데이터프레임 (DataFrame)
시리즈가 1차원 벡터 데이터에 행방향 인덱스 (row index)를 붙인 것이라면 데이터프레임 DataFrame 클래스는 2차원 행렬 데이터에 인덱스를 붙인 것과 비슷하다. 2차원이므로 각각의 행 데이터의 이름이 되는 행 인덱스 (row index) 뿐 아니라 각각의 열 데이터의 이름이 되는 열 인덱스 (column index)도 붙일 수 있다.
데이터프레임 생성
|
data = {
"2015": [9904312, 3448737, 2890451, 2466052],
"2010": [9631482, 3393191, 2632035, 2431774],
"2005": [9762546, 3512547, 2517680, 2456016],
"2000": [9853972, 3655437, 2466338, 2473990],
"지역": ["수도권", "경상권", "수도권", "경상권"],
"2010-2015 증가율": [0.0283, 0.0163, 0.0982, 0.0141]
}
columns = ["지역", "2015", "2010", "2005", "2000", "2010-2015 증가율"]
index = ["서울", "부산", "인천", "대구"]
df = pd.DataFrame(data, index=index, columns=columns)
df

데이터프레임은 2차원 배열 데이터를 기반으로 한다고 했지만 사실은 공통 인덱스를 가지는 열 시리즈 (column series)를 딕셔너리로 묶어놓은 것이라고 보는 것이 더 정확하다. 2차원 배열 데이터는 모든 원소가 같은 자료형을 가져야 하지만 데이터프레임은 각 열 (column)마다 자료형이 다를 수 있기 때문이다. 위 예제에서도 지역과 인구와 증가율은 각각 문자열, 정수, 부동소수점 실수이다.
시리즈와 마찬가지로 데이터만 접근하려면 values 속성을 사용한다. 열방향 인덱스와 행방향 인덱스는 각각 columns, index 속성으로 접근한다.
