728x90
반응형
SMALL
Categorical and Continuous Values
신경망은 고정된 수의 열이 입력되어야 한다. 이 입력 형식은 스프레드시트 데이터와 매우 유사하다. 신경망이 데이터로부터 학습할 수 있도록 데이터를 표현하는 것이 필수적이다. 데이터를 전처리하는 구체적인 방법을 위해 정의된 4가지 기본 유형의 데이터를 고려하는 것이 중요하다. 통계학자들은 일반적으로 다음과 같은 측정 수준을 말한다.
| 문자 데이터 (문자열) |
|
| 수치 데이터 (Numeric Data) |
|
Encoding Continuous Values
한 가지 일반적인 변환은 입력을 정규화하는 것이다. 때로는 표준 형식으로 숫자 입력을 정규화하여 프로그램이 이 두 값을 쉽게 비교할 수 있도록 하는 것이 중요하다. 백분율은 일반적인 정규화의 한 형태이다. 널리 퍼진 기계 학습 정규화는 Z 점수 (Z-Score)이다.
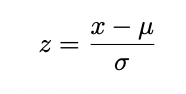
Z-Score를 계산하려면 평균 (µ or x¯)과 표준 편차(σ)를 계산해야 한다. 다음 식으로 평균을 계산할 수 있다.
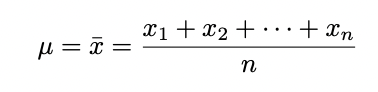
표준 편차 (standard deviation)는 다음과 같이 계산된다.
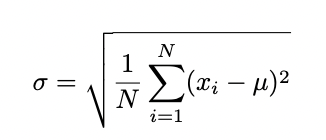
다음 파이썬 코드는 mpg를 z-score로 대체한다. 평균 MPG가 있는 자동차는 0에 가깝고, 0 이상은 평균 이상, 0 이하는 평균 이하이다. 위 또는 아래가 3개 이상인 Z-score는 매우 희귀하다.
import os
import pandas as pd
from scipy.stats import zscore
df = pd.read_csv('auto-mpg.csv', na_values = ['NA', '?'])
pd.set_option('display.max_columns', 7)
pd.set_option('display.max_rows', 5)
df['mpg'] = zscore(df['mpg'])
display(df)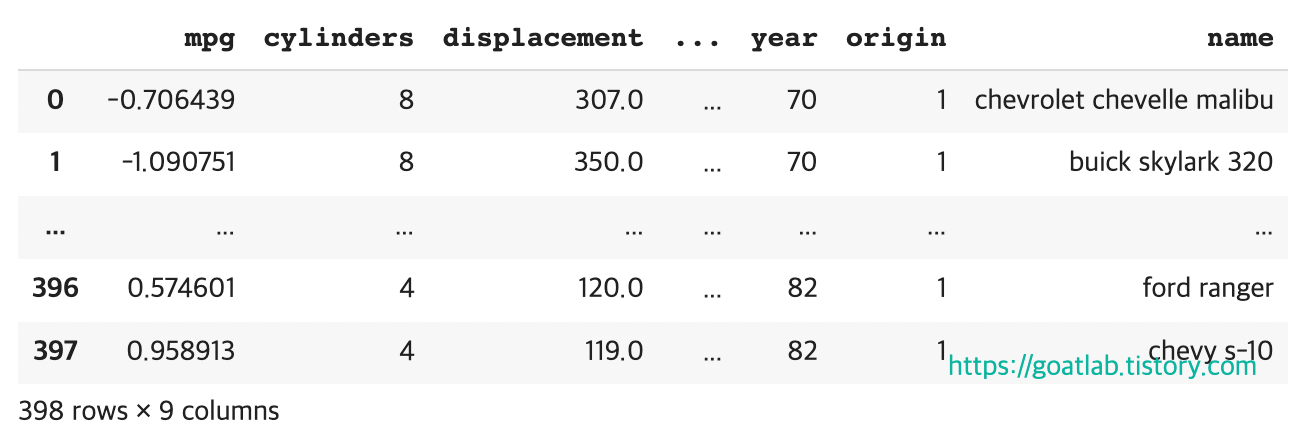
728x90
반응형
LIST
'DNN with Keras > Machine Learning' 카테고리의 다른 글
| 타겟 인코딩 (Target Encoding) (0) | 2023.07.27 |
|---|---|
| 원핫 인코딩 (One-Hot-Encoding) (0) | 2023.07.27 |
| 데이터프레임 저장 (0) | 2023.07.27 |
| 데이터프레임 전처리 (0) | 2023.07.27 |
| Dropping / Concatenating (0) | 2023.07.27 |



