평가 모델
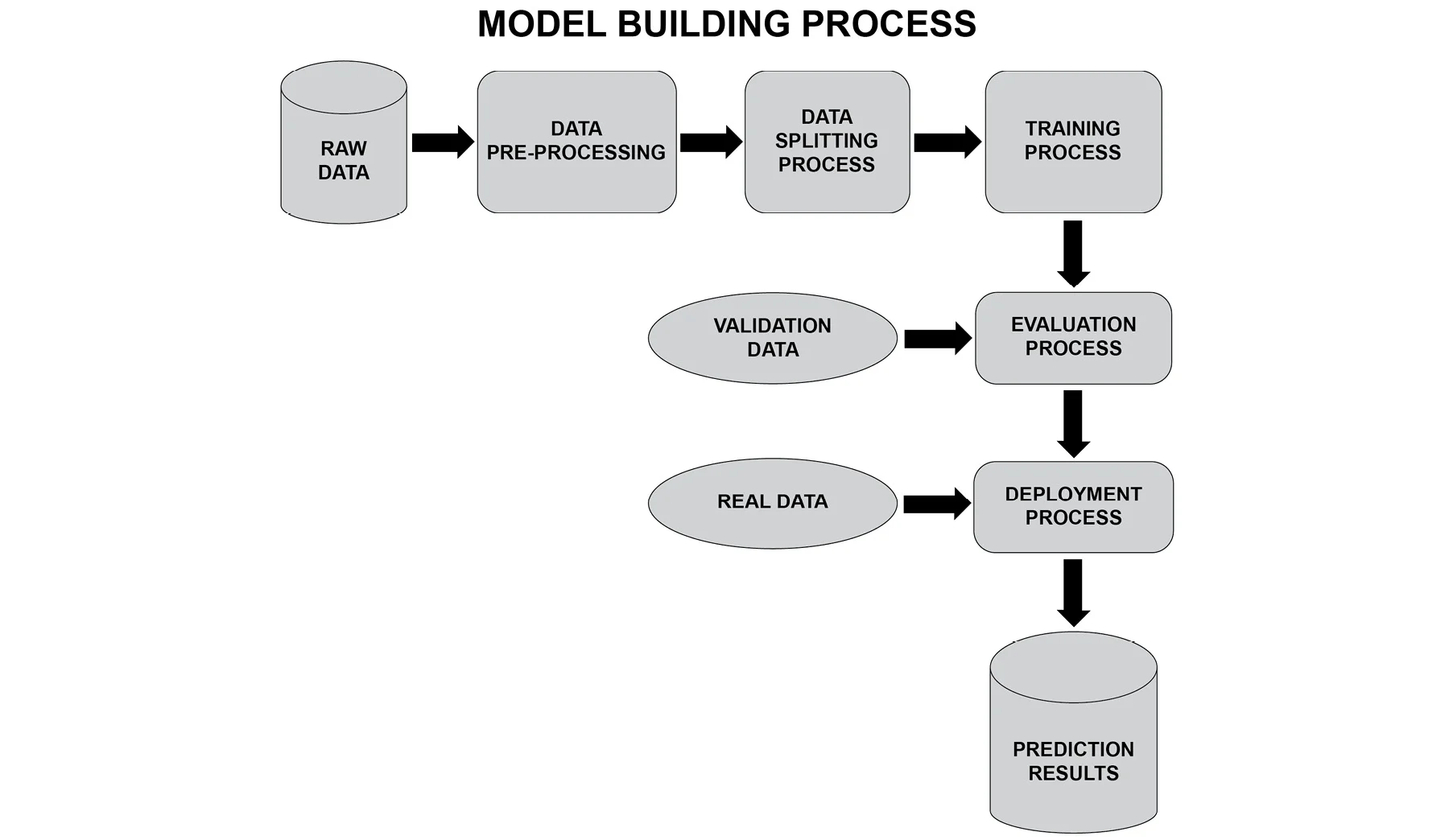
머신러닝에서 각각의 알고리즘이 특성, 차이가 있기 때문에 모델을 평가할 지표가 필요하다. 평가 모델은 다음과 같다.
