인덱싱 (indexing)
데이터프레임에서 특정한 데이터만 골라내는 것을 인덱싱 (indexing)이라고 한다. 앞 절에서는 label, label 리스트, 인덱스 데이터 (정수) 슬라이스의 3가지 인덱싱 값을 사용하여 인덱싱한다. 그런데 Pandas는 numpy 행렬과 같이 쉼표를 사용한 (행 인덱스, 열 인덱스) 형식의 2차원 인덱싱을 지원하기 위해 특별한 인덱서 (indexer) 속성도 제공한다.
loc 인덱서
df.loc[행 인덱싱값]
# 또는
df.loc[행 인덱싱값, 열 인덱싱값]
행 인덱싱값은 정수 또는 행 인덱스데이터이고 열 인덱싱값은 label 문자열이다.
|
df = pd.DataFrame(np.arange(10, 22).reshape(3, 4),
index=["a", "b", "c"],
columns=["A", "B", "C", "D"])
df
인덱싱 값을 하나만 받는 경우
loc 인덱서를 사용하면서 인덱스를 하나만 넣으면 행 (row)을 선택한다.
df.loc["a"]
---
A 10
B 11
C 12
D 13
Name: a, dtype: int64
인덱스 데이터의 슬라이스도 가능하다.
df.loc["b":"c"]
df["b":"c"] # loc를 쓰지 않는 경우
df.loc[["b", "c"]] # 인덱스 데이터의 리스트
df.A > 15 # 데이터 베이스와 같은 인덱스를 가지는 boolean 시리즈도 행을 선택하는 인덱싱값으로 쓸 수 있다.
---
a False
b False
c True
Name: A, dtype: booldf.loc[df.A > 15]
def select_rows(df): # 인덱스 대신 인덱스 값을 반환하는 함수를 사용할 수도 있다. 함수는 A열의 값이 12보다 큰 행만 선택한다.
return df.A > 15
select_rows(df)
---
a False
b False
c True
Name: A, dtype: bool
df.loc[select_rows(df)]
loc 인덱서가 없는 경우에 사용했던 label 인덱싱이나 label 리스트 인덱싱은 불가능하다.
# df.loc["A"] # KeyError
# df.loc[["A", "B"]] # KeyError
원래 (행) 인덱스값이 정수인 경우에는 슬라이싱도 label 슬라이싱 방식을 따르게 된다. 즉, 슬라이스의 마지막 값이 포함된다.
df2 = pd.DataFrame(np.arange(10, 26).reshape(4, 4), columns=["A", "B", "C", "D"])
df2
df2.loc[1:2]

인덱싱 값을 행과 열 모두 받는 경우
인덱싱값을 행과 열 모두 받으려면 df.loc[행 인덱스, 열 인덱스]와 같은 형태로 사용한다. 행 인덱스 라벨값이 a, 열 인덱스 라벨값이 A인 위치의 값을 구하자.
df.loc["a", "A"]
--> 10
인덱싱값으로 label 데이터의 슬라이싱 또는 리스트를 사용할 수도 있다.
df.loc["b":, "A"]
---
b 14
c 18
Name: A, dtype: int64
df.loc["a", :]
---
A 10
B 11
C 12
D 13
Name: a, dtype: int64
df.loc[["a", "b"], ["B", "D"]]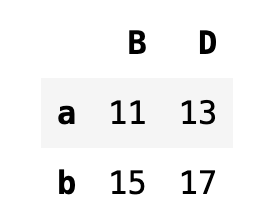
행 인덱스가 같은 boolean 시리즈나 이러한 boolean 시리즈를 반환하는 함수도 행의 인덱싱값이 될 수 있다.
df.loc[df.A > 10, ["C", "D"]]
iloc 인덱서
iloc 인덱서는 loc 인덱서와 반대로 label이 아니라 순서를 나타내는 정수 (integer) 인덱스만 받는다. 다른 사항은 loc 인덱서와 같다.
df.iloc[0, 1]
--> 11
df.iloc[:2, 2]
---
a 12
b 16
Name: C, dtype: int64
df.iloc[0, -2:]
---
C 12
D 13
Name: a, dtype: int64
df.iloc[2:3, 1:3]
loc 인덱서와 마찬가지로 인덱스가 하나만 들어가면 행을 선택한다.
df.iloc[-1]
---
A 18
B 19
C 20
D 21
Name: c, dtype: int64
df.iloc[-1] = df.iloc[-1] * 2
df
4.3 데이터프레임 고급 인덱싱 — 데이터 사이언스 스쿨
.ipynb .pdf to have style consistency -->
datascienceschool.net
'Python Library > Pandas' 카테고리의 다른 글
| [Pandas] 데이터프레임 인덱스 조작 (0) | 2022.02.16 |
|---|---|
| [Pandas] 데이터프레임의 데이터 조작 (0) | 2022.02.16 |
| [Pandas] 데이터 입출력 (0) | 2022.02.15 |
| [Pandas] 데이터프레임 (DataFrame) (0) | 2022.02.15 |
| [Pandas] 시리즈 (Series) (2) (0) | 2022.02.15 |



