728x90
반응형
SMALL
이상치 (Outlier)
극단적으로 값이 크거나 작은 값을 말한다. 데이터 오기입 혹은 특이 현상을 칭한다.
당뇨병 데이터셋
| ➢ Pregnancies : 임신 횟수 ➢ Glucose : 포도당 부하 검사 수치 ➢ BloodPressure : 혈압 ➢ SkinThinkness : 삼두근 피부 두께 ➢ Insulin : 인슐린 수치 ➢ BMI : BMI 수치 ➢ DiabetesPedigreeFunction : 당뇨병 가족력 ➢ Age : 나이 ➢ Outcome : 당뇨병 여부 |
import numpy as np
import pandas as pd
df = pd.read_csv('Diabetes_Database.csv')
for key in ["Glucose","BloodPressure","SkinThickness","Insulin","BMI"]:
df.loc[df[key]==0, key]=None
df.head()
이상치 확인
df.describe()
이상치를 결측치로 변경
keys = df.keys()
keys = keys.drop('Outcome')
for key in keys:
tmp_under = df[key].mean() - df[key].std()
tmp_over = df[key].mean() + df[key].std()
df.loc[df[key]<tmp_under, key]=None
df.loc[df[key]>tmp_over, key]=None
df.head()
결측치 확인
print(df.isnull().sum())
결측치 제거
df.dropna(axis=0,inplace=True,subset=['Age'])
df.reset_index()
df.head()
결측치 보간
for key in keys:
df[key].fillna(df.groupby(["Age","Outcome"])[key].transform(np.median), inplace=True)
df.head()
보간 불가능한 레코드 삭제
print(df.isnull().sum())df.dropna(axis=0,inplace=True)
df.reset_index()
df.head()
데이터 스케일링
for key in keys:
df[key]=(df[key]-min(df[key]))/(max(df[key]-min(df[key])))
df.head()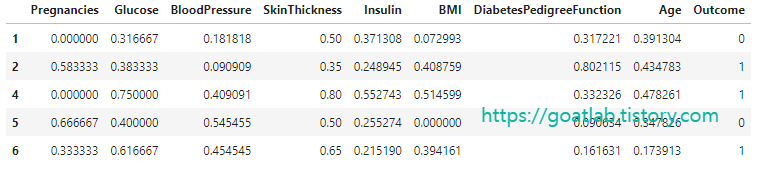
df.describe()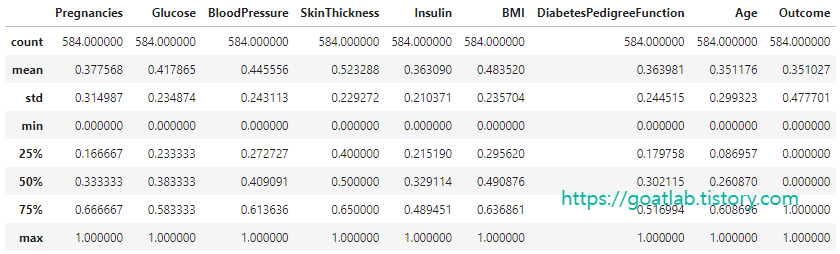
시각화
%matplotlib inline
from matplotlib import pyplot as plt
