728x90
반응형
SMALL
wandb
W&B (Weight and Bias)은 실험 그룹 혹은 실험 단위로 실험 이력 요소들을 관리할 수 있다. https://wandb.ai/site에 접속하여 가입한 후 API 키를 발급받는다.
pip install wandb
그리고 다음 경로에서 API 키를 저장하기 위해 환경 변수 파일인 .env를 생성한다.


src/utils/utils.py
Run name 자동 지정하기 위해 다음을 추가한다.
def auto_increment_run_suffix(name: str, pad=3):
suffix = name.split("-")[-1]
next_suffix = str(int(suffix) + 1).zfill(pad)
return name.replace(suffix, next_suffix)
src/main.py
import os
import sys
sys.path.append(
os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
)
import fire
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from tqdm import tqdm
from src.dataset.watch_log import get_datasets
from src.model.movie_predictor import MoviePredictor
from src.utils.utils import init_seed, model_dir, auto_increment_run_suffix
from src.train.train import train
from src.evaluate.evaluate import evaluate
from src.model.movie_predictor import MoviePredictor, model_save
from utils.constant import Optimizers, Models
import wandb
from dotenv import load_dotenv
load_dotenv()
init_seed()
def get_runs(project_name):
return wandb.Api().runs(path=project_name, order="-created_at")
def get_latest_run(project_name):
runs = get_runs(project_name)
if not runs:
return f"{project_name}-000"
return runs[0].name
def run_train(model_name, optimizer, num_epochs=10, lr=0.001, model_ext="pth"):
api_key = os.environ["WANDB_API_KEY"]
wandb.login(key=api_key)
project_name = model_name.replace("_", "-")
wandb.init(
project=project_name,
notes="content-based movie recommend model",
tags=["content-based", "movie", "recommend"],
config=locals(),
)
Models.validation(model_name)
Optimizers.validation(optimizer)
# 데이터셋 및 DataLoader 생성
train_dataset, val_dataset, test_dataset = get_datasets()
