스타일 전송 (Style Transfer)
Style Transfer는 주로 스타일 이미지가 주어졌을 때 같은 부류에 속한 것 같은 느낌을 주도록 입력 이미지를 변환하는 모델을 훈련하는 것이다. 이 기술은 상업 어플리케이션에 주로 도입되어 스마트폰 어플리케이션, 컴퓨터 게임 디자인 등 많은 곳에서 쓰인다.

Style Transfer는 스타일 이미지에 내재된 분포를 모델링하는 것이 아니라 이미지에서 스타일을 결정하는 요소만 추출하여 입력 이미지에 주입하는 것이다. 또한, 하나의 이미지를 사용하는 것이 아니라 스타일 이미지 세트 전체에서 아티스트의 스타일을 잡아낸다. 따라서, 모델이 전체 이미지셋에 걸쳐 사용된 스타일을 학습하기 위한 방법을 찾아야 한다.

Style Transfer는 여러가지 모델로 달성될 수 있다. 그 중 하나인 Neural Style Transfer는 2015년 리온 게티스에 의해 제안된 방법으로 입력 이미지의 콘텐츠는 보존하면서 참조 이미지의 스타일을 입력 이미지에 적용하는 방식이다.

Style Transfer의 핵심 개념은 CNN을 사용하는 딥러닝의 알고리즘 핵심과 동일하다. 하지만 기존에 각각의 layer가 feature를 생성하고 이를 쌓아 깊어진 layer로부터 더 좋은 feature를 만들어내는 방식과 달리 생성한 feature map으로부터 이미지를 재구성한다. 이때, 네트워크의 하위층은 local information을 나타내고 상위 층은 global information을 나타내기 때문에 입력 이미지는 전체적으로 추상적인 정 보를 나타내는 상위 층의 layer에 존재한다.

입력 이미지와 convolution 레이어에 대해 위와 같이 feature map F를 추출할 수 있다. 레이어가 깊어질수록 픽셀 수준의 정보는 사라지지만, 입력 이미지가 가진 semantic 정보는 유지된다. 따라서, 깊은 레이어에서 content feature를 추출한다.

