Removing the First Level
pd.concat 함수에는 drop_first라는 매개 변수도 포함되어 있는데, 첫 번째 수준을 제거함으로써 k-1 더미를 k개의 범주형 수준에서 벗어나게 할지 여부를 지정한다. 이 경우 첫 번째 수준인 area_a를 제거하고자 하는 이유는 보통 사용되지 않는 [0,0,0]의 인코딩을 사용함으로써 더 효율적인 인코딩을 제공한다. area를 단지 세 개의 열로 인코딩하고 a의 범주형 값을 [0,0,0]으로 매핑한다.
import pandas as pd
dummies = pd.get_dummies(['a', 'b', 'c', 'd'], prefix = 'area', drop_first = True)
print(dummies)
위의 데이터에서 볼 수 있듯이 area_a 열이 누락되어 get_dummys가 [0, 0, 0]의 인코딩으로 대체했다. 다음 코드는 이 기법을 데이터 프레임에 적용하는 방법을 보여준다.
import os
import pandas as pd
from scipy.stats import zscore
df = pd.read_csv('jh-simple-dataset.csv', na_values = ['NA', '?'])
dummies = pd.get_dummies(df['area'], drop_first = True, prefix = 'area')
df = pd.concat([df, dummies], axis = 1)
df.drop('area', axis = 1, inplace = True)
pd.set_option('display.max_columns', 0)
pd.set_option('display.max_rows', 10)
display(df[['id', 'job', 'income', 'area_b', 'area_c', 'area_d']])
Target Encoding for Categoricals
타겟 인코딩은 Kaggle 대회에서 인기 있는 기술이다. 타겟 인코딩은 때때로 기계 학습 모델의 예측력을 증가시킬 수 있다. 그러나 과적합의 위험 또한 극적으로 증가시킨다. 이러한 위험 때문에 이 방법을 사용할 때 주의해야 한다.
일반적으로 타겟 인코딩은 기계 학습 모델의 출력이 숫자 (회귀)일 때만 범주형 피쳐에 사용될 수 있다. 타켓 인코딩의 개념은 간단히다. 각 범주에 대해 해당 범주에 대한 평균 목표 값을 계산한다. 그런 다음 인코딩하기 위해 범주형 값이 갖는 범주에 해당하는 백분율을 대체한다. 타겟 인코딩이 있는 각 범주에 대한 열이 있는 더미 변수와 달리 프로그램은 단일 열만 있으면 된다. 이러한 방식으로 대상 코딩은 더미 변수보다 더 효율적이다.
import pandas as pd
import numpy as np
np.random.seed(43)
df = pd.DataFrame({'cont_9' : np.random.rand(10) * 100,
'cat_0' : ['dog'] * 5 + ['cat'] * 5,
'cat_1' : ['wolf'] * 9 + ['tiger'] * 1,
'y' : [1, 0, 1, 1, 1, 1, 0, 0, 0, 0]
})
pd.set_option('display.max_columns', 0)
pd.set_option('display.max_rows', 0)
display(df)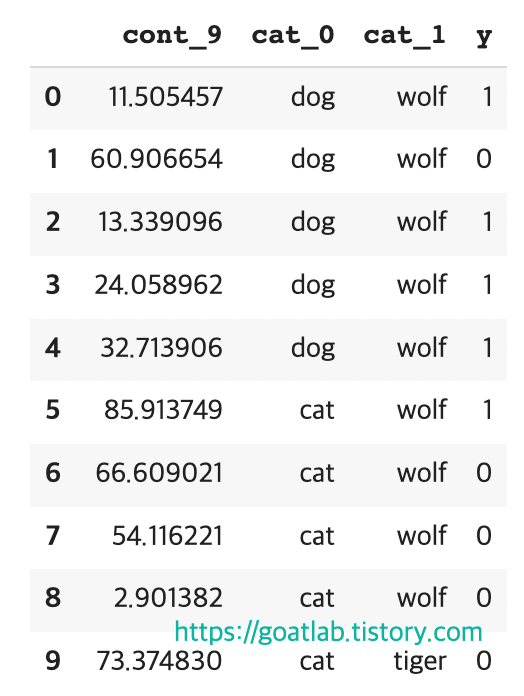
"개"와 "고양이"에 대한 더미 변수를 만드는 대신 숫자로 바꾸고 싶으면 고양이에 대해 0을 사용하고 개에 대해 1을 사용할 수 있다. 그러나 그 이상의 정보를 부호화할 수 있다. 단순한 0이나 1은 또한 한 동물에게만 적용된다. 고양이와 개의 평균 목표 값이 얼마인지 고려해야 한다.
