728x90
반응형
SMALL
데이터 로드
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
iris_dt = load_iris()
train_x, test_x, train_y, test_y = train_test_split(iris_dt.data, iris_dt.target,
test_size=0.2, random_state=0)
print(train_x.shape)
print(test_x.shape)
print(train_y.shape)
print(test_y.shape)
모델 학습
tree_clf = DecisionTreeClassifier(random_state=0)
tree_clf.fit(train_x, train_y)
tree_clf.score(test_x, test_y)
트리 그리기
fn = iris_dt.feature_names # 각 특징의 이름
cn = iris_dt.target_names # 꽃의 이름
fig, axes = plt.subplots(nrows=1, ncols=1, figsize=(4,4), dpi=300) # figure 모양을 설정
tree.plot_tree(tree_clf,
feature_names=fn,
class_names=cn,
filled=True)
fig.savefig("tree.png")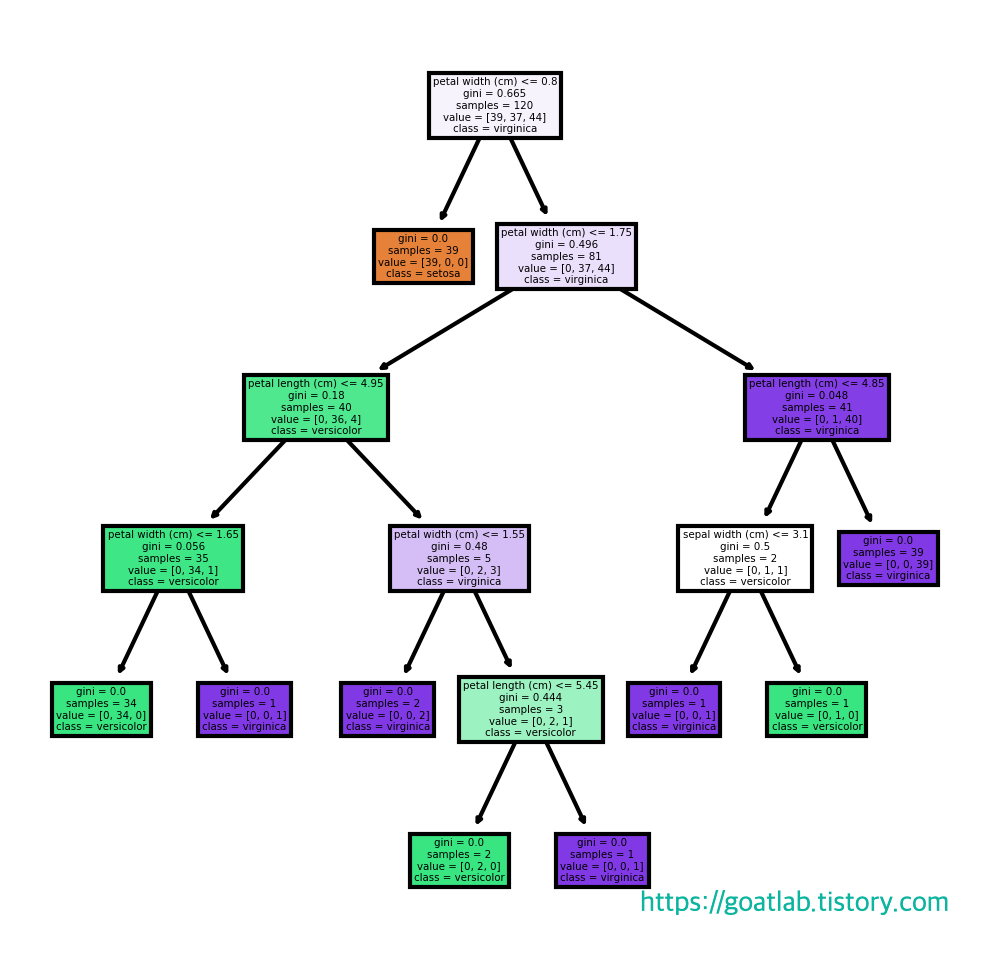
중요도 확인
se0 = pd.Series(tree_clf.feature_importances_, index=fn)
se0sepal length (cm) 0.000000
sepal width (cm) 0.012534
petal length (cm) 0.064446
petal width (cm) 0.923020
dtype: float64se0.plot(kind='barh')
오버피팅 확인
def vilsualize_boudary(model, X, y):
fig, ax = plt.subplots()
ax.scatter(X[:, 0], X[:, 1], c=y, s=25, cmap='rainbow', edgecolor='k')
