의사결정 트리 (Decision Tree)
의사결정 트리 (decision tree)는 여러 가지 규칙을 순차적으로 적용하면서 독립 변수 공간을 분할하는 분류 모형이다. 분류 (classification)와 회귀 분석 (regression)에 모두 사용될 수 있기 때문에 CART (Classification And Regression Tree)라고도 한다.

의사결정 트리를 이용한 분류학습
|
이렇게 자식 노드 나누기를 연속적으로 적용하면 노드가 계속 증가하는 나무 (tree)와 같은 형태로 표현할 수 있다.
의사결정 트리를 사용한 분류예측
의사결정 트리에 전체 트레이닝 데이터를 모두 적용해 보면 각 데이터는 특정한 노드를 타고 내려가게 된다. 각 노드는 그 노드를 선택한 데이터 집합을 가진다. 이 때 노드에 속한 데이터의 클래스의 비율을 구하여 이를 그 노드의 조건부 확률 분포 𝑃(𝑌=𝑘|𝑋) node라고 정의한다.

테스트 데이터 𝑋test의 클래스를 예측할 때는 가장 상위의 노드부터 분류 규칙을 차례대로 적용하여 마지막에 도달하는 노드의 조건부 확률 분포를 이용하여 클래스를 예측한다.

분류규칙을 정하는 방법
분류 규칙을 정하는 방법은 부모 노드와 자식 노드 간의 엔트로피를 가장 낮게 만드는 최상의 독립 변수와 기준값을 찾는 것이다. 이러한 기준을 정량화한 것이 정보획득량 (information gain)이다. 기본적으로 모든 독립 변수와 모든 가능한 기준값에 대해 정보획득량을 구하여 가장 정보획득량이 큰 독립 변수와 기준값을 선택한다.
정보 획득량
정보 획득량 (information gain)는 𝑋라는 조건에 의해 확률 변수 𝑌의 엔트로피가 얼마나 감소하였는가를 나타내는 값이다. 다음처럼 𝑌의 엔트로피에서 𝑋에 대한 𝑌의 조건부 엔트로피를 뺀 값으로 정의된다.

