728x90
반응형
SMALL
Example #2 : Classification between Unpleasant and Neutral Events
불쾌한 사건과 중립적인 사건 사이의 분류 작업에 첫 번째 예의 동일한 단계가 적용된다.
results_perParticipant_UN = []
model_names = [ 'LR', 'LDA']
kfold = StratifiedKFold(n_splits=3, random_state=42)
for i in range(len(ids)):
# Linear Discriminant Analysis
clf_lda_pip = make_pipeline(Vectorizer(), StandardScaler(), LinearDiscriminantAnalysis(solver='svd'))
#Logistic Regression
clf_lr_pip = make_pipeline(Vectorizer(), StandardScaler(), LogisticRegression(penalty='l1', random_state=42))
models = [ clf_lr_pip, clf_lda_pip]
scores = applyCrossValidation(models, model_names, data_UN[i], labels_UN[i], kfold)
results_perParticipant_UN.append(list(scores))
avg_results_perParticipant_UN = calculateAvgResults(model_names, results_perParticipant_UN)
#sort ids results together to plot nicely.
ids_sorted, avg_results_perParticipant_UN = zip(*sorted(zip(ids, avg_results_perParticipant_UN)))
plotCVScores_perParticipant(ids_sorted, avg_results_perParticipant_UN, model_names)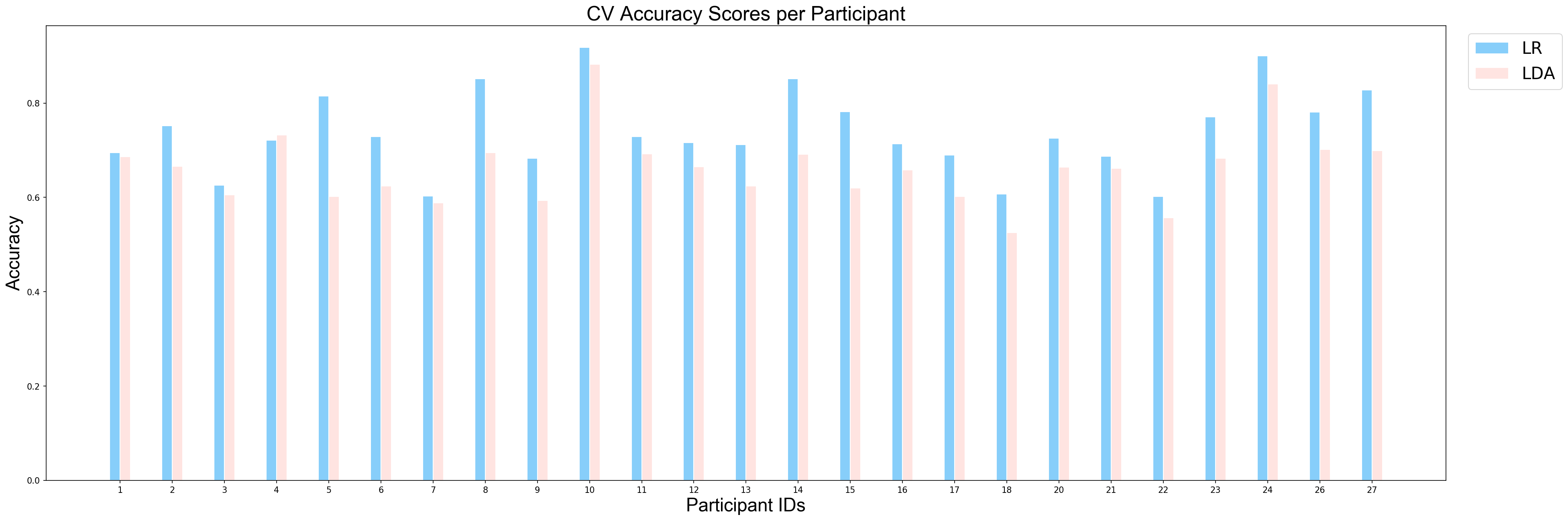
applyStatisticalTest(avg_results_perParticipant_UN, model_names)p = 1.570510001975002e-05 for Wilcoxon test between LR and LDA
첫 번째 예와 유사하게 파생된 p-값이 0.05보다 작기 때문에 불쾌한 사건과 중립적인 사건을 분류하는 작업에서 LDA의 성능과 Logistic Regression의 성능 사이에 상당한 차이가 있다는 결론을 내릴 수 있다. 따라서 이 작업에서도 로지스틱 회귀가 더 잘 수행되었다고 결론지을 수 있다.