#clim=(y.min(), y.max()), zorder=3)
ax.axis('tight')
ax.axis('off')
xlim_start, xlim_end = ax.get_xlim()
ylim_start, ylim_end = ax.get_ylim()
# 모델을 학습하고 메시그리드를 사용해 다양한 X 값을 구성하고 예측한 값 생성
model.fit(X,y)
xx, yy = np.meshgrid(np.linspace(xlim_start, xlim_end, num=200),
np.linspace(ylim_start, ylim_end, num=200))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape)
# 예측한 정보를 뒷 배경에 색칠
n_classes = len(np.unique(y)) # 타겟의 고유한 개수를 확인
contours = ax.contourf(xx, yy, Z, alpha=0.3,
levels=np.arange(n_classes + 1) - 0.5,
cmap='rainbow') #, clim=(y.min(), y.max()), zorder=1)
vilsualize_boudary(tree_clf, train_x[:,2:], train_y)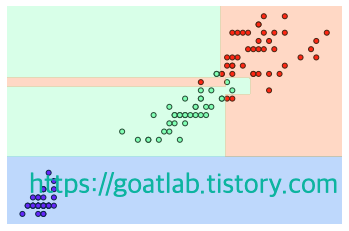
# 샘플 개수에 제한을 줘서 모델 학습
new_tree_clf = DecisionTreeClassifier(random_state=0, min_samples_leaf=6)
new_tree_clf.fit(train_x, train_y)
vilsualize_boudary(new_tree_clf, train_x[:,2:], train_y)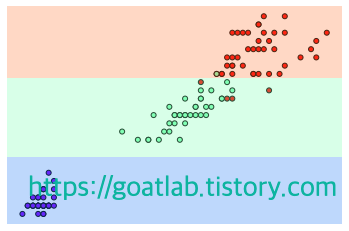
fn = iris_dt.feature_names # 각 특징의 이름
cn = iris_dt.target_names # 꽃의 이름
fig, axes = plt.subplots(nrows=1, ncols=1, figsize=(4,4), dpi=300) # figure 모양을 설정
