ROC 및 AUC를 사용한 다중클래스 분류
신경망의 출력은 다양한 형태로 나타날 수 있다. 그러나 전통적으로 신경망 출력은 일반적으로 다음 중 하나이다.
| • 이진 분류 (Binary Classification) : 두 가지 가능성 (양수 및 음수) 간의 분류이다. 의료 검사에서는 일반적으로 질병에 걸린 사람인지 (양성), 질병이 없는지 (음성) 여부를 확인한다. • 분류 (Classification) : 2개 이상의 붓꽃 데이터세트 간의 분류 (3방향 분류) • 회귀 (Regression) : 수치 예측 |
이진 분류 및 ROC 차트
이진 분류는 신경망이 참 / 거짓, 예 / 아니요, 정확 / 틀림, 구매 / 판매라는 두 가지 옵션 중에서 선택해야 할 때 발생한다. 이진 분류를 사용하는 방법을 알아보기 위해 신용 카드 회사의 분류 시스템을 고려해 보겠다. 이 시스템은 "신용카드 발급" 또는 "신용카드 거부" 중 하나를 수행한다. 이 분류 시스템은 새로운 잠재 고객에게 어떻게 대응할지 결정해야 한다.
고려할 수 있는 클래스가 두 개뿐인 경우 목적 함수의 점수는 위양성 예측 수 대 위음성 수이다. 거짓 음성과 거짓 양성은 모두 오류 유형이므로 차이점을 이해하는 것이 중요하다. 이전 예의 경우 신용 카드 발급은 긍정적이다. 모델이 합의된 대로 지불하지 않을 사람에게 신용 카드를 발급하기로 결정하면 거짓 긍정이 발생한다. 거짓 부정은 모델이 합의된 대로 지불한 사람에게 신용 카드를 거부할 때 발생한다.
두 가지 옵션만 존재하기 때문에 더 심각한 오류 유형인 거짓 긍정 또는 거짓 부정인 실수를 선택할 수 있다. 신용카드를 발행하는 대부분의 은행의 경우, 거짓 양성은 거짓 음성보다 더 나쁘다. 잠재적으로 좋은 신용 카드 소지자를 거절하는 것이 은행이 값비싼 추심 활동을 수행하게 만드는 신용 카드 소지자를 받아들이는 것보다 낫다.
import pandas as pd
df = pd.read_csv("https://data.heatonresearch.com/data/t81-558/wcbreast_wdbc.csv",
na_values = ['NA', '?'])
pd.set_option ('display.max_columns', 5)
pd.set_option ('display.max_rows', 5)
display(df)
ROC 곡선은 약간 혼란스러울 수 있다. 그러나 분석에서는 널리 사용된다. 읽는 방법을 아는 것이 중요하다. 이진 분류는 의료 테스트에서 일반적이다. 누군가에게 질병이 있는지 진단하고 싶은 경우가 많다. 이 진단은 위양성 및 위음성으로 알려진 두 가지 유형의 오류로 이어질 수 있다.
| • 위양성 (False Positive) : 테스트 (신경망)에서 환자가 질병을 앓고 있는 것으로 나타났다. 그러나 환자는 그렇지 않았다. • 거짓 음성 (False Negative) : 테스트는 환자가 질병을 앓고 있지 않은 것으로 나타났다. 그러나 환자는 질병에 걸렸다. • 참양성 (True Positive) : 테스트를 통해 환자에게 질병이 있음이 올바르게 식별되었다. • 진음성 (True Negative) : 테스트에서 환자가 질병을 앓고 있지 않음을 올바르게 식별했다. |

신경망은 그것이 긍정적일 확률에 따라 분류된다. 컷오프를 임계값 (threshold)이라고 한다. 컷오프 위의 모든 것은 긍정적이다. 아래의 내용은 모두 부정적이다. 이 구분값을 설정하면 모델이 더 민감하거나 구체적이 될 수 있다.
