모델 만들기
모델을 구성한다. 여기에서는 두 개의 완전 연결 (densely connected) 은닉층으로 Sequential 모델을 만든다. 출력 층은 하나의 연속적인 값을 반환한다. 나중에 두 번째 모델을 만들기 쉽도록 build_model 함수로 모델 구성 단계를 감싼다.
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
모델 확인
.summary 메서드를 사용해 모델에 대한 간단한 정보를 출력한다.
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 64) 640
_________________________________________________________________
dense_1 (Dense) (None, 64) 4160
_________________________________________________________________
dense_2 (Dense) (None, 1) 65
=================================================================
Total params: 4,865
Trainable params: 4,865
Non-trainable params: 0
_________________________________________________________________
모델을 실행하면, 훈련 세트에서 10 샘플을 하나의 배치로 만들어 model.predict 메서드를 호출한다.
example_batch = normed_train_data[:10]
example_result = model.predict(example_batch)
example_result
array([[0.6247854 ],
[0.33749408],
[0.20907241],
[0.35342616],
[0.91920185],
[0.19368024],
[1.0528278 ],
[0.8886562 ],
[0.40983236],
[1.1161143 ]], dtype=float32)
모델 훈련
이 모델을 1,000번의 에포크 (epoch)동안 훈련한다. 훈련 정확도와 검증 정확도는 history 객체에 기록된다.
# 에포크가 끝날 때마다 점(.)을 출력해 훈련 진행 과정을 표시합니다
class PrintDot(keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs):
if epoch % 100 == 0: print('')
print('.', end='')
EPOCHS = 1000
history = model.fit(
normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2, verbose=0,
callbacks=[PrintDot()])
history 객체에 저장된 통계치를 사용해 모델의 훈련 과정을 시각화한다.
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
hist.tail()
import matplotlib.pyplot as plt
def plot_history(history):
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
plt.figure(figsize=(8,12))
plt.subplot(2,1,1)
plt.xlabel('Epoch')
plt.ylabel('Mean Abs Error [MPG]')
plt.plot(hist['epoch'], hist['mae'],
label='Train Error')
plt.plot(hist['epoch'], hist['val_mae'],
label = 'Val Error')
plt.ylim([0,5])
plt.legend()
plt.subplot(2,1,2)
plt.xlabel('Epoch')
plt.ylabel('Mean Square Error [$MPG^2$]')
plt.plot(hist['epoch'], hist['mse'],
label='Train Error')
plt.plot(hist['epoch'], hist['val_mse'],
label = 'Val Error')
plt.ylim([0,20])
plt.legend()
plt.show()
plot_history(history)

그래프를 보면 수 백번 에포크를 진행한 이후에는 모델이 거의 향상되지 않는 것 같다. model.fit 메서드를 수정하여 검증 점수가 향상되지 않으면 자동으로 훈련을 멈추도록 만들어야 한다. 에포크마다 훈련 상태를 점검하기 위해 EarlyStopping 콜백 (callback)을 사용한다. 지정된 에포크 횟수 동안 성능 향상이 없으면 자동으로 훈련이 멈춘다.
콜백에 대해 더 자세한 내용은 여기를 참고하면 된다.