df.values
---
array([['수도권', 9904312, 9631482, 9762546, 9853972, 0.0283],
['경상권', 3448737, 3393191, 3512547, 3655437, 0.0163],
['수도권', 2890451, 2632035, 2517680, 2466338, 0.0982],
['경상권', 2466052, 2431774, 2456016, 2473990, 0.0141]], dtype=object)
df.columns
--> Index(['지역', '2015', '2010', '2005', '2000', '2010-2015 증가율'], dtype='object')
df.index
--> Index(['서울', '부산', '인천', '대구'], dtype='object')
시리즈에서 처럼 열방향 인덱스와 행방향 인덱스에 이름을 붙이는 것도 가능하다.
df.index.name = "도시"
df.columns.name = "특성"
df
데이터프레임은 전치 (transpose)를 포함하여 넘파이 2차원 배열이 가지는 대부분의 속성이나 메서드를 지원한다.

열 데이터의 갱신, 추가, 삭제
데이터프레임은 열 시리즈의 딕셔너리으로 볼 수 있으므로 열 단위로 데이터를 갱신하거나 추가, 삭제할 수 있다.
# "2010-2015 증가율"이라는 이름의 열 추가
df["2010-2015 증가율"] = df["2010-2015 증가율"] * 100
df
# "2005-2010 증가율"이라는 이름의 열 추가
df["2005-2010 증가율"] = ((df["2010"] - df["2005"]) / df["2005"] * 100).round(2)
df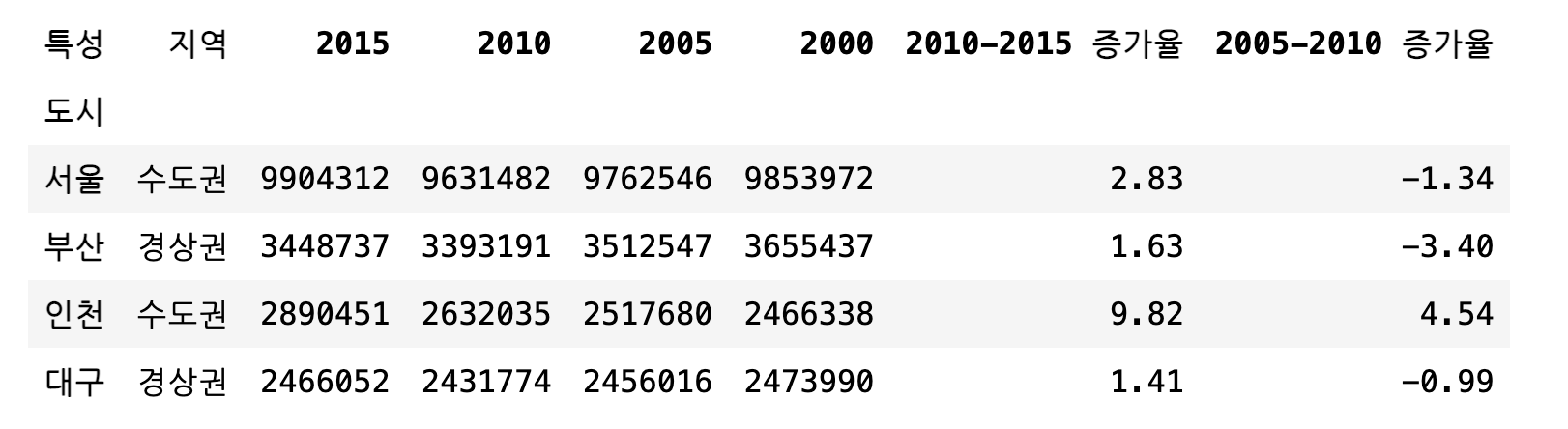
# "2010-2015 증가율"이라는 이름의 열 삭제
del df["2010-2015 증가율"]
df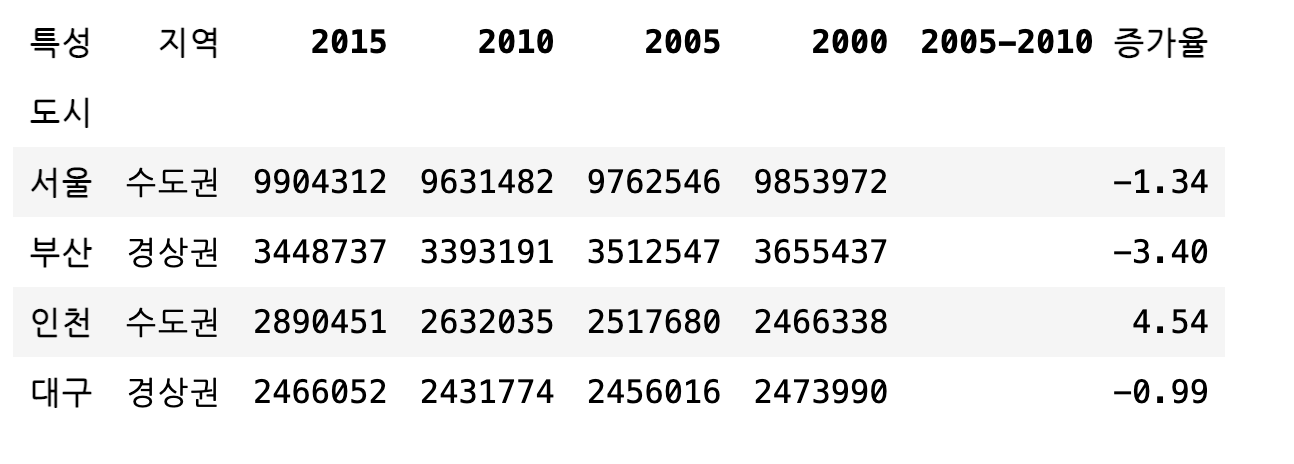
