령의 중간 성격을 가지는 pivot_table 명령도 제공한다.
pivot_table 명령은 groupby 명령처럼 그룹분석을 하지만 최종적으로는 pivot 명령처럼 피봇테이블을 만든다. 즉 groupby 명령의 결과에 unstack을 자동 적용하여 2차원적인 형태로 변형한다.
|
df1.pivot_table("인구", "도시", "연도")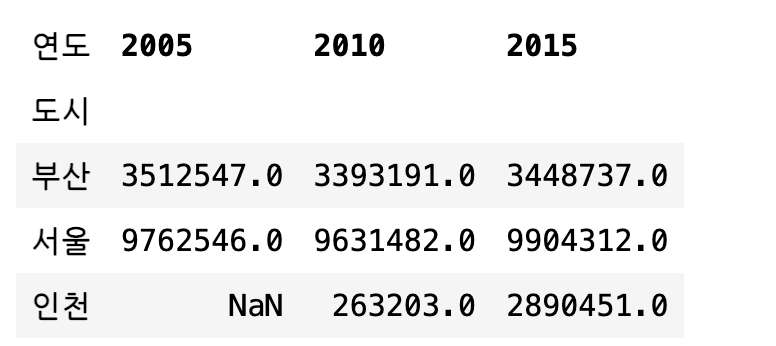
4.7 피봇테이블과 그룹분석 — 데이터 사이언스 스쿨
.ipynb .pdf to have style consistency -->
datascienceschool.net
'Python Library > Pandas' 카테고리의 다른 글
| [Pandas] 데이터프레임 모든 행, 열 출력 (0) | 2022.05.12 |
|---|---|
| [Pandas] 시계열 자료 다루기 (0) | 2022.02.22 |
| [Pandas] 데이터프레임 합성 (0) | 2022.02.21 |
| [Pandas] 데이터프레임 인덱스 조작 (0) | 2022.02.16 |
| [Pandas] 데이터프레임의 데이터 조작 (0) | 2022.02.16 |



