군집 분석 (Clustering)

주어진 데이터 집합을 유사한 데이터들의 그룹으로 나누는 것을 군집화 (clustering)라 하고 이렇게 나누어진 유사한 데이터의 그룹을 군집 (cluster)이라 한다. 군집화는 예측 문제와 달리 특정한 독립변수와 종속변수의 구분도 없고 학습을 위한 목푯값도 필요로 하지 않는 비지도학습의 일종이다.
군집화 방법
군집화 방법에는 목적과 방법에 따라 다양한 모형이 존재한다.
|
군집화 방법은 사용법과 모수 등이 서로 다르다. 예를 들어 K-평균법이나 스펙트럴 군집화 등은 군집의 개수를 미리 지정해주어햐 하지만 디비스캔이나 유사도 전파법 등은 군집의 개수를 지정할 필요가 없다. 다만 이 경우에는 모형에 따라 특별한 모수를 지정해주어야 하는데 이 모수의 값에 따라 군집화 개수가 달라질 수 있다.
군집화 방법마다 특성이 다르므로 원하는 목적과 데이터 유형에 맞게 사용해야 한다. 또한 지정된 모수의 값에 따라 성능이 달라질 수 있다. 이 결과는 최적화된 모수를 사용한 결과는 아니라는 점에 유의해야 한다.
from sklearn.datasets import *
from sklearn.cluster import *
from sklearn.preprocessing import StandardScaler
from sklearn.utils.testing import ignore_warnings
np.random.seed(0)
n_samples = 1500
blobs = make_blobs(n_samples=n_samples, random_state=8)
X, y = make_blobs(n_samples=n_samples, random_state=170)
anisotropic = (np.dot(X, [[0.6, -0.6], [-0.4, 0.8]]), y)
varied = make_blobs(n_samples=n_samples, cluster_std=[1.0, 2.5, 0.5], random_state=170)
noisy_circles = make_circles(n_samples=n_samples, factor=.5, noise=.05)
noisy_moons = make_moons(n_samples=n_samples, noise=.05)
no_structure = np.random.rand(n_samples, 2), None
datasets = {
"같은 크기의 원형": blobs,
"같은 크기의 타원형": anisotropic,
"다른 크기의 원형": varied,
"초승달": noisy_moons,
"동심원": noisy_circles,
"비구조화": no_structure
}
plt.figure(figsize=(11, 11))
plot_num = 1
for i, (data_name, (X, y)) in enumerate(datasets.items()):
if data_name in ["초승달", "동심원"]:
n_clusters = 2
else:
n_clusters = 3
X = StandardScaler().fit_transform(X)
two_means = MiniBatchKMeans(n_clusters=n_clusters)
dbscan = DBSCAN(eps=0.15)
spectral = SpectralClustering(n_clusters=n_clusters, affinity="nearest_neighbors")
ward = AgglomerativeClustering(n_clusters=n_clusters)
affinity_propagation = AffinityPropagation(damping=0.9, preference=-200)
clustering_algorithms = (
('K-Means', two_means),
('DBSCAN', dbscan),
('Hierarchical Clustering', ward),
('Affinity Propagation', affinity_propagation),
('Spectral Clustering', spectral),
)
for j, (name, algorithm) in enumerate(clustering_algorithms):
with ignore_warnings(category=UserWarning):
algorithm.fit(X)
if hasattr(algorithm, 'labels_'):
y_pred = algorithm.labels_.astype(np.int)
else:
y_pred = algorithm.predict(X)
plt.subplot(len(datasets), len(clustering_algorithms), plot_num)
if i == 0:
plt.title(name)
if j == 0:
plt.ylabel(data_name)
colors = plt.cm.tab10(np.arange(20, dtype=int))
plt.scatter(X[:, 0], X[:, 1], s=5, color=colors[y_pred])
plt.xlim(-2.5, 2.5)
plt.ylim(-2.5, 2.5)
plt.xticks(())
plt.yticks(())
plot_num += 1
plt.tight_layout()
plt.show()
군집화 성능기준
군집화의 경우에는 분류문제와 달리 성능기준을 만들기 어렵다. 심지어는 원래 데이터가 어떻게 군집화되어 있었는지를 보여주는 정답 (groundtruth)이 있는 경우도 마찬가지이다. 따라서 다양한 성능기준이 사용되고 있다. 다음의 군집화 성능기준의 예다.
|
일치행렬
랜드지수를 구하려면 데이터가 원래 어떻게 군집화되어 있어야 하는지를 알려주는 정답 (groundtruth)이 있어야 한다. 𝑁개의 데이터 집합에서 𝑖, 𝑗 두 개의 데이터를 선택하였을 때 그 두 데이터가 같은 군집에 속하면 1 다른 데이터에 속하면 0이라고 하자. 이 값을 𝑁×𝑁 행렬 𝑇로 나타내면 다음과 같다.