열 인덱싱
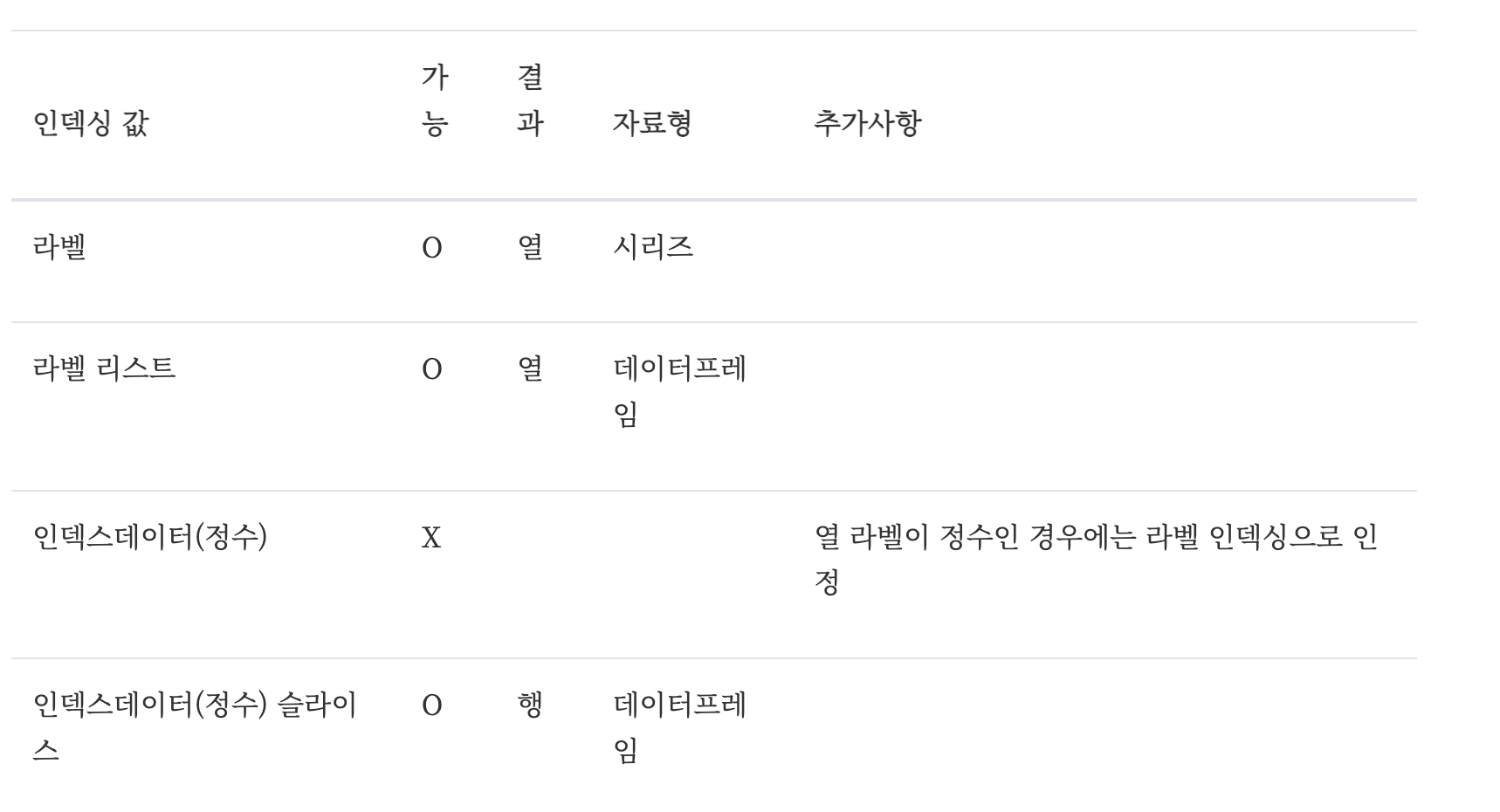
데이터프레임은 열 label을 키로, 열 시리즈를 값으로 가지는 딕셔너리와 비슷하다. 따라서 데이터프레임을 인덱싱을 할 때도 열 라벨 (column label)을 키값으로 생각하여 인덱싱을 할 수 있다. 인덱스로 label 값을 하나만 넣으면 시리즈 객체가 반환되고 label의 배열 또는 리스트를 넣으면 부분적인 데이터프레임이 반환된다.
# 하나의 열만 인덱싱하면 시리즈가 반환된다.
df["지역"]
---
도시
서울 수도권
부산 경상권
인천 수도권
대구 경상권
Name: 지역, dtype: object# 여러개의 열을 인덱싱하면 부분적인 데이터프레임이 반환된다.
df[["2010", "2015"]]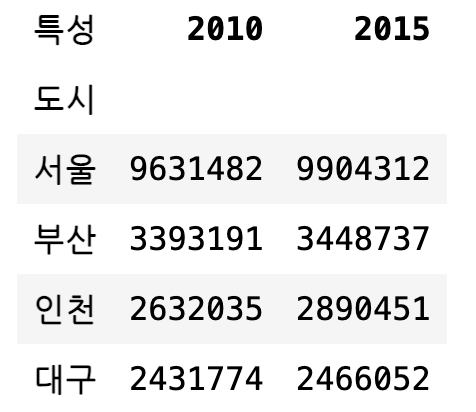
만약 하나의 열만 빼내면서 데이터프레임 자료형을 유지하고 싶다면 원소가 하나인 리스트를 써서 인덱싱하면 된다.
# 2010이라는 열을 반환하면서 데이터프레임 자료형을 유지
df[["2010"]]
type(df[["2010"]])
--> pandas.core.frame.DataFrame
# 2010이라는 열을 반환하면서 시리즈 자료형으로 변환
df["2010"]
---
도시
서울 9631482
부산 3393191
인천 2632035
대구 2431774
Name: 2010, dtype: int64
type(df["2010"])
--> pandas.core.series.Series
데이터프레임의 열 인덱스가 문자열 라벨을 가지고 있는 경우에는 순서를 나타내는 정수 인덱스를 열 인덱싱에 사용할 수 없다. 정수 인덱싱의 슬라이스는 뒤에서 설명하겠지만 행 (row)을 인덱싱할 때 사용하므로 열을 인덱싱할 때는 쓸 수 없다. 정수 인덱스를 넣으면 KeyError 오류가 발생하는 것을 볼 수 있다.
df[0]
...(생략)...