tree.plot_tree(new_tree_clf,
feature_names=fn,
class_names=cn,
filled=True)
fig.savefig("new_tree_clf.png")
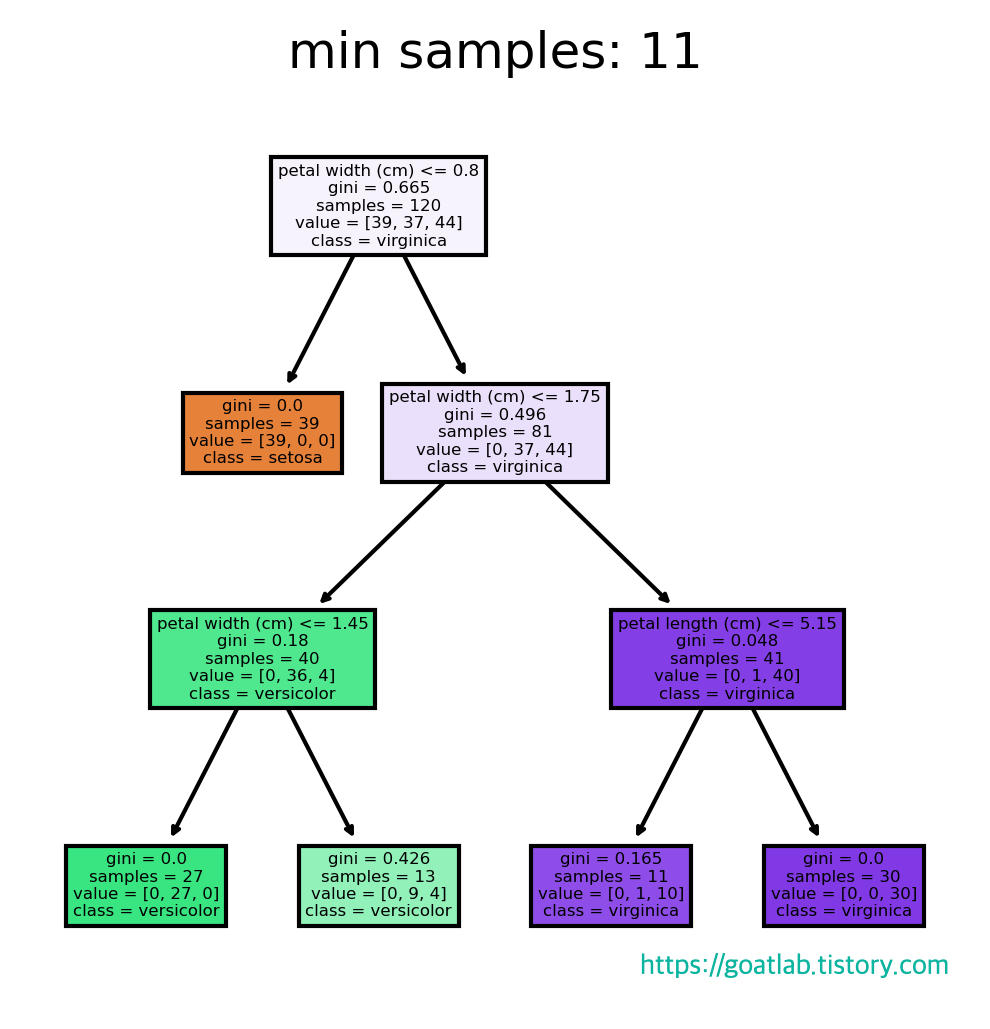
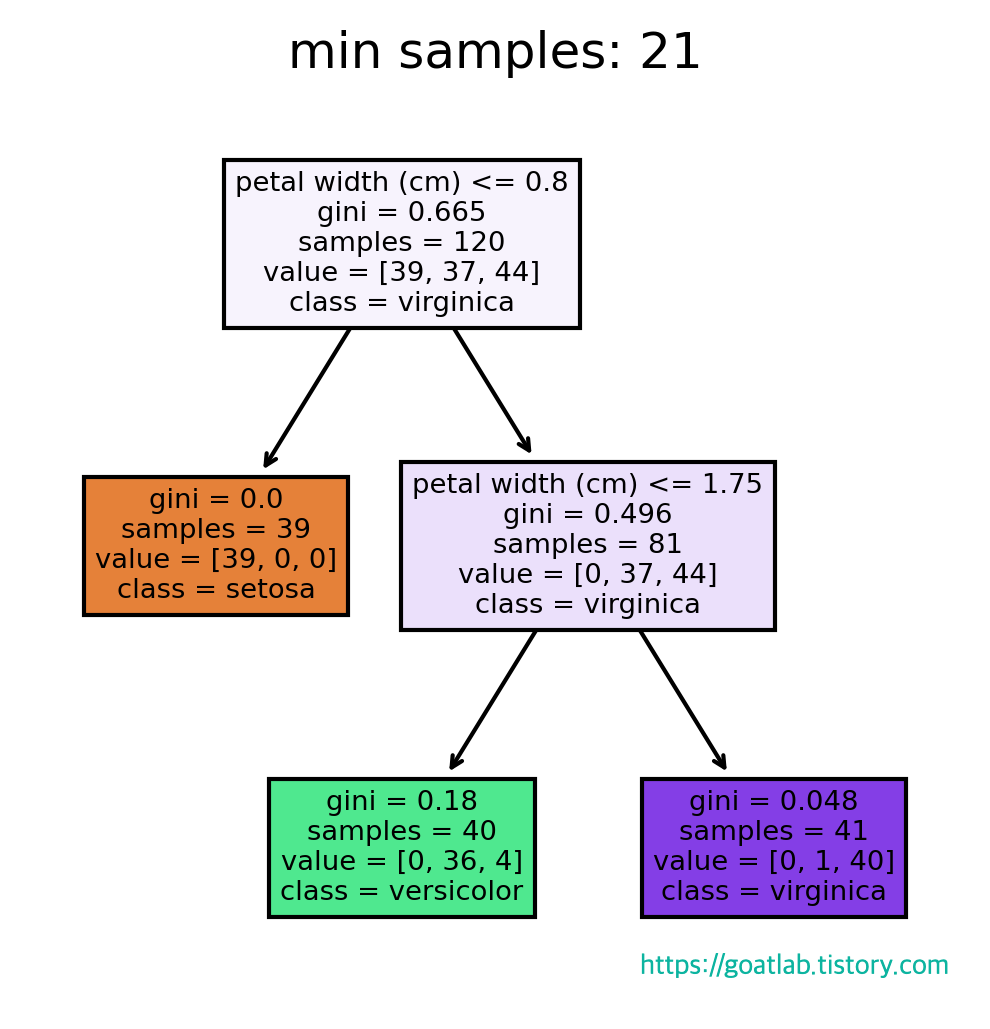
for min_samples in range(1, 31, 10):
test_tree_clf = DecisionTreeClassifier(random_state=0, min_samples_leaf=min_samples)
test_tree_clf.fit(train_x, train_y)
fn = iris_dt.feature_names # 각 특징의 이름
cn = iris_dt.target_names # 꽃의 이름
fig, axes = plt.subplots(nrows=1, ncols=1, figsize=(4,4), dpi=300) # figure 모양을 설정
tree.plot_tree(test_tree_clf,
feature_names=fn,
class_names=cn,
filled=True)
plt.title(f"min samples: {min_samples}")
plt.show()
728x90
반응형
LIST
'Learning-driven Methodology > ML (Machine Learning)' 카테고리의 다른 글
| [Machine Learning] 사용자기반 협업 필터링 (User-based Filtering) (0) | 2022.12.07 |
|---|---|
| [Machine Learning] 추천 시스템 (Recommender System) (0) | 2022.12.07 |
| [Machine Learning] 이상 탐지 (Anomaly Detection) (0) | 2022.11.17 |
| [Machine Learning] 오토인코더 (Autoencoder) (0) | 2022.11.11 |
| [XGBoost] 보험료 예측 (0) | 2022.10.05 |



