데이터 로드
from keras.layers import Input, Dense, Reshape, Flatten, Dropout
from keras.layers import BatchNormalization, Activation, ZeroPadding2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import UpSampling2D, Conv2D, Conv2DTranspose
from keras.models import Sequential, Model
from keras.optimizers import Adam,SGD
from keras import initializers
import os
import keras
from keras import layers
import matplotlib.pyplot as plt
import sys
import numpy as np
from keras.preprocessing import image
(X_train, y_train), (_, _) = keras.datasets.cifar10.load_data()
X_train = X_train[y_train.flatten() == 2]
def visualize_rgb(img):
"""
Visualize a rgb image
:param img: RGB image
"""
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.imshow(img)
ax.axis("off")
ax.set_title("Image")
plt.show()
visualize_rgb(X_train[0])
DCGAN 모델 생성
먼저, 모델의 입력 차원을 지정한다. 이미지 크기와 생성자의 입력으로 사용할 잡음 벡터 (latent space)의 길이이다.
# 입력 모양
img_rows = 32
img_cols = 32
channels = 3
img_shape = (img_rows, img_cols, channels)
latent_dim = 100
Convolution Network는 전통적으로 이미지 분류 작업에 사용된다. 이 네트워크는 ‘높이X너비X컬러 채널의 수’ 차원을 가진 영상을 입력으로 받아 일련의 합성곱 층을 통과시킨다. 그 다음, 클래스 점수를 담은 1 x n 차원의 벡터 하나를 출력한다. 여기에서 n은 클래스 레이블의 수다. Convolution Network 구조를 사용해 이미지를 생성하려면 이 과정을 거꾸로 하면 된다. 이미지를 받아 처리하여 벡터로 만드는 것이 아니라 벡터를 받아 크기를 늘려서 이미지로 만든다.
이 과정의 핵심 요소는 전차 합성곱 (transposed convolution)이다. 일반적인 합성곱은 전형적으로 깊이를 늘리면서 입력 너비와 높이를 줄이기 위해 사용한다. 전치 합성곱은 반대로 깊이를 줄이는 동안 너비와 높이를 증가시킨다.
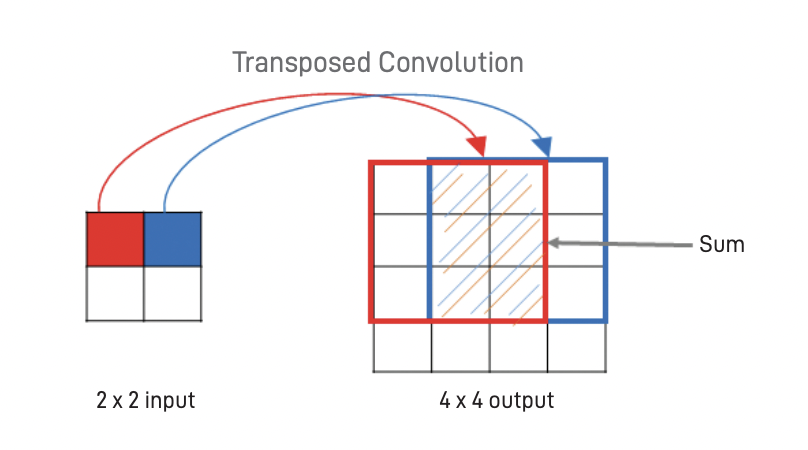
생성자는 잡음 벡터로부터 출발하여 완전 연결 층을 사용해 이 벡터를 작은 면적 (높이x너비)과 큰 깊이 를 가진 3차원 출력으로 바꾼다. 전치 합성곱을 사용하여 이 출력의 깊이는 줄이고 면적은 늘리도록 점진적으로 바꾸어 간다. 최종 층에 도달할 때 이미지 크기는 32 × 32 × 3 크기가 된다. 각 전치 합성곱 층 다음에는 배치 정규화와 LeakyReLU 활성화 함수를 적용한다. 마지막 층에서는 배치 정규화를 적용하지 않고 LeakyReLU 대신 tanh 활성화 함수를 사용한다.
init = initializers.RandomNormal(stddev=0.02)
# Generator 네트워크
generator = Sequential()
generator.add(Dense(2*2*512, input_shape=(latent_dim,), kernel_initializer=init))
generator.add(Reshape((2, 2, 512)))
generator.add(BatchNormalization())
generator.add(LeakyReLU(0.2))
generator.add(Conv2DTranspose(256, kernel_size=5, strides=2, padding='same'))
generator.add(BatchNormalization())
generator.add(LeakyReLU(0.2))
generator.add(Conv2DTranspose(128, kernel_size=5, strides=2, padding='same'))
generator.add(BatchNormalization())
generator.add(LeakyReLU(0.2))
generator.add(Conv2DTranspose(64, kernel_size=5, strides=2, padding='same'))
generator.add(BatchNormalization())
generator.add(LeakyReLU(0.2))
generator.add(Conv2DTranspose(3, kernel_size=5, strides=2, padding='same', activation='tanh'))
Discriminator는 Generator에서 생성된 이미지를 받아 예측 벡터를 출력하는 합성곱 신경망과 비슷한 Convolution Network이다. 이 경우 이진 분류기를 사용하여 입력 이미지가 가짜인지 진짜인지 나타낸다. 합성곱을 적용하여 이미지는 면적 (너비 × 높이)는 점차 줄어들고 깊이는 점점 깊어지는 식으로 변환한다. 그리고 모든 합성곱 층이 LeakyReLU 활성화 함수를 적용하며 출력층에서는 완전 연결층과 sigmoid 활성화 함수를 사용한다. 완전 연결 층 (Dense)과 sigmoid 활성화 함수를 사용하여 입력 이미지가 진짜일 확률을 계산한다.
