SRGAN
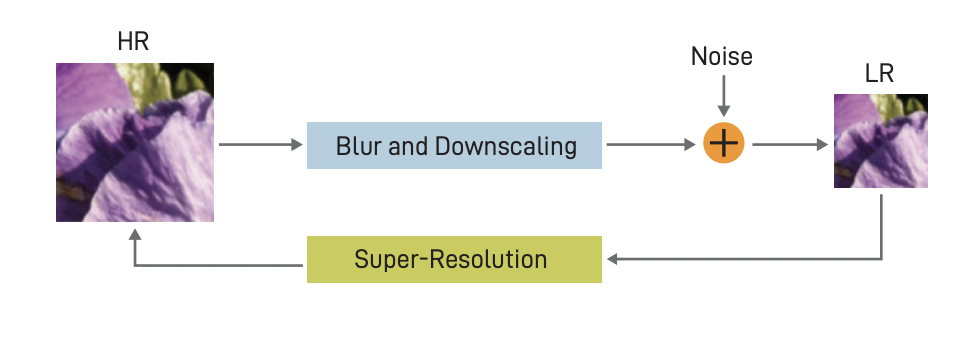
단일 이미지 초해상도 (Single Image Super Resolution)는 컴퓨터 비전 연구 분야의 한 갈래로 저해상도 (Low Resolution, LR) 영상으로부터 고해상도 (High Resolution, HR) 영상을 생성하는 기술이다.

일반적으로, 저해상도 영상으로부터 고해상도 영상을 복원하는 문제는 부적절하게 정립된 역 문제 (ill-posed inverse problem)로 정의된다. 기존에는 보간법 (Interpolation) 혹은 선형 매핑 (Linear Mapping) 을 사용한 로컬 패치 (local patch) 기반의 초해상화 기법들이 널리 연구되었다. 그러나 이러한 기법들은 비교적 매끄러운 효과를 주거나 선형적인 특징만을 살리기 때문에 복잡하고 비선형적인 고주파 세부 사항들을 놓치게 된다.
해당 문제를 해결하기 위해 CNN을 도입하였고, 기존 전통적인 알고리즘 대비 정확도와 속도 면에서 높 은 성능을 보여주었다. 아래는 CNN 기반의 초해상화 모델인 SRCNN의 구조이다.

고해상도 영상을 만들기 위한 CNN 기반 딥러닝 모델은 계속 발전되어 왔지만 이미지의 특징적인 디테일보다 ‘Upscaling’ 자체에 집중하는 경향이 강했다. SR 문제에서 해결해야 할 문제인 미세한 질감 세부 사항들 (texture details)을 어떻게 고해상도 복원할 것인가에 대해 풀리고 있지 않았다. 이를 위해 2017년도 Ledig은 Perceptual loss로 고해상도를 달성한 Super Resolution GAN을 제안하였다.
일반적으로 재구성된 SR 이미지에서는 보통 High Frequency detail들이 부족하기 때문에 High upscaling factors에서 문제가 드러난다. 이를 위해 기존 모델들은 MSE를 최소화시켜 PSNR을 최대화 시키는 방법을 사용하는데, 이는 픽셀 영상의 차이를 기반으로 두었기 때문에 High texture detail 등 미세한 질감 효과에 대해서 매우 제한적이다. SRGAN은 Skip-connection과 MSE로 나뉘는 ResNet 구조와 새롭게 정의한 perceptual loss를 이용하여 4배의 upscaling factor를 가지는 초고해상도 영상 생성을 가능하게 하였다.
PSNR은 최고 신호의 전력 대비 손실을 나타내고, SSIM은 구조적 유사지도로서 두 값들은 보통 Resolution을 나타낼 때 많이 쓰이는 정량적인 값이다. 이때, 아래의 Bicubic 이미지와 SRGAN 이미지 를 비교하였을 때 SRGAN의 PSNR 값이 더 작음에도 불구하고 훨씬 더 좋은 resolution을 보이는 것을 알 수 있다.

SRGAN에서는 더 깊은 네트워크 구조를 사용하였다. 이는 훈련하기가 어려우나, 매우 높은 복잡도의 모델링 매핑을 허용하기 때문에 네트워크의 정확성을 크게 높일 수 있는 가능성이 있다고 한다. 깊은 네트워크 구조를 효율적으로 학습시키기 위해 Batch normalization이 사용되는데, 내부의 covariate shift를 막기 위해 사용된다. 또한, skip connection은 네트워크 구조를 완화시키고, Upscaling filter는 정확도와 스피드에 있어서 향상되게 하였다.

