이미지 대 이미지 변환
GAN 어플리케이션 분야 중 하나는 이미지 대 이미지 변환이다. 비디오, 이미지는 물론 앞서 설명한 Style Transfer에서도 GAN이 엄청난 성공을 거두었다. 실제로 GAN은 새로운 종류의 애플리케이션을 가능하게 하기 때문에 딥러닝 연구에서의 선두에 있다. 시각적 효과가 두드러진 탓에 성공한 GAN 모델은 유튜브와 트위터 등 SNS에 많이 등장한다.
이런 종류의 변환을 구현하려면 생성자의 입력이 사진이어야 한다. 생성자가 이미지에서부터 시작하기 때문이다. 다른 말로 하면, 한 도메인의 이미지를 다른 도메인의 이미지로 매핑한다. 이전에 생성자에게 주입한 잠재 벡터는 해석이 불가능했다. 이제, 이 벡터를 입력 영상으로 대체한다.
CycleGAN (Cycle-Consistent adversarial network)은 Style Transfer 분야에서 핵심적인 발전 중 하나인 모델이다. 이것은 Style transfer 분야에서 큰 진전을 이루어낸 것으로 평가된다. 샘플 쌍으로 구성된 훈련 세트 없이도 참조 이미지 세트의 스타일을 다른 영상으로 복사하는 모델을 훈련할 수 있는 방법을 보인다.
Pix2Pix

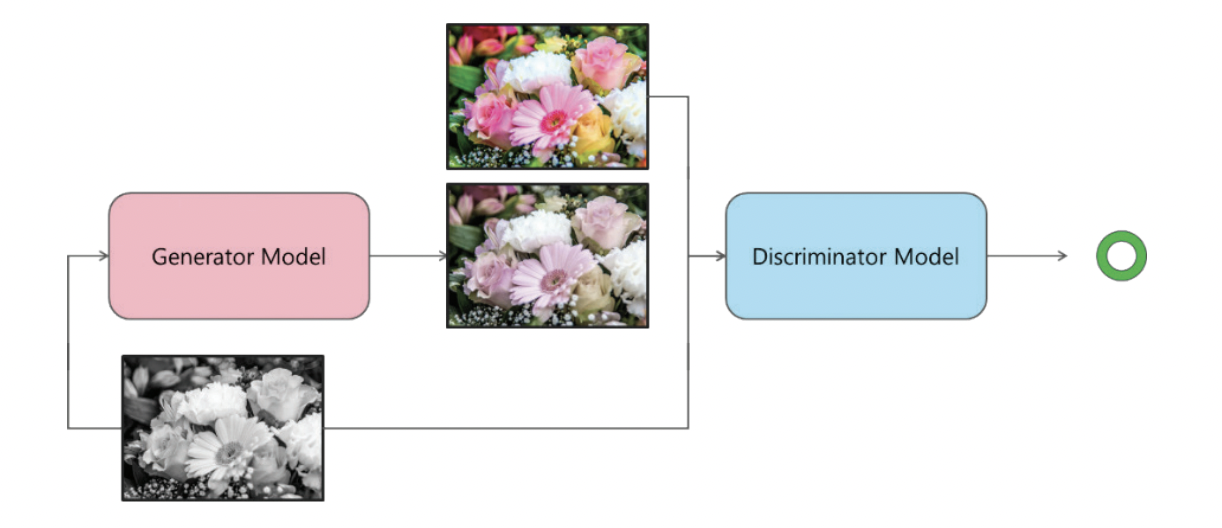
Pix2pix 모델은 입력 이미지를 다른 도메인의 출력 이미지로 대응시켜주는 신경망으로 conditional GAN에 기반을 둔 image-to-image translation 모델이다. 아주 포괄적인 상황에서도 사용이 가능하다는 장점이 있다.

Generator(G)는 소스 도메인의 데이터를 입력 받아 타겟 도메인의 데이터를 생성한다. G는 소스 도메인의 데이터와 생성된 타겟 도메인의 데이터를 쌍으로 묶어 D에 전달한다. Discriminator(D)는 G가 생성한 가짜 데이터 쌍과 실제 데이터 쌍을 구분한다. G는 D를 속이도록 하는 과정에서 데이터를 더 잘 생성하게 된다.

