DCGAN
Ian Goodfellow가 GAN을 발표한 이후로 많은 분야에 GAN이 적용하여 연구가 되었지만 복잡한 영상에서는 좋은 이미지를 생성하지 못하였고 항상 불안정한 구조로 인한 문제가 따라붙었다. 그래서 이후 GAN을 다룬 논문들을 보면 공통적으로 이러한 부분에 대한 어려움에 대해 토로하고 있고, NIPS 2016 에서 Tutorial이나 workshop 세션에서도 큰 주제가 되었던 부분이 바로 이 "GAN의 안정화"였다.

Minimax problem을 풀어야하는 GAN은 어쩔 수 없이 태생적으로 불안정할 수밖에 없는데 이는 fixed solution으로 수렴하는 것이 보장되어 보이지만, 실제 적용에서는 이론적 가정이 깨지면서 생기는 불안정한 구조적 단점을 보이곤 했다.
이후 나온 여러 논문들이 GAN의 이런 단점을 지적하고 극복하기 위해서 다양한 접근을 통해 해결하고자 했는데, Deep Convolutional GAN (심층 합성곱 GAN, DCGAN)은 그중 가장 놀라운 성능을 보여주었다. DCGAN은 대부분 상황에서 안정적으로 학습이 되는 아키텍처로, Deep Generative Model 연구는 DCGAN 등장 이전과 이후로 나뉠 정도로 파급력이 컸다. DCGAN 이후 소개된 GAN 논문은 DCGAN 아키텍처에서 크게 벗어나지 않는다.
DCGAN은 이름에서 알 수 있듯이 Convolutional 구조를 GAN에 녹여 넣었다. 지도 학습에 CNN을 이용한 것을 컴퓨터 비전 분야에 큰 반향을 일으켰고, 그에 반해 비지도 학습에 CNN을 이용하는 것은 적은 관심을 받았는데 DCGAN은 지도 학습에서의 CNN의 성공과 비지도 학습 간의 격차를 줄이는 데에 큰 역할을 하였다.
DCGAN이 처음으로 Convolution을 GAN에 넣으려 시도한 모델은 아니다. 이전에도 다른 연구자들이 Convolution을 GAN 구조에 넣으려 시도했으나 별로 좋은 결과를 얻지는 못했다.
Convolution을 GAN에 넣으려고 시도한 이유는 바로 Scale up의 문제 때문이었다. DCGAN 이전의 높은 품질의 이미지 생성이 가능한 GAN 모델로는 LAPGANs가 유일했다. LAPGAN이후, DCGAN이 최초로 상당히 높은 품질의 영상을 single shot으로 만들어 내는 것에 성공하였다.
이전에 있던 여러 생성 모델들의 결과를 보면, MNIST나 질감 합성 등에 한정적으로 사용이 된 경우가 아니면 현실로부터 얻을 수 있는 자연적인 영상을 생성하는 것에 성공한 모델은 거의 없었다. Ian Goodfellow가 제시한 초기 GAN도 생성된 이미지를 보면 사람이 보아도 그럴듯한 이미지를 만들어 내지는 못했다. LAPGAN은 조금 더 그럴듯한 영상을 만들기는 했지만 구조로부터 기인하는 노이즈로 인해 물체들이 마치 흔들린 듯한 형체로 생성되는 문제가 여전히 남아 있었다.
또한, 이런 생성 영상의 품질에 대한 문제 외에도 신경망이 항상 Black-Box 방법일 뿐이라는 지적을 피 할 수가 없었다. 특히나 생성 모델의 성능을 판단하는 기준이 모호하기 때문에 실제 네트워크가 잘했는지 못했는지를 정량적으로 얘기하기가 쉽지 않다는 것이 같이 결부되면서 문제가 심화된다.
DCGAN에서는 Generator가 이미지를 외워서 보여주는 것이 아니란 것을 확인시켜주려 했고, Generator 의 latent space에서 움직일 때 급작스러운 변화가 아닌 부드러운 변화가 일어남을 보여주려고 하였다.