Scikit-Learn의 의사결정 트리 클래스
Scikit-Learn에서 의사결정트리는 DecisionTreeClassifier 클래스로 구현되어있다.
import io
import pydot
from IPython.core.display import Image
from sklearn.tree import export_graphviz
def draw_decision_tree(model):
dot_buf = io.StringIO()
export_graphviz(model, out_file=dot_buf, feature_names=feature_names)
graph = pydot.graph_from_dot_data(dot_buf.getvalue())[0]
image = graph.create_png()
return Image(image)
def plot_decision_regions(X, y, model, title):
resolution = 0.01
markers = ('s', '^', 'o')
colors = ('red', 'blue', 'lightgreen')
cmap = mpl.colors.ListedColormap(colors)
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
Z = model.predict(
np.array([xx1.ravel(), xx2.ravel()]).T).reshape(xx1.shape)
plt.contour(xx1, xx2, Z, cmap=mpl.colors.ListedColormap(['k']))
plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1], alpha=0.8,
c=[cmap(idx)], marker=markers[idx], s=80, label=cl)
plt.xlabel(data.feature_names[2])
plt.ylabel(data.feature_names[3])
plt.legend(loc='upper left')
plt.title(title)
return Z
draw_decision_tree(tree1)
plot_decision_regions(X, y, tree1, "Depth 1")
plt.show()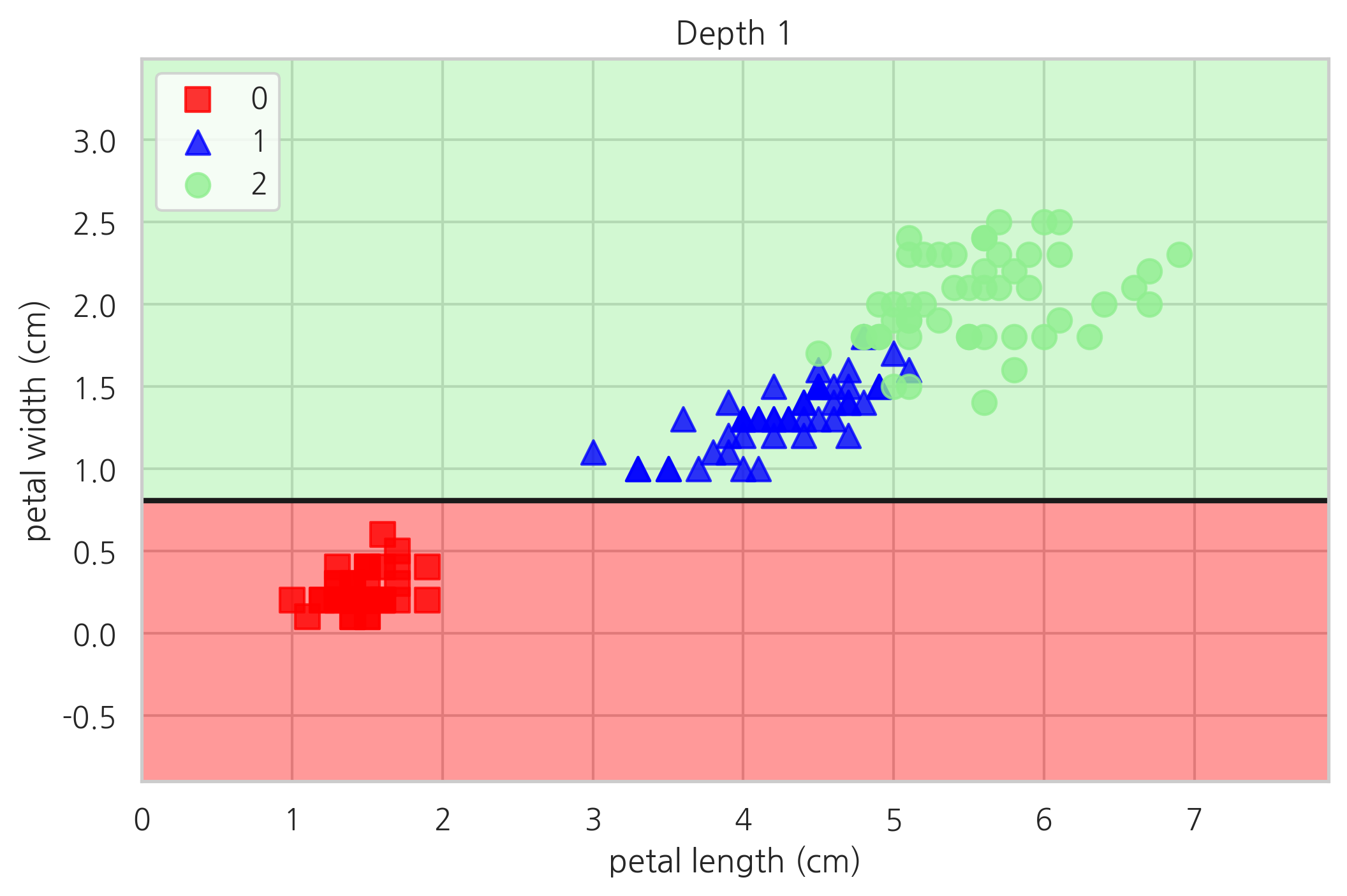
Greedy 의사 결정
의사결정나무의 문제점 중 하나는 특징의 선택이 greedy한 방식으로 이루어지기 때문에 선택된 특징이 최적의 선택이 아닐 수도 있다는 점이다.
회귀 트리
예측값 𝑦̂ 을 다음처럼 각 특징값 영역마다 고정된 값 𝑦1,𝑦2를 사용하고,
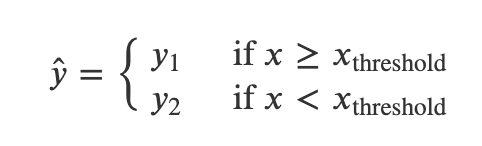
8.1 의사결정나무 — 데이터 사이언스 스쿨
.ipynb .pdf to have style consistency -->
datascienceschool.net
'Learning-driven Methodology > ML (Machine Learning)' 카테고리의 다른 글
| 06. 나이브 베이즈 (Naive Bayes) (0) | 2021.12.15 |
|---|---|
| 06. KNN (K-Nearest Neighbor) (0) | 2021.12.08 |
| 04. 군집 분석 (Clustering) (0) | 2021.12.08 |
| 03. 회귀분석 (Regression Analysis) (0) | 2021.12.08 |
| 01. Intro (0) | 2021.12.08 |