Style Transfer는 콘텐츠 손실, 스타일 손실, 총 변위 손실의 세 부분으로 구성된 손실 함수의 가중치 합을 기반으로 작동한다. 경사 하강법으로 전체 손실을 최소화한다. 즉, 많은 반복을 통해 손실 함수의 음 의 gradient 양에 비례하여 픽셀 값을 업데이트한다. 반복이 진행됨에 따라 손실은 점차 줄어들어 입력 영상의 콘텐츠와 스타일 영상을 합친 합성 영상을 얻게 될 것이다.
콘텐츠 손실
콘텐츠 손실은 콘텐츠의 내용과 전반적인 사물의 배치 측면에서 두 영상이 얼마나 다른지를 측정한다. 비슷한 장면을 담은 두 영상은 완전히 다른 장면을 포함하는 두 영상보다 손실이 작아야 한다. 두 영상의 픽셀값을 비교하는 것만으로는 부족하다. 두 영상의 장면이 같더라도 개별 픽셀값이 비슷할 것으로 기대할 수 없기 때문이다. 콘텐츠 손실은 개별 픽셀값과 무관해야 한다. 건물과 같은 고차원 특성의 존재와 대략적인 위치를 기반으로 이미지를 점수화해야한다.
영상의 내용을 인식하도록 훈련된 신경망은 이전 층의 단순한 특성을 결합하여 네트워크의 더 깊은 층에서 자연스럽게 더 높은 수준의 특성을 학습한다. 따라서, 영상의 내용을 식별하도록 성공적으로 훈련 된 심층 신경망이 필요하다. 네트워크의 깊은 층으로부터 주어진 입력 영상에 대한 높은 수준의 특성을 추출할 수 있다. 입력 영상과 현재 합성된 영상에 대해 이 출력을 계산하여 그 사이의 평균 제곱 오차를 측정하면 콘텐츠 손실 함수가 된다.
Neural Style Transfer에서 사용되는 사전 훈련 네트워크는 VGG19이다. 이때의 vgg19는 기존 모델과 다르게 average pooling을 사용하는데 이는 실험을 통해 기존의 max pooling보다 더 좋은 결과가 나왔기 때문이다.
스타일 손실
스타일이 비슷한 영상은 특정 층의 특성 맵 사이에 동일한 상관관계 패턴을 가진다는 아이디어를 기반으로 스타일 유사도를 측정한다.
두 개의 특성 맵 (feature map)이 얼마나 동시에 활성화되는지 수치적으로 측정하기 위해 특성 맵을 펼치고 스칼라 곱을 계산하여 이 값이 크면 특성 맵 사이의 상관 관계가 크고, 값이 작으면 특성 맵 사이의 상관 관계가 없다.
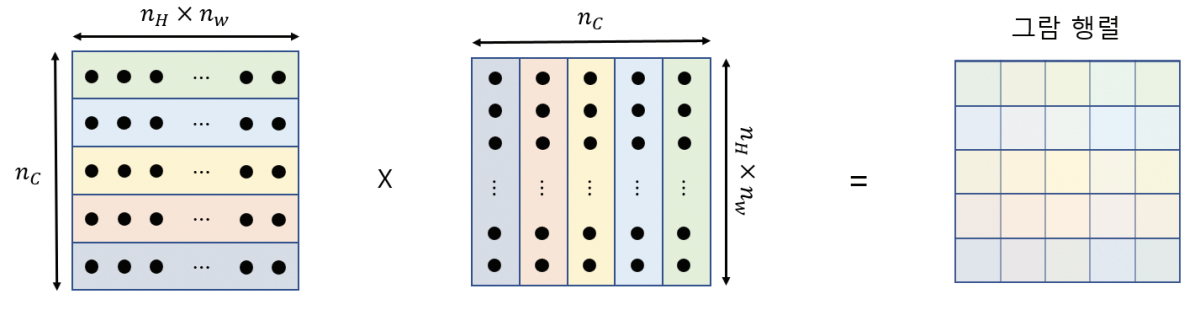
층에 있는 모든 특성 사이의 스칼라 곱을 담은 행렬을 그람 행렬이라고 정의한다. 다음과 같이 정의될 수 있다.
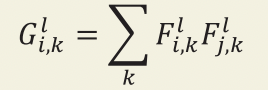
스타일 손실을 계산하려면 입력 영상과 합성된 영상에 대해 네트워크의 여러 층에서 그람 행렬을 계산 해야 한다. 그 다음, 두 그람 행렬의 제곱 오차 합을 사용하여 유사도를 비교할 수 있다. 입력 이미지 (S)와 생성된 이미지 (G) 사이의 스타일 손실은 크기가 𝑚l (높이 × 너비)이고 𝑁l 개의 채널을 가진 층 (𝑙)을 이용해 다음과 같은 수식으로 쓸 수 있다.
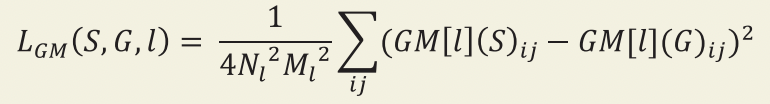
그리고 두 영상의 전체 스타일 손실은 크기가 다른 여러 층에서 계산한 스타일의 가중치 합이다. 채널 의 수 (𝑁l)와 층의 크기 (𝑀l)로 스케일을 조정해 다음과 같이 계산한다.
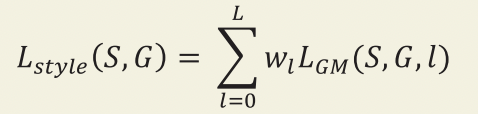
Content loss와 Style loss를 결합한 손실 함수는 다음과 같다.

이때, 가중치를 어떻게 적용하냐에 따라 다른 이미지 x가 생성된다.

위의 그림처럼 style loss에 가중치를 많이 두면 (좌측 상단), 스타일 중심적인 이미지가 생성되는 반면, content loss에 가중치를 두면 (우측 하단) 컨텐츠 중심적인 이미지가 생성된다.
총 변위 손실
총 변위 손실은 단순히 합성된 영상에 있는 잡음을 측정한 것이다. 영상의 잡음을 측정하기 위해 오른 쪽으로 한 픽셀을 이동하고 원본 영상과 이동한 영상 간의 차이를 제곱하여 더한다. 균형을 맞추기 위 해 동일한 작업을 한 픽셀 아래로 이동하여 수행하고, 이 두 항의 합이 총 변위 손실이다.
'Visual Intelligence > Generative Model' 카테고리의 다른 글
| [Generative Model] GAN (Generative Adversarial Network) (0) | 2022.12.09 |
|---|---|
| [Generative Model] Neural style transfer (0) | 2022.12.09 |
| [Generative Model] VAE (MNIST) (0) | 2022.12.08 |
| [Generative Model] VAE (Variational AutoEncoder) (0) | 2022.12.08 |
| [Generative Model] 오토인코더 (MNIST) (0) | 2022.12.08 |