Example #3 : Classification between Pleasant and Neutral Events
이 예에서 유쾌한 사건과 중립적인 사건 작업 사이의 이전 예 분류에서 동일한 단계를 따를 것이다.
results_perParticipant_NP = []
model_names = [ 'LR', 'LDA']
kfold = StratifiedKFold(n_splits=3, random_state=42)
for i in range(len(ids)):
# Linear Discriminant Analysis
clf_lda_pip = make_pipeline(Vectorizer(), StandardScaler(), LinearDiscriminantAnalysis(solver='svd'))
#Logistic Regression
clf_lr_pip = make_pipeline(Vectorizer(), StandardScaler(), LogisticRegression(penalty='l1', random_state=42))
models = [ clf_lr_pip, clf_lda_pip]
scores = applyCrossValidation(models, model_names, data_NP[i], labels_NP[i], kfold)
results_perParticipant_NP.append(list(scores))
avg_results_perParticipant_NP = calculateAvgResults(model_names, results_perParticipant_NP)
#sort ids results together to plot nicely.
ids_sorted, avg_results_perParticipant_NP = zip(*sorted(zip(ids, avg_results_perParticipant_NP)))
plotCVScores_perParticipant(ids_sorted, avg_results_perParticipant_NP, model_names)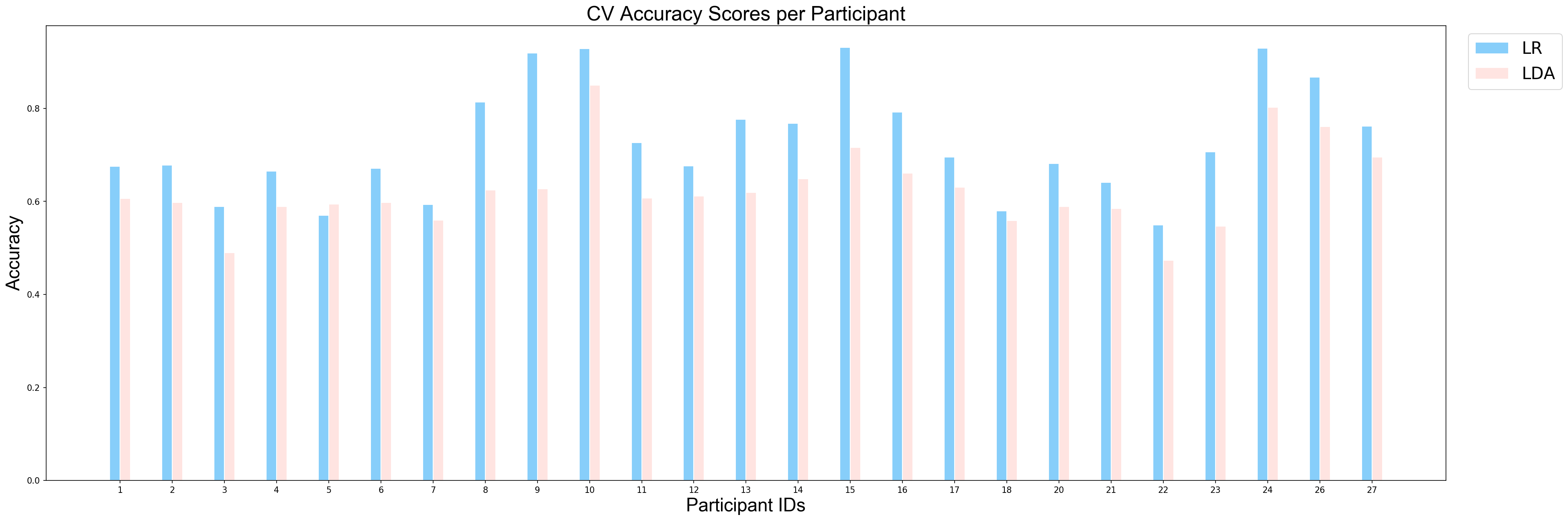
applyStatisticalTest(avg_results_perParticipant_NP, model_names)p = 1.570510001975002e-05 for Wilcoxon test between LR and LDA
Group-Level Analysis
Group-Level Analysis Tutorial #5: Applying Machine Learning Methods to EEG Data on Group Level In this tutorial, we are performing the same classi...
neuro.inf.unibe.ch
728x90
반응형
LIST
'Brain Engineering > MNE' 카테고리의 다른 글
| Machine Learning : Classication over time (1) (0) | 2022.04.05 |
|---|---|
| Machine Learning : Group-Level Analysis (Part - 2) (3) (0) | 2022.04.05 |
| Machine Learning : Group-Level Analysis (Part - 1) (1) (0) | 2022.04.05 |
| Machine Learning : Single-Participant Analysis (2) (0) | 2022.04.05 |
| Machine Learning : Single-Participant Analysis (1) (0) | 2022.04.05 |



