회귀 (Regression)
회귀 (regression)는 가격이나 확률 같이 연속된 출력 값을 예측하는 것이 목적이다. 이와는 달리 분류 (classification)는 여러개의 클래스 중 하나의 클래스를 선택하는 것이 목적이다 (예를 들어, 사진에 사과 또는 오렌지가 포함되어 있을 때 어떤 과일인지 인식하는 것).
Auto MPG 데이터셋을 사용하여 1970년대 후반과 1980년대 초반의 자동차 연비를 예측하는 모델을 만든다. 이 기간에 출시된 자동차 정보를 모델에 대한 정보가 있다. 이 정보에는 실린더 수, 배기량, 마력 (horsepower), 공차 중량 같은 속성이 포함된다.
이 예제는 tf.keras API를 사용한다. 자세한 내용은 케라스 가이드를 참고하면 된다.
# 산점도 행렬을 그리기 위해 seaborn 패키지를 설치합니다
pip install -q seaborn
import pathlib
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
Auto MPG 데이터셋
이 데이터셋은 UCI 머신 러닝 저장소에서 다운로드할 수 있다.
데이터 구하기
먼저, 데이터셋을 다운로드한다.
dataset_path = keras.utils.get_file("auto-mpg.data", "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
dataset_path
판다스를 사용하여 데이터를 읽는다.
column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight',
'Acceleration', 'Model Year', 'Origin']
raw_dataset = pd.read_csv(dataset_path, names=column_names,
na_values = "?", comment='\t',
sep=" ", skipinitialspace=True)
dataset = raw_dataset.copy()
dataset.tail()

데이터 정제하기
이 데이터셋은 일부 데이터가 누락되어 있다.
dataset.isna().sum()
MPG 0
Cylinders 0
Displacement 0
Horsepower 6
Weight 0
Acceleration 0
Model Year 0
Origin 0
dtype: int64
문제를 간단하게 만들기 위해서 누락된 행을 삭제한다.
dataset = dataset.dropna()
"Origin" 열은 수치형이 아니고 범주형이므로 원-핫 인코딩 (one-hot encoding)으로 변환한다.
origin = dataset.pop('Origin')
dataset['USA'] = (origin == 1)*1.0
dataset['Europe'] = (origin == 2)*1.0
dataset['Japan'] = (origin == 3)*1.0
dataset.tail()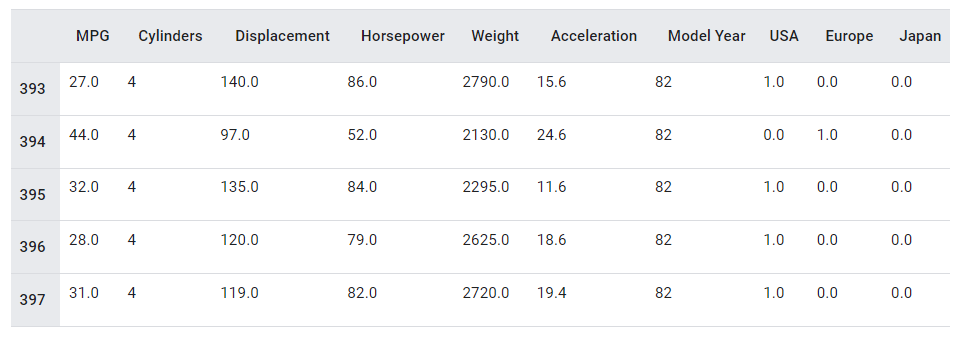
데이터셋을 훈련 세트와 테스트 세트로 분할하기
이제 데이터를 훈련 세트와 테스트 세트로 분할한다. 테스트 세트는 모델을 최종적으로 평가할 때 사용한다.