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=0, pin_memory=False)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False, num_workers=0, pin_memory=False)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False, num_workers=0, pin_memory=False)
# 모델 초기화
model_params = {
"input_dim": train_dataset.features_dim,
"num_classes": train_dataset.num_classes
}
model_class = Models[model_name.upper()].value
model = model_class(**model_params)
# 손실 함수 및 옵티마이저 정의
criterion = nn.CrossEntropyLoss()
optimizer_class = Optimizers[optimizer.upper()].value
optimizer = optimizer_class(model.parameters(), lr=lr)
# 학습 루프
epoch = 0
train_loss = 0
num_epochs = 10
for epoch in tqdm(range(num_epochs)):
train_loss = train(model, train_loader, criterion, optimizer)
val_loss, _ = evaluate(model, val_loader, criterion)
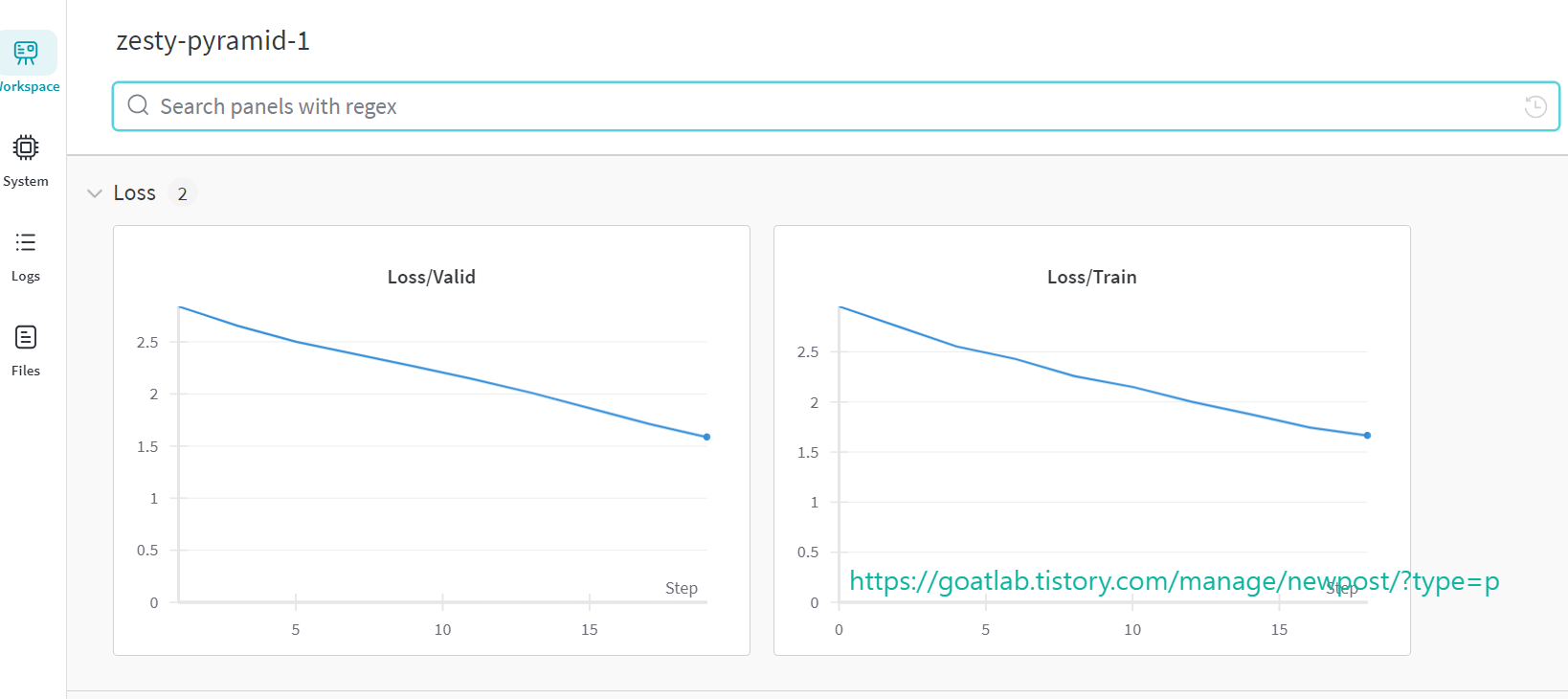
wandb.log({"Loss/Train": train_loss})
wandb.log({"Loss/Valid": val_loss})
print(f"Epoch {epoch + 1}/{num_epochs}, "
f"Train Loss: {train_loss:.4f}, "
f"Val Loss: {val_loss:.4f}, "
f"Val-Train Loss : {val_loss-train_loss:.4f}")
model_ext = "onnx" # or "pth"
model_save(
model=model,
model_params=model_params,
epoch=num_epochs,
optimizer=optimizer,
loss=train_loss,
scaler=train_dataset.scaler,
contents_id_map=train_dataset.contents_id_map,
ext=model_ext,
)
# 테스트
model.eval()
test_loss, predictions = evaluate(model, test_loader, criterion)
print(f"Test Loss : {test_loss:.4f}")
# print([train_dataset.decode_content_id(idx) for idx in predictions])
if __name__ == '__main__':
fire.Fire({
"train": run_train,
})python src/main.py train --model_name movie_predictor --optimizer adam --num_epochs 20 --lr 0.002
728x90
반응형
LIST
'App Programming > MLops' 카테고리의 다른 글
| [MLops] 데이터베이스 (0) | 2024.08.13 |
|---|---|
| [MLops] 모델 추론 (0) | 2024.08.13 |
| [MLops] 모델 저장하기 (0) | 2024.08.12 |
| [MLops] 모델 학습 및 평가 (0) | 2024.08.12 |
| [MLops] 모델 훈련 (0) | 2024.08.09 |