| 1) Max pooling과 같이 미분되지 않는 부분을 Convolution으로 대체하여 All Convolution Net으로 사용한다. 2) Fully connected hidden layer를 제거한다. 3) 출력 외의 모든 레이어에서는 ReLU를 사용하며 discriminator에서는 Leaky ReLU를 사용한다. 4) Batch Normalization을 추가하여 사용한다. 이때, Generator의 output layer, Discriminator의 input layer에는 추가하지 않는다. |
배치 정규화
배치 정규화는 2015년 구글 연구원인 Sergey Ioffe와 Christian Szegedy에 의해 소개된 아이디어로 신경망의 입력을 정규화하기 때문에 신경망을 통과하는 훈련 미니 배치를 위해 각 층의 입력을 정규화 하여 학습의 효율을 높인다.
| 정규화는 평균이 0이고 단위 분산을 가지도록 데이터의 스케일을 조정하는 것이다. 정규화는 스케일이 다른 특성을 쉽게 비교하고 더 나아가 특성의 스케일에 훈련 과정이 민감하지 않도록 만들어준다. |
배치 정규화는 신경망의 각 레이어에서 배치 데이터의 분포를 정규화하는 작업이다. 일종의 노이즈를 추가하는 방법으로 (bias와 유사) 이는 배치마다 정규화를 함으로써 전체 데이터에 대한 평균의 분산과 값이 달라질 수 있다. 학습을 할 때마다 출력값을 정규화하기 때문에 가중치 초기화 문제에서 비교적 자유로워진다.
각 은닉층에서 정규화를 하면서 입력 분포가 일정하게 되고, 이에 따라 learning rate를 크게 설정해도 문제가 줄어들면서 결과적으로 학습속도가 빨라지게 되고 안정적이게 된다.
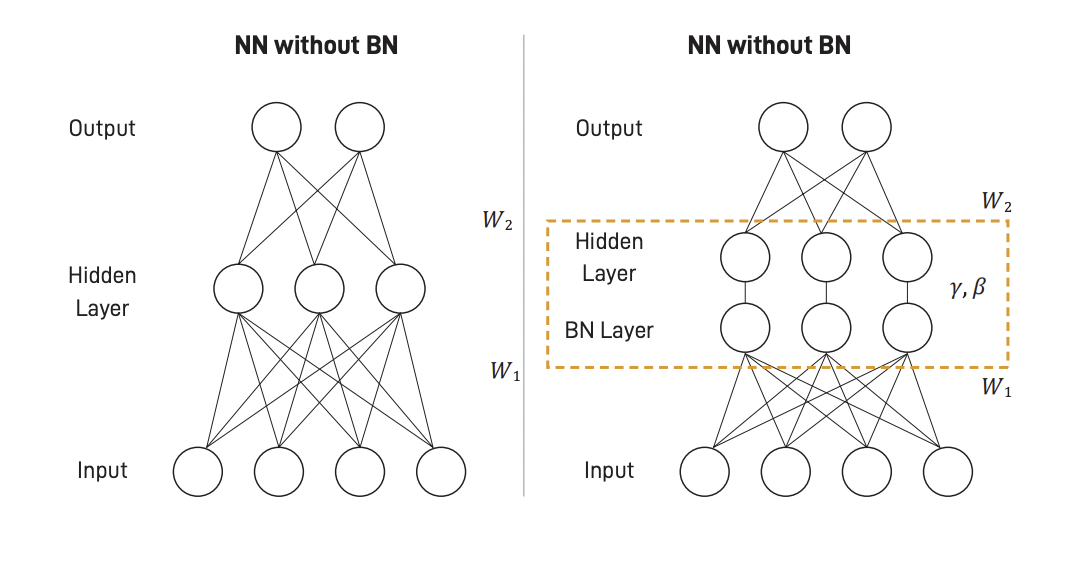
배치 정규화는 DCGAN을 비롯해 많은 딥러닝 구조를 구현하기 위해 필수적으로 사용되고 있다.
'Visual Intelligence > Generative Model' 카테고리의 다른 글
| [Generative Model] CycleGAN (0) | 2022.12.13 |
|---|---|
| [Generative Model] DCGAN (CIFAR-10) (0) | 2022.12.13 |
| [Generative Model] GAN (MNIST) (0) | 2022.12.09 |
| [Generative Model] GAN (Generative Adversarial Network) (0) | 2022.12.09 |
| [Generative Model] Neural style transfer (0) | 2022.12.09 |