import seaborn as sns
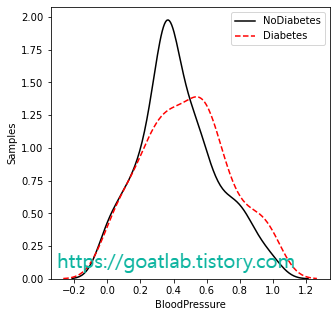
for key in keys:
feature_nondiabetes = df.loc[df['Outcome']==0,key]
feature_diabetes = df.loc[df['Outcome']==1,key]
plt.figure(figsize=(5,5))
print(key)
sns.distplot(df.loc[df['Outcome'] == 0][key], hist=False, axlabel= False, kde_kws={'linestyle':'-', 'color':'black', 'label':"NoDiabetes"})
sns.distplot(df.loc[df['Outcome'] == 1][key], hist=False, axlabel= False, kde_kws={'linestyle':'--', 'color':'red', 'label':"Diabetes"})
plt.ylabel('Samples')
plt.xlabel(key)
plt.legend()
plt.show()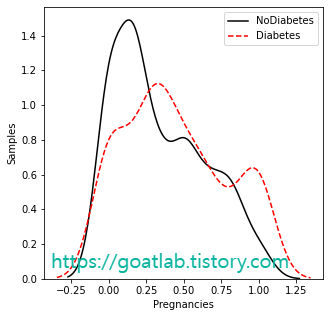


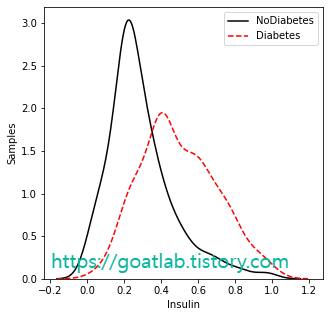
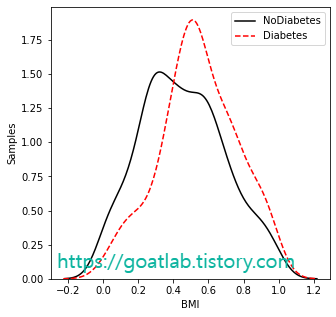
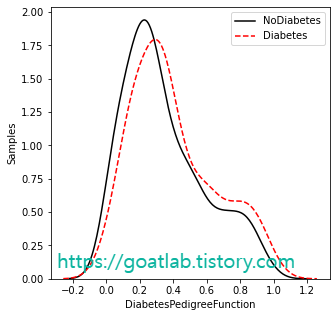
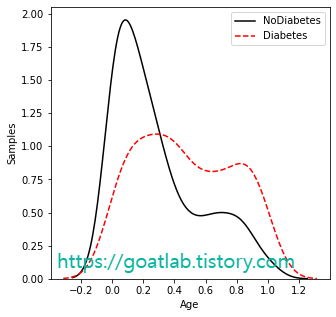
상관관계 분석
df.corr()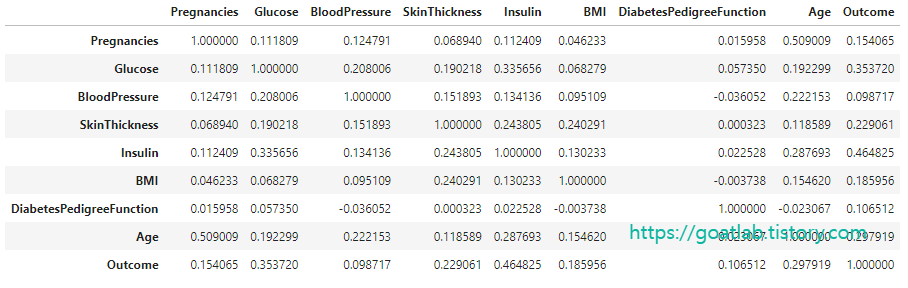
히트맵
plt.figure(figsize=(10,10))
sns.heatmap(df.corr(), annot=True, fmt = '.2f', linewidths=.5, cmap='Bs')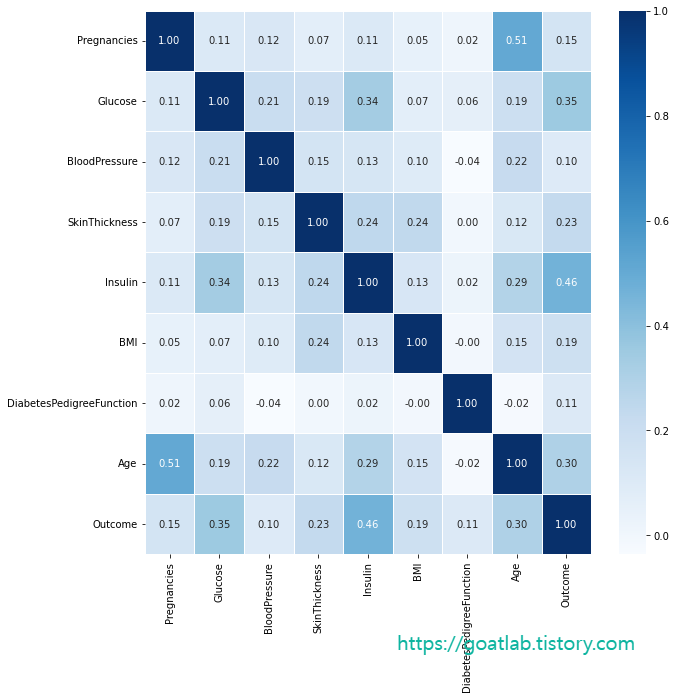
728x90
반응형
LIST
'Data-driven Methodology > DS (Data Science)' 카테고리의 다른 글
| [Data Science] 의사결정 트리 (Decision Tree) (2) (0) | 2022.09.27 |
|---|---|
| [Data Science] 의사결정 트리 (Decision Tree) (1) (0) | 2022.09.27 |
| [Data Science] 결측치 처리 (2) (0) | 2022.09.26 |
| [Data Science] 결측치 처리 (1) (0) | 2022.09.24 |
| [Data Science] 데이터 시각화 (4) (0) | 2022.09.22 |



