728x90
반응형
SMALL
결측치 (Missing Data)
다른 항목 측정 시 측정되지 않거나, 네트워크 문제로 인해 누락된 값을 말한다. 데이터마다 측정되는 항목 또한 상이하다.
결측치 처리
| 삭제 | 특정 행의 데이터를 삭제하거나 결측치가 많은 특징을 삭제한다. |
| 보간 | 평균값, 최빈값, 중간값 보간 시 훈련 데이터 (training data)를 기준으로 계산하여 검증 데이터 (validation data)나 테스트 데이터 (test data)에 적용 |
당뇨병 데이터 전처리
import numpy as np
import pandas as pd
df = pd.read_csv('Diabetes_Database.csv')
df.head()
결측치 확인
print(df.isnull().sum())Pregnancies 0
Glucose 0
BloodPressure 0
SkinThickness 0
Insulin 0
BMI 0
DiabetesPedigreeFunction 0
Age 0
Outcome 0
dtype: int64print(df.keys())Index(['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin',
'BMI', 'DiabetesPedigreeFunction', 'Age', 'Outcome'],
dtype='object')for key in df.keys():
print(key)
print(df[key].value_counts())for key in df.keys():
print(key,':',(df[key]==0).sum())for key in ["Glucose","BloodPressure","SkinThickness","Insulin","BMI"]:
df.loc[df[key]==0, key]=None
print(df.isnull().sum())
결측치 제거
| dropna : 결측치가 있는 항목들을 제거한다. |
df_drop_na = df.dropna()
df_drop_na.head()
| dropna - how 매개변수 ➢ all : axis의 값에 따라 행 혹은 열의 모든 값이 NaN일 경우 삭제 (default) ➢ any : axis의 값에 따라 행 혹은 열의 값이 하나라도 NaN일 경우 삭제 |
df_drop_na_all = df.dropna(how='all')
df_drop_na_all.head()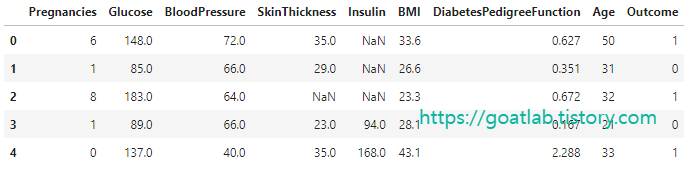
| dropna - axis 매개변수 ➢ 0 : 레코드(행) ➢ 1 : 칼럼(열) |
df_drop_na_axis_1 = df.dropna(axis=1)
df_drop_na_axis_1.head()
| dropna - thresh 매개변수 ➢ 임계치 값 이상보다 데이터가 존재하면 삭제하지 않음 |
df_drop_na_axis_1_threshold = df.dropna(axis=1, thresh=600)
df_drop_na_axis_1_threshold.head()
결측치 보간
| fillna ➢ 결측치를 보간하는데 사용 ➢ 평균, 최빈값, 중앙값을 고려하여 채움 |
df_fillna_0 =df.fillna(0)
df_fillna_0.head()
# mean : 평균
import copy
df_copy = copy.deepcopy(df)
for key in ["Glucose","BloodPressure","SkinThickness","Insulin","BMI"]:
df_copy[key].fillna(df_copy[key].mean(),inplace=True)
df_copy.head()
# groupby를 통해 그룹핑 후 보간 (mean : 평균)
df_copy = copy.deepcopy(df)
for key in ["Glucose","BloodPressure","SkinThickness","Insulin","BMI"]:
df_copy[key].fillna(df_copy.groupby(["Age","Outcome"])[key].transform("mean"), inplace=True)
df_copy.head()
# groupby를 통해 그룹핑 후 보간 (np.median : 중앙값)
df_copy = copy.deepcopy(df)
for key in ["Glucose","BloodPressure","SkinThickness","Insulin","BMI"]:
df_copy[key].fillna(df_copy.groupby(["Age","Outcome"])[key].transform(np.median), inplace=True)
df_copy.head()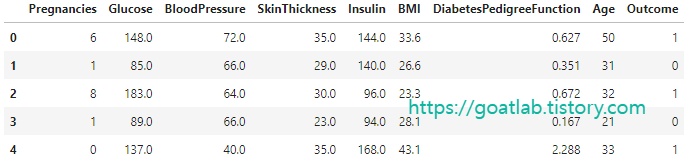
728x90
반응형
LIST
'Data-driven Methodology > DS (Data Science)' 카테고리의 다른 글
| [Data Science] 이상치 처리 (0) | 2022.09.26 |
|---|---|
| [Data Science] 결측치 처리 (2) (0) | 2022.09.26 |
| [Data Science] 데이터 시각화 (4) (0) | 2022.09.22 |
| [Data Science] 데이터 시각화 (3) (0) | 2022.09.22 |
| [Data Science] 데이터 시각화 (2) (0) | 2022.09.22 |