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
데이터 조사하기
훈련 세트에서 몇 개의 열을 선택해 산점도 행렬을 만들어 살펴 본다.
sns.pairplot(train_dataset[["MPG", "Cylinders", "Displacement", "Weight"]], diag_kind="kde")
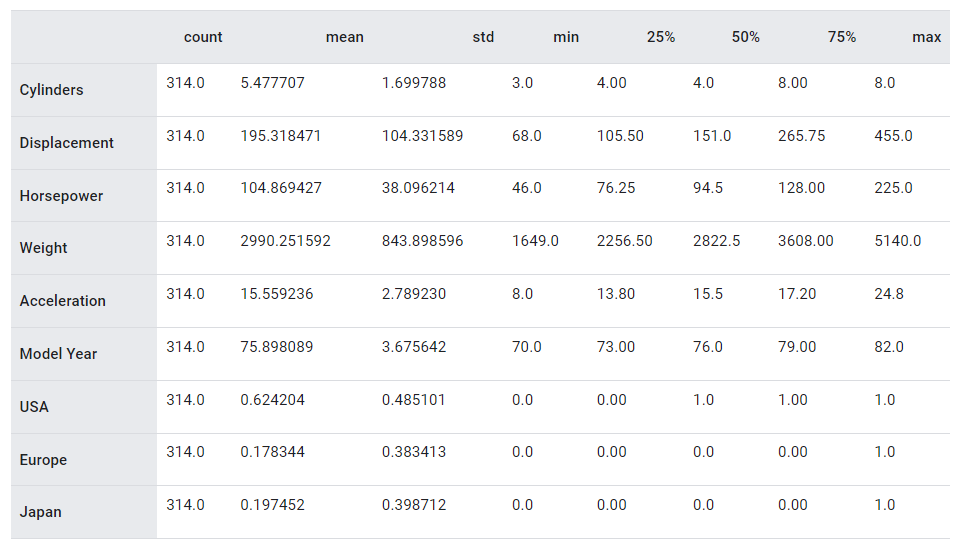
train_stats = train_dataset.describe()
train_stats.pop("MPG")
train_stats = train_stats.transpose()
train_stats
특성과 레이블 분리하기
특성에서 타깃 값 또는 "레이블"을 분리한다. 이 레이블을 예측하기 위해 모델을 훈련시킨다.
train_labels = train_dataset.pop('MPG')
test_labels = test_dataset.pop('MPG')
데이터 정규화
위 train_stats 통계를 다시 살펴보고 각 특성의 범위가 얼마나 다른지 확인한다.
특성의 스케일과 범위가 다르면 정규화 (normalization)하는 것이 권장된다. 특성을 정규화하지 않아도 모델이 수렴할 수 있지만, 훈련시키기 어렵고 입력 단위에 의존적인 모델이 만들어진다.
(의도적으로 훈련 세트만 사용하여 통계치를 생성했다. 이 통계는 테스트 세트를 정규화할 때에도 사용된다. 이는 테스트 세트를 모델이 훈련에 사용했던 것과 동일한 분포로 투영하기 위해서이다.)
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
정규화된 데이터를 사용하여 모델을 훈련한다.
(주의: 여기에서 입력 데이터를 정규화하기 위해 사용한 통계치 (평균과 표준편차)는 원-핫 인코딩과 마찬가지로 모델에 주입되는 모든 데이터에 적용되어야 한다. 여기에는 테스트 세트는 물론 모델이 실전에 투입되어 얻은 라이브 데이터도 포함된다.)
https://www.tensorflow.org/tutorials/keras/regression?hl=ko
자동차 연비 예측하기: 회귀 | TensorFlow Core
Google I/O는 끝입니다! TensorFlow 세션 확인하기 세션 보기 자동차 연비 예측하기: 회귀 Note: 이 문서는 텐서플로 커뮤니티에서 번역했습니다. 커뮤니티 번역 활동의 특성상 정확한 번역과 최신 내용
www.tensorflow.org
'DNN with Keras > TensorFlow' 카테고리의 다른 글
| [TensorFlow] 과대적합 / 과소적합 (1) (0) | 2022.06.15 |
|---|---|
| [TensorFlow] 회귀 (Regression) (2) (0) | 2022.06.15 |
| [TensorFlow] 기본 분류 (텍스트 분류) (2) (0) | 2022.06.15 |
| [TensorFlow] 기본 분류 (텍스트 분류) (1) (0) | 2022.06.15 |
| [TensorFlow] 기본 분류 (이미지 분류) (2) (0) | 2022.06.15 |



