VAE (Variational AutoEncoder)
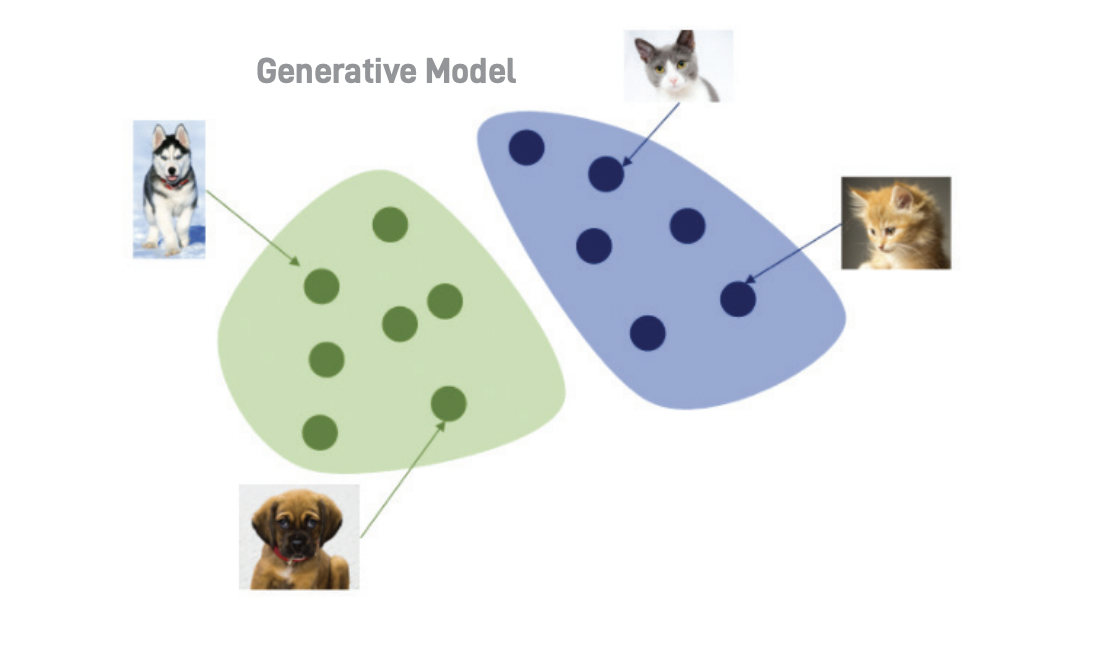
생성 모델 (Generative Model)이란 새로운 data instance를 생성하는 모델이다. 즉, 학습 데이터의 분포도를 근사하는 특성을 가지고 있다. 예를 들어, 고양이, 강아지의 이미지 데이터를 생성 모델의 입력으로 준다면 입력 데이터와 상당히 유사한 분포를 갖는 새로운 이미지를 얻게 된다.
| 수학적으로 Autoencoder와 Variational Autoencoder는 전혀 관계가 없다. •Autoencoder의 목적은 Manifold learning이다. - AE는 네트워크의 앞단을 학습하기 위해 뒷단을 붙임 - 입력 데이터의 압축을 통해 데이터의 의미 있는 manifold를 학습한다. •Variational Autoencoder는 Generative Model이다. - 뒷단을 학습시키기 위해 앞단을 붙임 |
생성 모델인 VAE는 latent space를 단순한 수의 집합이 아닌 학습된 평균과 표준편차를 지닌 분포로 표현한다. VAE는 베이즈 이론에 기반한 머신 러닝 기법으로 이는 실제 분포를 학습해야 한다는 뜻이다. 이 때문에 제약이 추가된다.
| 베이지안 확률 (Bayesian Probability) 세상에 반복할 수 없는 혹은 알 수 없는 확률들, 일어나지 않은 일에 대한 확률을 사건이 있는 여러 확률들을 이용해 알고 싶은 사건을 추정하는 것 |
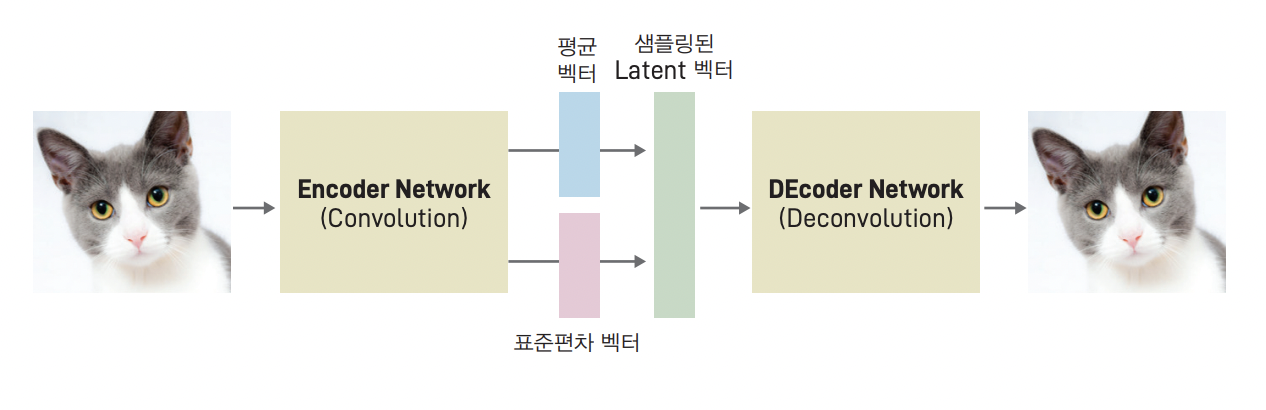
VAE는 잠재 공간의 차원 사이에는 어떤 상관 관계가 없다고 가정한다. 따라서, 공분산 행렬은 대각 행렬이 된다. 이는 인코더가 각 입력을 평균 벡터와 분산 벡터에만 매핑할 필요가 있다는 것을 뜻한다. 차원 간의 공분산에 대해 신경 쓰지 않아도 된다. 신경망 유닛의 일반적인 출력은 (-∞, ∞) 범위의 모든 실수이지만 분산은 항상 양수이기 때문에 분산에 로그를 취한 값에 매핑한다.