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import scipy.stats as stats
import math
mu1 = -2
mu2 = 2
variance = 1
sigma = math.sqrt(variance)
x1 = np.linspace(mu1 - 5 * sigma, mu1 + 4 * sigma, 100)
x2 = np.linspace(mu2 - 5 * sigma, mu2 + 4 * sigma, 100)
plt.plot(x1, stats.norm.pdf(x1, mu1, sigma) / 1, color = "green",
linestyle = 'dashed')
plt.plot(x2, stats.norm.pdf( x2 , mu2, sigma ) / 1, color = "red")
plt.axvline(x = -2, color = "black")
plt.axvline(x = 0, color = "black")
plt.axvline(x =+ 2, color = "black")
plt.text(-2.7, 0.55, "Sensitive")
plt.text(-0.7, 0.55, "Balanced")
plt.text(1.7, 0.55, "Specific")
plt.ylim([0, 0.53])
plt.xlim([-5 , 5])
plt.legend(['Negative', 'Positive'])
plt.yticks([])
plt.show()
이제, 위스콘신 유방암 데이터 세트에 대한 신경망을 훈련한다. 먼저, 데이터를 전처리하는 것으로 시작한다. 모든 데이터가 숫자 데이터이므로 각 열에 대한 z 점수를 계산한다.
from scipy.stats import zscore
x_columns = df.columns.drop('diagnosis').drop('id')
for col in x_columns:
df[col] = zscore(df[col])
# Convert to numpy - Regression
x = df[x_columns].values
y = df['diagnosis'].map({'M': 1, 'B': 0}).values # Binary classification, M is 1 and B is 0
이제, 두 가지 함수를 정의할 수 있다. 첫 번째 함수는 혼동 행렬을 플롯한다. 두 번째 함수는 ROC 차트를 그린다.
import numpy as np
import tensorflow.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.callbacks import EarlyStopping
from sklearn.model_selection import train_test_split
# Split into train/test
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.25, random_state=42)
model = Sequential()
model.add(Dense(100, input_dim=x.shape[1], activation='relu',
kernel_initializer='random_normal'))
model.add(Dense(50, activation='relu', kernel_initializer='random_normal'))
model.add(Dense(25, activation='relu', kernel_initializer='random_normal'))
model.add(Dense(1, activation='sigmoid', kernel_initializer='random_normal'))
model.compile(loss='binary_crossentropy',
optimizer=tensorflow.keras.optimizers.Adam(),
metrics=['accuracy'])
monitor = EarlyStopping(monitor='val_loss', min_delta=1e-3,
patience=5, verbose=1, mode='auto', restore_best_weights=True)
model.fit(x_train, y_train, validation_data=(x_test, y_test),
callbacks=[monitor], verbose=2, epochs=1000)pred = model.predict(x_test)
plot_roc(pred, y_test)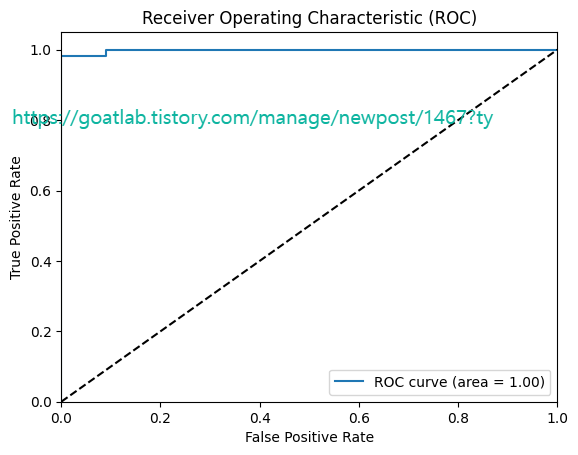
'DNN with Keras > Training for Tabular Data' 카테고리의 다른 글
| Multiclass Classification Error Metrics (0) | 2024.03.06 |
|---|---|
| 신경망을 위한 X 및 Y 생성 (0) | 2023.11.07 |
| 딥러닝을 위한 특징 벡터 인코딩 (0) | 2023.11.07 |


