EEG 데이터의 시간적 차원에 기계 학습 방법 적용
이전 사례인 단일 참가자 분석 및 그룹 수준 분석에서와 동일한 EEG 데이터에 분류를 적용하지만 데이터의 시간적 차원을 활용한다.
단일 참가자 분석 및 그룹 수준 분석에서 다른 자극에 대한 EEG 반응을 분류할 수 있는지 여부를 조사했다. 그러나 분류는 시간에 구애받지 않았다. 그것은 단지 뇌의 어딘가, 특정 시점에 다른 자극 (확인하기 위해)에 대해 차등적인 EEG 반응이 있다는 것을 알렸다.
|
이러한 질문에 답하기 위해 단일 참여자 분석 및 그룹 수준 분석에서와 동일한 알고리즘을 사용 하지만 이번에는 각 시간 인스턴스에서 하나의 분류기를 훈련하고 모델의 성능을 평가한다. (새로운 epoch의 각 시간 instance에서)
이를 위해 MNE 패키지의 SlidingEstimator 기능이 제공된다. 이것은 모델과 선택적으로 스코어링 기능을 매개변수로 사용하여 시점 분류기로 시점을 생성한다. 슬라이딩 추정기를 생성한 후 데이터에 맞추거나 각 작업에 대해 추정기를 채점하거나 새로운 시대에 대한 예측을 수행할 수 있다.
# To silence the warnings
def warn(*args, **kwargs):
pass
import warnings
warnings.warn = warn
import mne
from mne.decoding import SlidingEstimator, cross_val_multiscore
from mne.decoding import Vectorizer
from os.path import isfile, join
from os import listdir
import numpy as np
import statistics
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import cross_val_score, train_test_split, GridSearchCV, StratifiedKFold
from sklearn.metrics import precision_recall_fscore_support, accuracy_score
# Models
from sklearn import svm
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.linear_model import LogisticRegression
Analysis on temporal dimensions for each participant separately
- 분석을 위한 데이터 준비
data_folder = '../../study1/study1_eeg/epochdata/'
files = [data_folder+f for f in listdir(data_folder) if isfile(join(data_folder, f)) and '.DS_Store' not in f]
ids = [int(f[len(data_folder)+2:-4]) for f in files]
epochs = [mne.read_epochs(f, verbose='error') for f in files]
epochs_UN = [e['FU', 'FN'] for e in epochs]
epochs_UP = [e['FU', 'FP'] for e in epochs]
epochs_NP = [e['FN', 'FP'] for e in epochs]
# Dataset with unpleasant and neutral events
data_UN = [e.get_data() for e in epochs_UN]
labels_UN = [e.events[:,-1] for e in epochs_UN]
data_UP = [e.get_data() for e in epochs_UP]
labels_UP = [e.events[:,-1] for e in epochs_UP]
data_NP = [e.get_data() for e in epochs_NP]
labels_NP = [e.events[:,-1] for e in epochs_NP]
각 참가자의 데이터에 대해 슬라이딩 윈도우 추정기로 분류기를 개별적으로 훈련시키고 3중 교차 검증을 적용한다.
def applyCrossValidation(data, labels, epochs, ids, classifier):
CV_score_time = None
sl = SlidingEstimator(classifier, scoring='accuracy')
if np.isfinite(data).all() == True and np.isnan(data).any() == False:
CV_score_time = cross_val_multiscore(sl, data, labels, cv=3)
plotCVScores(epochs.times, CV_score_time, ids)
else:
print('Input contains NaN or infinity!')
return CV_score_time
import matplotlib.pyplot as plt
%matplotlib inline
def plotCVScores(times, CV_score_time, id=None):
fig, ax = plt.subplots()
if id != None:
fig.suptitle('CV Scores of Participant-'+str(id))
else:
fig.suptitle('CV Scores')
ax.plot(times, CV_score_time.T)
plt.xlabel('Time')
plt.ylabel('CV Accuracy')
plt.show()
Classification Between Unplesant and Neutral Events
CV_score_time_UN = []
for i in range(len(data_UN)):
print('Participant id: '+ str(ids[i]))
clf = make_pipeline(Vectorizer(), StandardScaler(), LinearDiscriminantAnalysis(solver='svd'))
CV_score_time_UN.append(applyCrossValidation(data_UN[i], labels_UN[i], epochs_UN[i], ids[i], clf))Participant id: 15
[........................................] 100.00% Fitting SlidingEstimator |
[........................................] 100.00% Fitting SlidingEstimator |
[........................................] 100.00% Fitting SlidingEstimator |
Participant id: 1
[........................................] 100.00% Fitting SlidingEstimator |
[........................................] 100.00% Fitting SlidingEstimator |
[........................................] 100.00% Fitting SlidingEstimator |
Participant id: 14
[........................................] 100.00% Fitting SlidingEstimator |
[........................................] 100.00% Fitting SlidingEstimator |
[........................................] 100.00% Fitting SlidingEstimator |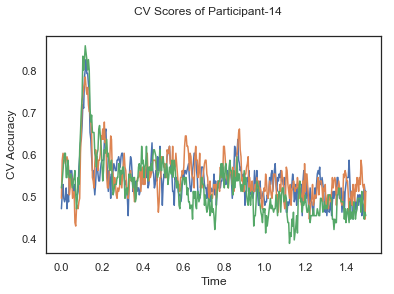
def averageCVScores(CV_score_time):
avg_cv_scores = []
for cv in CV_score_time:
avg_scores_tmp = []
sum_col_wise = cv.sum(axis=0)
avg_scores_tmp = [s/len(cv) for s in sum_col_wise]
avg_cv_scores.append(avg_scores_tmp)
return avg_cv_scores
avg_cv_score_time = averageCVScores(CV_score_time_UN)
아래의 평균 교차 검증 정확도 플롯은 각 시점에서 달성된 확률 (50%) 이상의 정확도를 보여준다.
avg_cv_score_time = np . asarray ( avg_cv_score_time )
plot_conditions ( avg_cv_score_time , epochs_UN , labels_UN )
Classication over time
Classication over time Tutorial #6: Applying Machine Learning Methods to Temporal Dimensions of EEG Data In this tutorial, we will apply classific...
neuro.inf.unibe.ch
'Brain Engineering > MNE' 카테고리의 다른 글
| 전력 스펙트럼 밀도 (Power Spectral Density) (0) | 2022.08.06 |
|---|---|
| Machine Learning : Classication over time (2) (0) | 2022.04.06 |
| Machine Learning : Group-Level Analysis (Part - 2) (3) (0) | 2022.04.05 |
| Machine Learning : Group-Level Analysis (Part - 1) (2) (0) | 2022.04.05 |
| Machine Learning : Group-Level Analysis (Part - 1) (1) (0) | 2022.04.05 |