랜드지수
랜드지수 (Rand Index, RI)는 가능한 모든 데이터 쌍의 개수에 대해 정답인 데이터 쌍의 개수의 비율로 정의한다.

조정 랜드지수
랜드지수는 0부터 1까지의 값을 가지고 1이 가장 좋은 성능을 뜻한다. 랜드지수의 문제점은 무작위로 군집화을 한 경우에도 어느 정도 좋은 값이 나올 가능성이 높다는 점이다. 즉 무작위 군집화에서 생기는 랜드지수의 기댓값이 너무 크다. 이를 해결하기 위해 무작위 군집화에서 생기는 랜드지수의 기댓값을 원래의 값에서 빼서 기댓값과 분산을 재조정한 것이 조정 랜드지수 (adjusted Rand index, ARI)다.
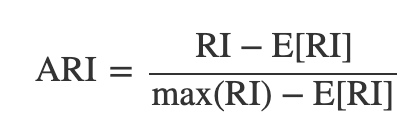
adjusted Rand index는 성능이 완벽한 경우 1이 된다. 반대로 가장 나쁜 경우로서 무작위 군집화을 하면 0에 가까운 값이 나온다. 경우에 따라서는 음수가 나올 수도 있다.
여러가지 군집화 방법을 적용하였을때 조정 랜드지수를 계산해보면 디비스캔과 스펙트럴 군집화의 값이 높게 나오는 것을 확인할 수 있다. scikit-learn 패키지의 metrics.cluster 서브패키지는 조정 랜드지수를 계산하는 adjusted_rand_score 명령을 제공한다.
from sklearn.metrics.cluster import adjusted_rand_score
X, y_true = anisotropic
plt.figure(figsize=(12, 2))
plot_num = 1
X = StandardScaler().fit_transform(X)
for name, algorithm in clustering_algorithms:
with ignore_warnings(category=UserWarning):
algorithm.fit(X)
if hasattr(algorithm, 'labels_'):
y_pred = algorithm.labels_.astype(np.int)
else:
y_pred = algorithm.predict(X)
title = "ARI={:5.3f}".format(adjusted_rand_score(y_true, y_pred))
plt.subplot(1, len(datasets), plot_num)
plt.scatter(X[:, 0], X[:, 1], s=5, color=colors[y_pred])
plt.xlim(-2.5, 2.5)
plt.ylim(-2.5, 2.5)
plt.xticks(())
plt.yticks(())
plt.title(title)
plot_num += 1
조정 상호정보량
상호정보량 (mutual information)은 두 확률변수간의 상호 의존성을 측정한 값이다. 군집화 결과를 이산확률변수라고 가정한다.
실루엣계수
지금까지는 각각의 데이터가 원래 어떤 군집에 속해있었는지 정답 (groundtruth)를 알고 있는 경우를 다루었다. 하지만 이러한 정답 정보가 없다면 어떻게 군집화이 잘되었는지 판단하기 위해 실루엣계수 (Silhouette coefficient)는 이러한 경우에 군집화의 성능을 판단하는 기준의 하나이다.
https://datascienceschool.net/03%20machine%20learning/16.01%20%EA%B5%B0%EC%A7%91%ED%99%94.html
군집화 — 데이터 사이언스 스쿨
.ipynb .pdf to have style consistency -->
datascienceschool.net
'Learning-driven Methodology > ML (Machine Learning)' 카테고리의 다른 글
| 06. 나이브 베이즈 (Naive Bayes) (0) | 2021.12.15 |
|---|---|
| 06. KNN (K-Nearest Neighbor) (0) | 2021.12.08 |
| 03. 회귀분석 (Regression Analysis) (0) | 2021.12.08 |
| 02. 의사결정 트리 (Decision Tree) (0) | 2021.12.08 |
| 01. Intro (0) | 2021.12.08 |



