728x90
반응형
SMALL
디렉토리 설정
docker exec -it my-mlops bash
opt 디렉토리에서 mlops-movie-predictor 디렉토리를 생성한다.
mkdir mlops-movie-predictor
그 다음, mlops-movie-predictor 디렉토리로 이동하고 dataset과 src 디렉토리를 생성한다. 또, src 디렉토리에서 utils, dataset, model, train, evaluate 디렉토리를 생성한다.
라이브러리 설치
pip install torch numpy==1.26.4 pandas scikit-learn tqdm
src/utils/utils.py
import os
import random
import numpy as np
import torch
def init_seed():
np.random.seed(0)
torch.manual_seed(0)
random.seed(0)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
def project_path():
return os.path.join(
os.path.dirname(
os.path.abspath(__file__)
),
"..",
".."
)
def model_dir(model_name):
return os.path.join(
project_path(),
"models",
model_name
)
src/dataset/watch_log.py
import os
import pandas as pd
import torch
from torch.utils.data import Dataset
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from src.utils.utils import project_path
class WatchLogDataset(Dataset):
def __init__(self, df, scaler=None):
self.df = df
self.features = None
self.labels = None
self.contents_id_map = None
self.scaler = scaler
self._preprocessing()
def _preprocessing(self):
content_id_categories = pd.Categorical(self.df["content_id"])
self.contents_id_map = dict(enumerate(content_id_categories.categories))
self.df["content_id"] = content_id_categories.codes
target_columns = ["rating", "popularity", "watch_seconds"]
if self.scaler:
scaled_features = self.scaler.transform(self.df[target_columns])
else:
self.scaler = StandardScaler()
scaled_features = self.scaler.fit_transform(self.df[target_columns])
self.features = torch.FloatTensor(scaled_features)
self.labels = torch.LongTensor(self.df["content_id"].values)
def decode_content_id(self, encoded_id):
return self.contents_id_map[encoded_id]
@property
def features_dim(self):
return self.features.shape[1]
@property
def num_classes(self):
return len(self.df["content_id"].unique())
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
return self.features[idx], self.labels[idx]
def read_dataset():
watch_log_path = os.path.join(project_path(), "dataset", "watch_log.csv")
df = pd.read_csv(watch_log_path)
return df
def split_dataset(df):
train_df, val_df = train_test_split(df, test_size=0.2, random_state=42)
train_df, test_df = train_test_split(train_df, test_size=0.2, random_state=42)
return train_df, val_df, test_df
def get_datasets():
df = read_dataset()
train_df, val_df, test_df = split_dataset(df)
train_dataset = WatchLogDataset(train_df)
val_dataset = WatchLogDataset(val_df)
test_dataset = WatchLogDataset(test_df)
return train_dataset, val_dataset, test_dataset
src/model/movie_predictor.py
import torch.nn as nn
class MoviePredictor(nn.Module):
name = "movie_predictor"
def __init__(self, input_dim, num_classes):
super(MoviePredictor, self).__init__()
self.layer1 = nn.Linear(input_dim, 64)