G는 오토인코더 (autoencoder)에 U-net을 결합한 아키텍처를 썼다고 한다. encoder, decoder 사이에 발생할 수 있는 정보 손실을 skip-connection을 이용해 완화한 것이다.
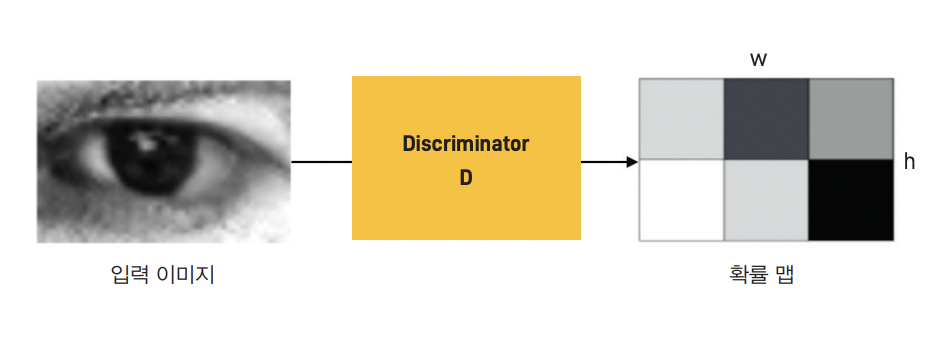
Pix2Pix의 판별자는 SimGAN의 Local patch-Discriminator를 사용하였다. 기존 GAN에서 D는 입력 데이터 전체를 보고 real/fake 여부를 판별한다. 이 때문에 G는 대개 D를 속이기 위해 데이터의 일부 특징을 과장하려는 경향이 있다.
이 문제를 완화하기 위해 다음 그림과 같이 D가 데이터의 일부 영역만 보도록 하고, 전체적인 판단은 이들 패치의 평균이나 가중 합의 방식으로 취하도록 했다. 그 결과, D의 능력을 어느 정도 제한하면서 G의 성능을 높일 수 있었다.
CycleGAN
Pix2Pix의 단점은 훈련 세트의 각 이미지가 소스와 타깃 도메인에 모두 존재해야 한다. 스타일 관련 문제를 위해 이런 종류의 데이터셋 (ex. 지도와 위성 사진)을 만들 수 있지만 불가능한 경우도 있다. Pix2Pix 이외에도 CGAN 등 이미지 대 이미지 변환을 위해 제작되었던 모델들은 훈련하는 동안 원래 도메인의 아이템에 해당하는 레이블이 필요하다.
예를 들어, 흑백 영상의 경우 먼저 컬러 사진을 로드하여 흑백 필터를 적용한다. 그 다음 원본 이미지를 한 도메인으로 사용하고 흑백 필터를 적용한 이미지를 다른 도메인으로 사용한다. 이렇게 하면 양쪽 도메인에 모두 존재하는 이미지를 준비할 수 있다. 그 다음, 훈련된 GAN을 다른 곳에 적용할 수 있다. 하지만 이런 완벽한 쌍을 준비하기 쉽지가 않다.

CycleGAN은 이러한 문제를 해결하기 위해 제안됐다. 이를 도식적으로 나타낸 그림은 다음과 같다.

Pix2pix는 한 방향 (소스에서 타깃으로)으로만 작동하지만, CycleGAN은 양방향 (Cycle)으로 동시에 모델을 훈련한다. 따라서, 모델이 소스에서 타겟으로뿐만 아니라 타겟에서 소스로 이미지를 변환할 수 있다. 모델 구조로 인해 생긴 결과물이어서 반대 방향은 자동으로 얻을 수 있다.