means0 = df.groupby('cat_0')['y'].mean().to_dict()
means0{'cat': 0.2, 'dog': 0.8}
위험한 것은 목표 값 y를 훈련에 사용하고 있다는 것이다. 이 기술은 잠재적으로 과적합을 초래할 수 있다. 특정 범주의 수가 적으면 과적합 가능성이 더 크다. 이를 방지하기 위해 가중치 인자를 사용한다. 가중치가 강할수록 값이 적은 범주가 전체 평균 y로 향한다. 이 계산을 다음과 같이 수행할 수 있다.
df['y'].mean()0.5def calc_smooth_mean(df1, df2, cat_name, target, weight):
# Compute the global mean
mean = df[target].mean()
# Compute the number of values and the mean of each group
agg = df.groupby(cat_name)[target].agg(['count', 'mean'])
counts = agg['count']
means = agg ['mean']
# Compute the "smoothed" means
smooth = (counts * means + weight * mean) / counts + weight
# Replace each value by the according smoothed mean
if df2 is None:
return df1[cat_name].map(smooth)
else:
return df1[cat_name].map(smooth), df2[cat_name].map(smooth.to_dict())
WEIGHT = 5
df['cat_0_enc']= calc_smooth_mean(df1 = df, df2 = None, cat_name = 'cat_0', target = 'y', weight = WEIGHT)
df['cat_1_enc']= calc_smooth_mean(df1 = df, df2 = None, cat_name = 'cat_1', target = 'y', weight = WEIGHT)
pd.set_option('display.max_columns', 0)
pd.set_option('display.max_rows', 0)
display(df)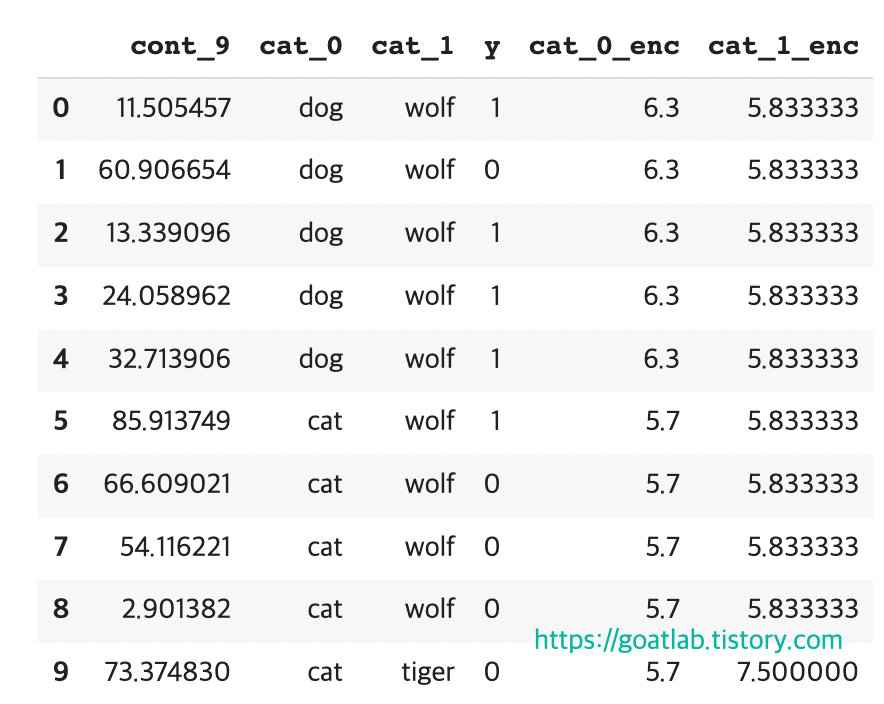
'DNN with Keras > Machine Learning' 카테고리의 다른 글
| 그룹화, 정렬 및 섞기 (2) (0) | 2023.07.27 |
|---|---|
| 그룹화, 정렬 및 섞기 (1) (0) | 2023.07.27 |
| 원핫 인코딩 (One-Hot-Encoding) (0) | 2023.07.27 |
| 범주형 (Categorical) 및 연속형 (Continuous) 값 (0) | 2023.07.27 |
| 데이터프레임 저장 (0) | 2023.07.27 |