self.layer2 = nn.Linear(64, 32)
self.layer3 = nn.Linear(32, num_classes)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.2)
def forward(self, x):
x = self.relu(self.layer1(x))
x = self.dropout(x)
x = self.relu(self.layer2(x))
x = self.dropout(x)
x = self.layer3(x)
return x
src/train/train.py
def train(model, train_loader, criterion, optimizer):
model.train()
total_loss = 0
for features, labels in train_loader:
predictions = model(features)
loss = criterion(predictions, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(train_loader)
src/evaluate/evaluate.py
import torch
def evaluate(model, val_loader, criterion):
model.eval()
total_loss = 0
all_predictions = []
with torch.no_grad():
for features, labels in val_loader:
predictions = model(features)
loss = criterion(predictions, labels)
total_loss += loss.item()
_, predicted = torch.max(predictions.data, 1)
all_predictions.extend(predicted.cpu().numpy())
return total_loss / len(val_loader), all_predictions
src/main.py
import os
import sys
sys.path.append(
os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
)
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from tqdm import tqdm
from src.dataset.watch_log import get_datasets
from src.model.movie_predictor import MoviePredictor
from src.utils.utils import init_seed
from src.train.train import train
from src.evaluate.evaluate import evaluate
init_seed()
if __name__ == '__main__':
# 데이터셋 및 DataLoader 생성
train_dataset, val_dataset, test_dataset = get_datasets()
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=0, pin_memory=False)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False, num_workers=0, pin_memory=False)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False, num_workers=0, pin_memory=False)
# 모델 초기화
model_params = {
"input_dim": train_dataset.features_dim,
"num_classes": train_dataset.num_classes
}
model = MoviePredictor(**model_params)
# 손실 함수 및 옵티마이저 정의
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 학습 루프
num_epochs = 10
for epoch in tqdm(range(num_epochs)):
train_loss = train(model, train_loader, criterion, optimizer)
val_loss, _ = evaluate(model, val_loader, criterion)
print(f"Epoch {epoch + 1}/{num_epochs}, "
f"Train Loss: {train_loss:.4f}, "
f"Val Loss: {val_loss:.4f}, "
f"Val-Train Loss : {val_loss-train_loss:.4f}")
# 테스트
model.eval()
test_loss, predictions = evaluate(model, test_loader, criterion)
print(f"Test Loss : {test_loss:.4f}")
# print([train_dataset.decode_content_id(idx) for idx in predictions])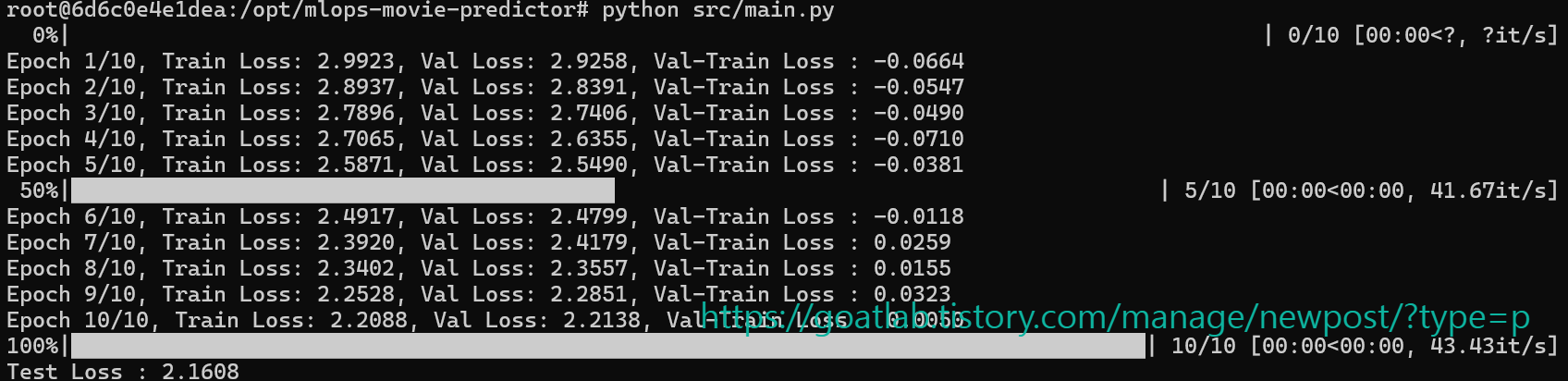
728x90
반응형
LIST
'App Programming > MLops' 카테고리의 다른 글
| [MLops] 학습 결과 기록하기 (0) | 2024.08.12 |
|---|---|
| [MLops] 모델 저장하기 (0) | 2024.08.12 |
| [MLops] 모델 훈련 (0) | 2024.08.09 |
| [MLops] TMDB API 데이터 수집 및 전처리 (0) | 2024.08.09 |
| [MLops] Docker에서 MLops 네트워크 구성 (0) | 2024.08.09 |