요약하면, 인코더는 입력 이미지를 받아 잠재 공간의 다변수 정규 분포를 정의하는 2개의 벡터 𝑚𝑢 (해당 분포의 평균 벡터)와 log _𝑣𝑎𝑟 (차원별 분산의 로그값)로 인코딩한다.
이미지를 잠재 공간의 특정 포인트 𝑧로 인코딩하기 위해 이 분포에서 샘플링을 한다.
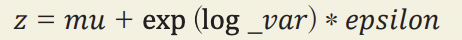
식에서는 작은 수인 epsilon을 mu에서 얼마나 떨어져 표시해야 하는지 나타낸다. 이런 작은 변화를 통해 인코더를 향상시킬 수 있다. AutoEncoder에서는 잠재 공간을 연속적으로 만들 필요가 없었다.
포인트 (-2, 2)가 제대로 된 숫자 4의 이미지로 디코딩하더라도 (-2.1, 2.1)이 비슷해야 할 필요가 없다. 𝑚𝑢 주변의 지역에서 무작위의 포인트를 샘플링하기 때문에 디코더는 재구성 손실이 작게 유지되도록 같은 영역에 위치한 포인트를 매우 비슷한 이미지로 디코딩해야 한다. 잠재 공간에서 디코더가 본 적이 없는 포인트를 선택하더라도 제대로 된 이미지를 디코딩할 수 있는 매우 훌륭한 성질이다.
재구성 손실 (Reconstruction Loss)
원본 이미지와 인코더와 디코더를 통과한 재구성 사이의 손실로만 구성되었다. 이를 재구성 손실 (Reconstruction Loss)라 하며 VAE에도 사용된다. VAE는 추가적으로 쿨백-라이블러 발산 (Kullback-Leibler divergence, KL 발산)을 사용한다.
KL 발산은 한 확률 분포가 다른 분포와 얼마나 다른지 측정하는 도구다. VAE에서 평균이 mu이고 분 산이 log _𝑣𝑎𝑟인 정규 분포가 표준 정규 분포와 얼마나 다른지를 측정해야 한다. 이런 경우에 KL 발산은 다음과 같이 계산된다.
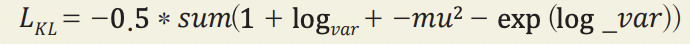
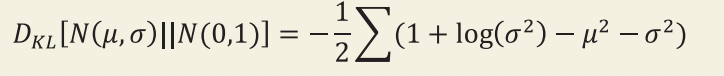
이 식의 덧셈은 잠재 공간의 모든 차원에 대해 수행된다. 모든 차원의 mu=0이고 log _𝑣𝑎𝑟=0일 때 𝐿𝐾𝐿가 최소이다. 이 두 항이 0에서 멀어지면 𝐿𝐾𝐿는 증가한다. 요약하면, 𝐾𝐿 발산항은 샘플을 표준 정규 분포 (𝑚𝑢=0, | log _𝑣𝑎𝑟=0)에서 크게 벗어난 𝑚𝑢와 log _𝑣𝑎𝑟 변수로 인코딩하는 네트워크에 손실을 가한다.
손실 함수에 𝐾𝐿 발산항을 추가함으로써 두가지 이점이 있다. 첫째로 잠재 공간에서 포인트를 선택할 때 사용할 수 있는 표준 정규 분포를 가지게 된다. 이 분포에서 샘플링하면 VAE가 바라보고 있는 영역 안의 포인트를 선택할 가능성이 매우 높다. 둘째, 이 항이 모든 인코딩된 데이터 분포를 표준 정규 분포 에 가깝게 되도록 강제한다. 이로 인해 포인트 군집 사이에 큰 간격이 생길 가능성이 적다. 대신 인코더는 원점 주변의 공간을 대칭적이고 효과적으로 사용하려고 한다.
'Visual Intelligence > Generative Model' 카테고리의 다른 글
| [Generative Model] 스타일 전송 (Style Transfer) (0) | 2022.12.09 |
|---|---|
| [Generative Model] VAE (MNIST) (0) | 2022.12.08 |
| [Generative Model] 오토인코더 (MNIST) (0) | 2022.12.08 |
| [Generative Model] 오토인코더 (AutoEncoder) (0) | 2022.12.08 |
| 생성 모델 (Generative Model) (0) | 2022.12.08 |