MSE와 같은 픽셀 기반 함수들은 high frequency detail들에 내재되어 있는 불확실성을 조절하기 위해 노력한다. 하지만 MSE를 예시로 들자면, MSE를 최소화하면 지나치게 smoothing하기 때문에 나쁜 perceptual quality를 갖게 된다. 이와 달리 GAN은 natural image manifold에서 재구성된 영상을 복원하기 때문에 더 perceptual한 영상을 만들어 준다. 또한, VGG network에서 추출한 feature map들 간의 Euclidean 거리를 기반으로 한 손실 함수를 구성하여 초고해상도나 style transfer에 유의미한 결과를 도출하였다.


Generator 모델을 만들 때, 핵심으로 동일한 레이아웃을 가진 B residual block이 있다. 모델은 3*3 커널과 64개의 특징 맵을 가진 두개의 컨볼루션 레이어를 사용하였고, batch normalization과 activation function으로 쓰인 parametricrelu (각 차원마다 학습된 ReLU를 사용하는)를 사용하였다. 또한, train되어 있는 2개의 sub-pixel convolution 레이어를 이용해 이미지의 해상도를 높였다.


Discriminator 모델의 경우, max-pooling을 방지하기 위해 LeakyReLU activation을 사용하였고, 방정식의 최대화 문제를 해결하기 위해 train되었다. 마지막에 sigmoid activation function을 사용하여 sample classification의 확률을 얻는다.
손실 함수
픽셀 단위의 MSE loss function은 아래 식으로 계산된다. 이건은 SR에서 가장 널리 이용되는 Optimization 방법인데 실제 High resolution한 이미지 값과 Low resolution 이미지에서 만들어낸 Super resolution 이미지 값의 차이를 제곱하여 평균화한 값이 이 MSE loss으로 생각하였다. PSNR은 다음 공식과 같이 MSE 값이 분모에 있기 때문에 MSE값과 역수 관계에 있다. 따라서, MSE 값이 낮아질 수록 PSNR값이 높아지지만, 이 같은 경우에는 너무 smoothing되기 때문에 High frequency content 값이 부족하여 texture가 잘 표현되지 않는다.
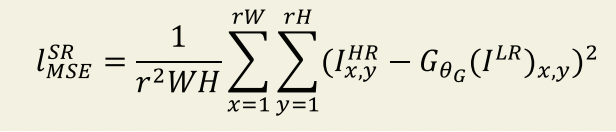
따라서, SRGAN에서는 VGG-19 네트워크의 ReLU 활성화 계층을 기반으로 VGG 손실을 정의한다. 이 방법은 사전 훈련된 네트워크를 이용해서 feature map에서의 유클리드 거리를 계산하는 방법이다. 따라서, pixel의 값에 중심을 두기보다 perceptual similarity를 주목하였기 때문에 보다 detail한 부분을 잘 잡아냈다.
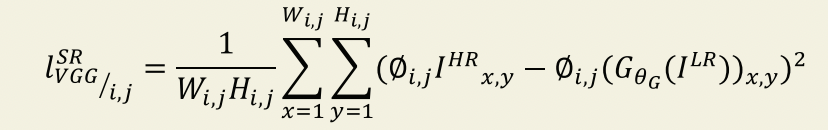
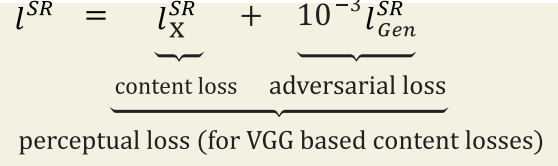
위의 VGG 손실과 Adversarial 손실을 더하여 최종적으로 아래와 같은 perceptual loss function이 완성된다.
'Visual Intelligence > Generative Model' 카테고리의 다른 글
| [Generative Model] CycleGAN (0) | 2022.12.13 |
|---|---|
| [Generative Model] DCGAN (CIFAR-10) (0) | 2022.12.13 |
| [Generative Model] DCGAN (0) | 2022.12.09 |
| [Generative Model] GAN (MNIST) (0) | 2022.12.09 |
| [Generative Model] GAN (Generative Adversarial Network) (0) | 2022.12.09 |