Key Error 0
다만 원래부터 문자열이 아닌 정수형 열 인덱스를 가지는 경우에는 인덱스 값으로 정수를 사용할 수 있다.
df2 = pd.DataFrame(np.arange(12).reshape(3, 4))
df2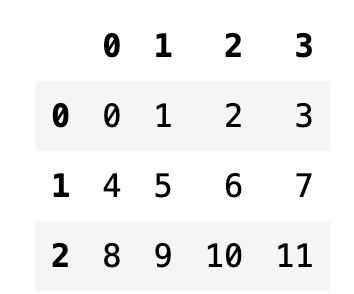
df2[2]
---
0 2
1 6
2 10
Name: 2, dtype: int64
df2[[1, 2]]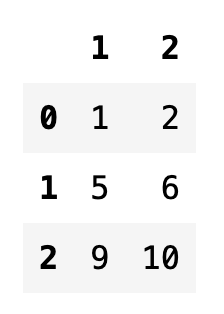
행 인덱싱
행 단위로 인덱싱을 하고자 하면 항상 슬라이싱 (slicing)을 해야 한다. 인덱스의 값이 문자 label이면 label 슬라이싱도 가능하다.
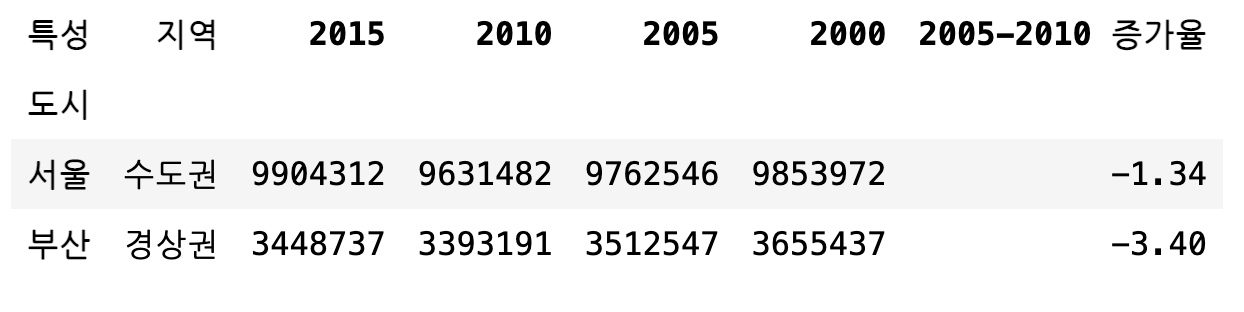
df[:1]

df[1:2]

df[1:3]
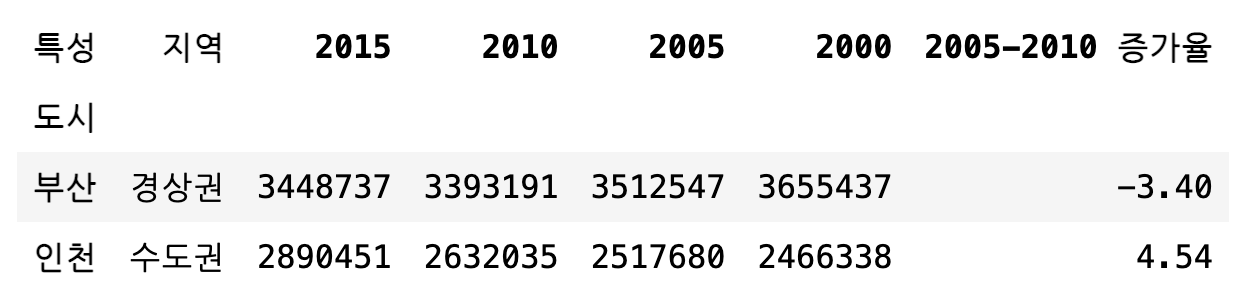
df["서울":"부산"]
개별 데이터 인덱싱
데이터프레임에서 열 label로 시리즈를 인덱싱하면 시리즈가 된다. 이 시리즈를 다시 행 label로 인덱싱하면 label 데이터가 나온다.
df["2015"]["서울"]
--> 9904312Conclusion
4.1 판다스 패키지의 소개 — 데이터 사이언스 스쿨
.ipynb .pdf to have style consistency -->
datascienceschool.net
'Python Library > Pandas' 카테고리의 다른 글
| [Pandas] 데이터프레임 고급 인덱싱 (0) | 2022.02.15 |
|---|---|
| [Pandas] 데이터 입출력 (0) | 2022.02.15 |
| [Pandas] 시리즈 (Series) (2) (0) | 2022.02.15 |
| [Pandas] 시리즈 (Series) (1) (0) | 2022.02.15 |
| 판다스 (Pandas) (0) | 2022.02.15 |