# 이미지 모양 (32x32x3)
img_shape = X_train[0].shape
# Discriminator 네트워크
discriminator = Sequential()
discriminator.add(Conv2D(64, kernel_size=5, strides=2, padding='same', input_shape=(img_shape), kernel_initializer=init))
discriminator.add(LeakyReLU(0.2))
discriminator.add(Conv2D(128, kernel_size=5, strides=2, padding='same'))
discriminator.add(BatchNormalization())
discriminator.add(LeakyReLU(0.2))
discriminator.add(Conv2D(256, kernel_size=5, strides=2, padding='same'))
discriminator.add(BatchNormalization())
discriminator.add(LeakyReLU(0.2))
discriminator.add(Conv2D(512, kernel_size=5, strides=2, padding='same'))
discriminator.add(BatchNormalization())
discriminator.add(LeakyReLU(0.2))
discriminator.add(Flatten())
discriminator.add(Dense(1, activation='sigmoid'))
discriminator.compile(Adam(lr=0.0003, beta_1=0.5), loss='binary_crossentropy', metrics=['binary_accuracy'])
그 다음, generator 모델과 discriminator 모델을 이어준다. GAN 전체 모델에 있어서 손실 함수와 최적화 함수를 설정해준다.
discriminator.trainable = False
z = Input(shape=(latent_dim,))
img = generator(z)
decision = discriminator(img)
gan_model = Model(inputs=z, outputs=decision)
gan_model.compile(Adam(lr=0.0004, beta_1=0.5), loss='binary_crossentropy', metrics=['binary_accuracy'])
모델 학습
def normalize(img):
return (img - 127.5) / 127.5
def denormalize(img):
img = (img * 127.5) + 127.5
return img.astype(np.uint8)
# 데이터 정규화
X_train = normalize(X_train)
iterations = 5000
batch_size = 20
save_dir = os.path.join("./", 'gan_images')
if not os.path.exists(save_dir):
os.mkdir(save_dir)
모델을 학습하면서 일정 epoch마다 모델의 가중치와 그때 생성된 이미지를 저장한다.
from tensorflow.keras.preprocessing import image
epochs = 100
batch_size = 32
smooth = 0.1
real = np.ones(shape=(batch_size, 1))
fake = np.zeros(shape=(batch_size, 1))
d_loss = []
g_loss = []
for e in range(epochs + 1):
for i in range(len(X_train) // batch_size):
discriminator.trainable = True
X_batch = X_train[i*batch_size:(i+1)*batch_size]
d_loss_real = discriminator.train_on_batch(x=X_batch, y=real * (1 - smooth))
z = np.random.normal(loc=0, scale=1, size=(batch_size, latent_dim))
X_fake = generator.predict_on_batch(z)
d_loss_fake = discriminator.train_on_batch(x=X_fake, y=fake)
# Discriminator 손실값
d_loss_batch = 0.5 * (d_loss_real[0] + d_loss_fake[0])
discriminator.trainable = False
g_loss_batch = gan_model.train_on_batch(x=z, y=real)
print('epoch = %d/%d, batch = %d/%d, d_loss=%.3f, g_loss=%.3f' % (e + 1, epochs, i, len(X_train) // batch_size, d_loss_batch, g_loss_batch[0]), 100*' ', end='\r')
d_loss.append(d_loss_batch)
g_loss.append(g_loss_batch[0])
print('epoch = %d/%d, d_loss=%.3f, g_loss=%.3f' % (e + 1, epochs, d_loss[-1], g_loss[-1]), 100*' ')
if e % 3 == 0:
# 모델 가중치를 저장
gan_model.save_weights('gan.h5')
# 생성된 이미지 하나를 저장
img = image.array_to_img(denormalize(X_fake[0]), scale=False)
img.save(os.path.join(save_dir, 'generated' + str(e) + '.png'))
# 비교를 위해 진짜 이미지 하나를 저장
img = image.array_to_img(denormalize(X_batch[0]), scale=False)
img.save(os.path.join(save_dir, 'real' + str(e) + '.png'))

DCGAN은 GAN 프레임워크의 유연성을 잘 보여준다. 이론적으로 판별자와 생성자는 미분가능한 어떤 함수로도 표현할 수 있다. 심지어 다층 합성곱 신경망처럼 복잡한 것도 가능하다. 하지만 DCGAN은 실전에서 더 복잡한 구현을 만드는 데 어려움이 있다는 것도 보여준다. 배치 정규화와 같은 혁신적인 아이디어가 없다면 DCGAN은 잘 훈련되지 못할 것이다. 또한, 여전히 모델에 불안정성이 남아 있다. 이후 많은 연구들이 DCGAN을 기반으로 여러 모델들을 제안하여 이러한 문제점들을 해결하려 하고 있다.
'Visual Intelligence > Generative Model' 카테고리의 다른 글
| [Generative Model] SRGAN (0) | 2022.12.14 |
|---|---|
| [Generative Model] CycleGAN (0) | 2022.12.13 |
| [Generative Model] DCGAN (0) | 2022.12.09 |
| [Generative Model] GAN (MNIST) (0) | 2022.12.09 |
| [Generative Model] GAN (Generative Adversarial Network) (0) | 2022.12.09 |