예를 들어, 풍경의 여름 사진 (도메인 A)에서 겨울 사진 (도메인 B)으로 변환하고 다시 여름 사진 (도메인 A)으로 변환한다. 사이클을 구성했기 때문에 이상적으로는 원래 사진 (a)와 재구성된 사진 (a’)은 동일할 것이다. 두 사진이 동일하지 않다면 픽셀 수준에서 이 손실을 측정하여 CycleGAN의 첫 번째 손실값인 Cycle-Consistency Loss를 구한다.
이를 역번역 과정으로 생각할 수 있다. 영어로 번역한 한국어 문장을 다시 한국어로 번역하면 동일한 문장이 되어야 한다. 두 문장이 같지 않으면 첫 번째 문장과 세 번째 문장이 얼마나 차이가 나는지 사이클-일관성 손실 (Cycle Consistency)을 계산할 수 있다.
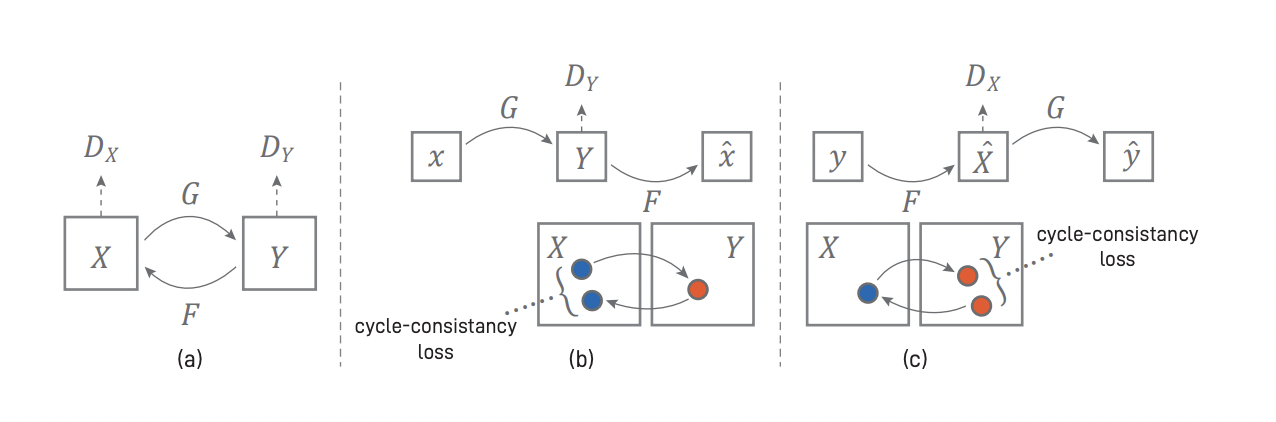
CycleGAN의 기본 구조는 다음과 같다. 두 개의 생성자 G, F와 두 개의 판별자 DX, DY를 쓴다. G는 X 도 메인의 데이터를 Y 도메인으로 변환하는 역할을 한다. F는 Y 도메인의 데이터를 X 도메인으로 변환한다. DX는 F가 생성한 가짜 데이터와 X 도메인의 실제 데이터를 구분한다. DY는 G가 생성한 가짜 데이 터와 Y 도메인의 실제 데이터를 구분한다. G와 F는 반대 도메인의 구분자를 속이도록 적대적으로 학습 된다. 이렇게 학습이 진행되면서 굳이 데이터가 pair 형태로 존재하지 않아도 된다.
CycleGAN에서 눈여겨 볼 손실 함수는 cycle-consistency loss뿐만 아니라 Identity loss도 있다. 이 아이디어는 간단하다. CycleGAN이 사진의 전반적인 색 구성 (또는 온도)을 유지하길 원한다. 이를 위해 사진의 색조가 원본 이미지와 일치하도록 regulariazation을 도입한다. 이미지에 여러 필터를 적용한 후에도 원본 이미지를 복원 가능하게 만드는 것으로 생각할 수 있다.

이를 위해 B에서 A로 변환하는 생성자에 도메인 A에 이미 있는 이미지를 주입한다. CycleGAN이 올바른 도메인에 있는 이미지를 이해해야 하기 때문이다. 다른 말로 하면, 이미지에 대한 불필요한 변경을 억제한다. 얼룩말을 주입하고 이 이미지를 얼룩말로 변환하려면 해야 할 일이 없기 때문에 동일한 얼룩 말을 얻는다. 아래 그림은 identity loss의 효과를 보여준다.

엄밀히 말해서 이 identity loss는 CycleGAN 작동에 필수적이지는 않고 일부 task에서만 사용된다.
'Visual Intelligence > Generative Model' 카테고리의 다른 글
| [Generative Model] SRGAN (0) | 2022.12.14 |
|---|---|
| [Generative Model] DCGAN (CIFAR-10) (0) | 2022.12.13 |
| [Generative Model] DCGAN (0) | 2022.12.09 |
| [Generative Model] GAN (MNIST) (0) | 2022.12.09 |
| [Generative Model] GAN (Generative Adversarial Network) (0) | 2022.12.09 |