|
데이터 분리

훈련 / 테스트 분할 (train / test split)은 머신러닝에서 데이터를 학습을 하기 위한 학습 데이터셋 (train dataset)과 학습의 결과로 생성된 모델의 성능을 평가하기 위한 테스트 데이터셋 (test dataset)으로 나눈다. 모델이 새로운 데이터셋에도 일반화 (generalize)하여 처리할 수 있는지를 확한다.
Error Analysis
오류 분석은 잘못된 ML 예측을 분리, 관찰 및 진단하여 모델의 고성능 및 저성능 포켓을 이해하는 데 도움이 되는 프로세스이다. "모델 정확도가 90%"라고 하면 데이터의 부분군에 걸쳐 균일하지 않을 수 있고 모형이 더 실패하는 일부 입력 조건이 있을 수 있다. 따라서, 이는 집계 metric에서 개선을 위한 모델 오류에 대한 보다 심층적인 검토로 이어지는 단계이다.
| 분류 (Classification) |
|
| 회귀 (Regression) |
|
Confusion Matrix
Confusion Matrix은 예측값이 실제값 대비 얼마나 잘 맞는지 행렬로 표현한 것이다.

|
from sklearn.metrics import confusion_matrix
y_true = [1, 0, 1, 1, 0, 1]
y_pred = [0, 0, 1, 1, 0, 1]
confusion_matrix(y_true, y_pred)array([[2, 0],
[1, 3]], dtype=int64)tn, fp, fn, tp = confusion_matrix(y_true, y_pred).ravel()
(tn, fp, fn, tp)(2, 0, 1, 3)
Accuracy
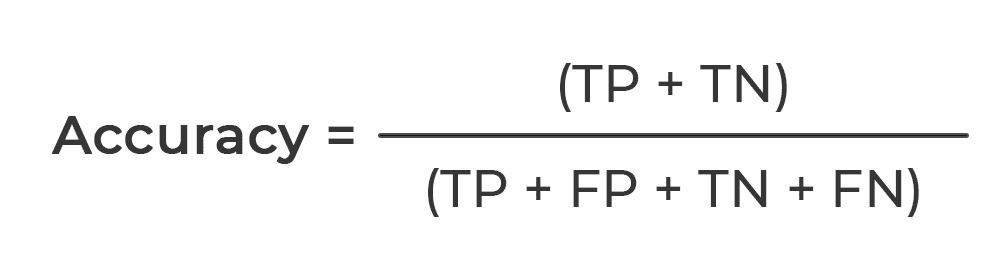
정확도는 검정 데이터에 대한 정확한 예측 비율이다. 정확한 예측 수를 총 예측 수로 나누면 쉽게 계산할 수 있다.
import numpy as np
from sklearn.metrics import accuracy_score
y_true = np.array([0, 1, 0, 0])
y_pred = np.array([0, 1, 1, 0])
accuracy_score(y_true, y_pred)
# 또는
sum(y_true == y_pred) / len(y_true)0.75
Error Analysis for Machine Learning Classification Models
Error are redundant for any machine learning model. This article is a quick quide to Error Analysis for ML Classification Models
www.analyticsvidhya.com
'AI-driven Methodology > Artificial Intelligence' 카테고리의 다른 글
| [AI] 평가 모델 (3) (0) | 2022.09.27 |
|---|---|
| [AI] 평가 모델 (2) (0) | 2022.09.27 |
| [AI] 인공지능의 역사 (주요 응용 분야) (4) (0) | 2022.09.17 |
| [AI] 인공지능의 역사 (3) (0) | 2022.09.17 |
| [AI] 인공지능의 역사 (2) (0) | 2022.09.15 |



