728x90
반응형
SMALL
데이터셋 로드
Medical_Insurance_dataset.csv
0.22MB
import pandas as pd
df = pd.read_csv('Medical_Insurance_dataset.csv')
df.head()
원-핫 인코딩
df = pd.get_dummies(df)
df.head()
데이터 전처리
# 훈련 데이터, 검증 데이터, 테스트 데이터 나누기
features = df[df.keys().drop('charges')].values
outcome = df['charges'].values.reshape(-1, 1)
from sklearn.model_selection import train_test_split
train_features, test_features, train_target, test_target = train_test_split(features, outcome, test_size=0.3)
train_features, val_features, train_target, val_target = train_test_split(train_features, train_target, test_size=0.3)
데이터 스케일링
from sklearn.preprocessing import MinMaxScaler
feature_scaler = MinMaxScaler()
train_features_scaled = feature_scaler.fit_transform(train_features)
val_features_scaled = feature_scaler.transform(val_features)
test_features_scaled = feature_scaler.transform(test_features)
모델 훈련
from xgboost import XGBRegressor
from xgboost.callback import EarlyStopping
xgb = XGBRegressor()
early_stop = EarlyStopping(rounds=20,metric_name='rmse',data_name="validation_0",save_best=True)
xgb.fit(train_features_scaled, train_target,eval_set=[(val_features_scaled, val_target)], eval_metric='rmse', callbacks=[early_stop])
result = xgb.predict(test_features_scaled)# 회귀 성능 평가
from sklearn.metrics import mean_absolute_error, mean_squared_error
import numpy as np
print('MAE :',mean_absolute_error(test_target, result))
print('RMSE :',np.sqrt(mean_squared_error(test_target, result)))MAE : 1778.4481490093838
RMSE : 3678.061753847381import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(10,5))
plt.plot(test_target,linestyle='-',color='blue',label='Observed')
plt.plot(result,linestyle='--',color='red',label='Forecast')
plt.legend()
plt.show()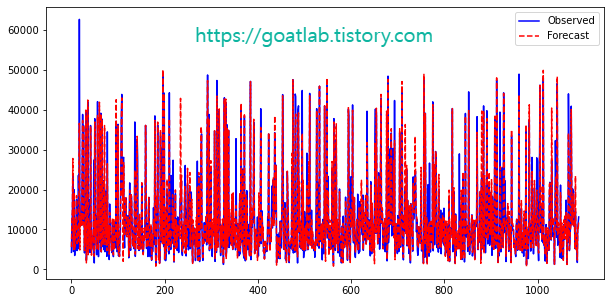
GridSearchCV를 통한 최적화
from xgboost import XGBRegressor
from sklearn.model_selection import GridSearchCV
xgb = XGBRegressor()
parameters = {'learning_rate':[0.01,0.05,0.07,0.1]}
xgb_grid = GridSearchCV(xgb, parameters, cv = 5, n_jobs=-1)
xgb_grid.fit(train_features_scaled,train_target)# 하이퍼파라미터 최적화
print(xgb_grid.best_score_)
print(xgb_grid.best_params_)0.8931528352067961
{'learning_rate': 0.07}# 최적의 하이퍼파라미터를 설정하고 학습
from xgboost import XGBRegressor
from xgboost.callback import EarlyStopping
xgb = XGBRegressor(learning_rate=0.05)
early_stop = EarlyStopping(rounds=20,metric_name='rmse',data_name="validation_0",save_best=True)
xgb.fit(train_features_scaled, train_target,eval_set=[(val_features_scaled, val_target)], eval_metric='rmse', callbacks=[early_stop])
result = xgb.predict(test_features_scaled)# 성능 평가 결과
from sklearn.metrics import mean_absolute_error, mean_squared_error
import numpy as np
print('MAE :',mean_absolute_error(test_target, result))
print('RMSE :',np.sqrt(mean_squared_error(test_target, result)))plt.figure(figsize=(10,5))
plt.plot(test_target,linestyle='-',color='blue',label='Observed')
plt.plot(result,linestyle='--',color='red',label='Forecast')
plt.legend()
plt.show()
728x90
반응형
LIST
'Learning-driven Methodology > ML (Machine Learning)' 카테고리의 다른 글
| [Machine Learning] 이상 탐지 (Anomaly Detection) (0) | 2022.11.17 |
|---|---|
| [Machine Learning] 오토인코더 (Autoencoder) (0) | 2022.11.11 |
| [XGBoost] 심혈관 질환 예측 (0) | 2022.10.05 |
| [XGBoost] 심장 질환 예측 (0) | 2022.10.04 |
| [XGBoost] 위스콘신 유방암 데이터 (3) (0) | 2022.10.04 |