model = build_model()
# patience 매개변수는 성능 향상을 체크할 에포크 횟수입니다
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
history = model.fit(normed_train_data, train_labels, epochs=EPOCHS,
validation_split = 0.2, verbose=0, callbacks=[early_stop, PrintDot()])
plot_history(history)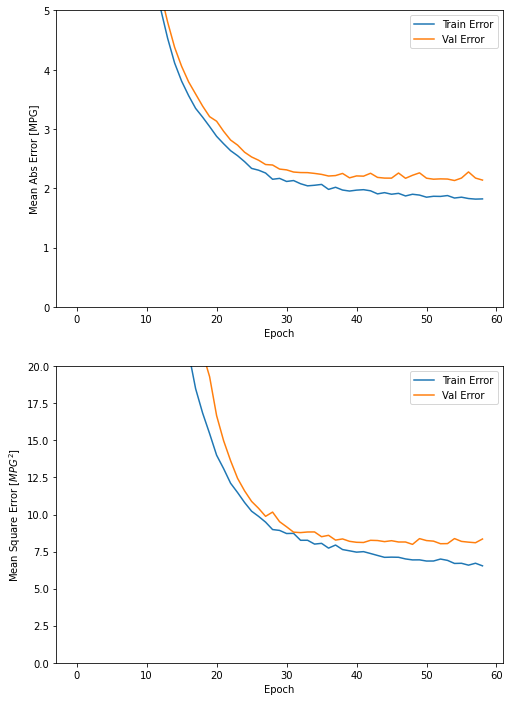
그래프를 보면 검증 세트의 평균 오차가 약 +/- 2 MPG입니다.
모델을 훈련할 때 사용하지 않았던 테스트 세트에서 모델의 성능을 확인해 본다. 이를 통해 모델이 실전에 투입되었을 때 모델의 성능을 짐작할 수 있다.
loss, mae, mse = model.evaluate(normed_test_data, test_labels, verbose=2)
print("테스트 세트의 평균 절대 오차: {:5.2f} MPG".format(mae))
3/3 - 0s - loss: 6.1271 - mae: 1.9506 - mse: 6.1271
테스트 세트의 평균 절대 오차: 1.95 MPG
예측
마지막으로 테스트 세트에 있는 샘플을 사용해 MPG 값을 예측한다.
test_predictions = model.predict(normed_test_data).flatten()
plt.scatter(test_labels, test_predictions)
plt.xlabel('True Values [MPG]')
plt.ylabel('Predictions [MPG]')
plt.axis('equal')
plt.axis('square')
plt.xlim([0,plt.xlim()[1]])
plt.ylim([0,plt.ylim()[1]])
_ = plt.plot([-100, 100], [-100, 100])
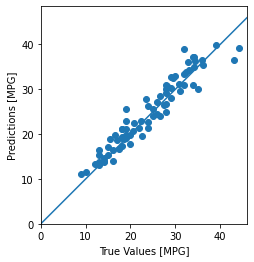
모델이 꽤 잘 예측한 것 같다. 오차의 분포를 살펴 본다.
error = test_predictions - test_labels
plt.hist(error, bins = 25)
plt.xlabel("Prediction Error [MPG]")
_ = plt.ylabel("Count")
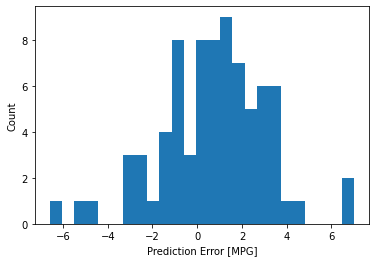
가우시안 분포가 아니지만 아마도 훈련 샘플의 수가 매우 작기 때문일 것이다.
https://www.tensorflow.org/tutorials/keras/regression?hl=ko#%EB%AA%A8%EB%8D%B8
자동차 연비 예측하기: 회귀 | TensorFlow Core
Google I/O는 끝입니다! TensorFlow 세션 확인하기 세션 보기 자동차 연비 예측하기: 회귀 Note: 이 문서는 텐서플로 커뮤니티에서 번역했습니다. 커뮤니티 번역 활동의 특성상 정확한 번역과 최신 내용
www.tensorflow.org
'DNN with Keras > TensorFlow' 카테고리의 다른 글
| [TensorFlow] 과대적합 / 과소적합 (2) (0) | 2022.06.15 |
|---|---|
| [TensorFlow] 과대적합 / 과소적합 (1) (0) | 2022.06.15 |
| [TensorFlow] 회귀 (Regression) (1) (0) | 2022.06.15 |
| [TensorFlow] 기본 분류 (텍스트 분류) (2) (0) | 2022.06.15 |
| [TensorFlow] 기본 분류 (텍스트 분류) (1) (0) | 2022.06.15 |



