728x90
반응형
SMALL
MySQL 컨테이너
기존 mlops 컨테이너와 동일한 네트워크로 설정하여 통신하도록 생성한다.
docker run -itd --name my-mlops-db --network mlops -e MYSQL_ROOT_PASSWORD=root mysql:8.0.39
그 다음, 컨테이너에 진입하여 mlops 데이터베이스 생성한다.
# 컨테이너 진입
docker exec -it my-mlops-db bash
# MySQL 로그인
mysql -u root -p # root 패스워드 입력
# 데이터베이스 생성
create database mlops;
# 생성 확인
show databases;
# 패스워드 인증 방식 변경(python mysqlclient 라이브러리 호환성)
alter user 'root'@'%' identified with mysql_native_password by 'root';
flush privileges;
라이브러리 설치
파이썬 컨테이너에서 다음 명령으로 설치한다.
pip install mysqlclient sqlalchemy python-dotenv fastapi uvicorn pydantic
.env
데이터베이스 환경 변수 파일 내 환경 변수 추가한다. 브릿지 네트워크 설정한 것을 토대로 db 컨테이너와 통신이 가능하도록 한다.
/opt/mlops-movie-predictor# vi .envDB_USER=root
DB_PASSWORD=root
DB_HOST=my-mlops-db
DB_PORT=3306
src/postprocess/postprocess.py
import os
from sqlalchemy import create_engine, text
import pandas as pd
def get_engine(db_name):
engine = create_engine(url=(
f"mysql+mysqldb://"
f"{os.environ.get('DB_USER')}:"
f"{os.environ.get('DB_PASSWORD')}@"
f"{os.environ.get('DB_HOST')}:"
f"{os.environ.get('DB_PORT')}/"
f"{db_name}"))
return engine
def write_db(data: pd.DataFrame, db_name, table_name):
engine = get_engine(db_name)
connect = engine.connect()
data.to_sql(table_name, connect, if_exists="append")
connect.close()
def read_db(db_name, table_name, k=10):
engine = get_engine(db_name)
connect = engine.connect()
result = connect.execute(
statement=text(
f"select recommend_content_id from {table_name} order by `index` desc limit :k"
),
parameters={"table_name": table_name, "k": k}
)
connect.close()
contents = [data[0] for data in result]
return contents
src/inference/inference.py
import os
import sys
import glob
sys.path.append(
os.path.dirname(
os.path.dirname(
os.path.dirname(
os.path.abspath(__file__)
)
)
)
)
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import numpy as np
import pandas as pd
import onnx
import onnxruntime
from icecream import ic
from dotenv import load_dotenv
from src.utils.utils import model_dir, calculate_hash, read_hash
from src.model.movie_predictor import MoviePredictor
from src.dataset.watch_log import WatchLogDataset, get_datasets
from src.evaluate.evaluate import evaluate
from src.postprocess.postprocess import write_db
def model_validation(model_path):
original_hash = read_hash(model_path)
current_hash = calculate_hash(model_path)
if original_hash == current_hash:
ic("validation success")
return True
else:
return False
def load_checkpoint():
target_dir = model_dir(MoviePredictor.name)
models_path = os.path.join(target_dir, "*.pth")
latest_model = glob.glob(models_path)[-1]
if model_validation(latest_model):
checkpoint = torch.load(latest_model)
return checkpoint
else:
raise FileExistsError("Not found or invalid model file")
return checkpoint
def init_model(checkpoint):
model = MoviePredictor(**checkpoint["model_params"])
model.load_state_dict(checkpoint["model_state_dict"])
criterion = nn.CrossEntropyLoss()
scaler = checkpoint["scaler"]
contents_id_map = checkpoint["contents_id_map"]
return model, criterion, scaler, contents_id_map
def make_inference_df(data):
columns = "user_id content_id watch_seconds rating popularity".split()
return pd.DataFrame(
data=[data],
columns=columns,
)
def inference(model, criterion, scaler, contents_id_map, data: np.array, batch_size=1):
if data.size > 0:
df = make_inference_df(data)
dataset = WatchLogDataset(df, scaler=scaler)
else:
_, _, dataset = get_datasets()
dataset.contents_id_map = contents_id_map
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=False, num_workers=0, pin_memory=False)
loss, predictions = evaluate(model, dataloader, criterion)
ic(loss)
ic(predictions)
return [dataset.decode_content_id(idx) for idx in predictions]
def inference_onnx(scaler, contents_id_map, data):
df = make_inference_df(data)
dataset = WatchLogDataset(df, scaler=scaler)
dataset.contents_id_map = contents_id_map
dataloader = DataLoader(dataset, batch_size=1, shuffle=False, num_workers=0, pin_memory=False)
latest_model = get_latest_model(model_ext="onnx")
ort_session = onnxruntime.InferenceSession(latest_model, providers=["CPUExecutionProvider"])
predictions = []
for data, labels in dataloader:
ort_inputs = {ort_session.get_inputs()[0].name: data.numpy()}
ort_outs = [ort_session.get_outputs()[0].name]
output = ort_session.run(ort_outs, ort_inputs)
predicted = np.argmax(output[0], 1)[0]
predictions.append(predicted)
return dataset.decode_content_id(predictions[0])
def recommend_to_df(recommend: list):
return pd.DataFrame(
data=recommend,
columns="recommend_content_id".split()
)
if __name__ == "__main__":
load_dotenv()
checkpoint = load_checkpoint()
model, criterion, scaler, contents_id_map = init_model(checkpoint)
data = np.array([1, 1209290, 4508, 7.577, 1204.764])
# recommend = inference(model, criterion, scaler, contents_id_map, data)
recommend = inference(model, criterion, scaler, contents_id_map, data=np.array([]), batch_size=64)
ic(recommend)
recommend_df = recommend_to_df(recommend)
write_db(recommend_df, "mlops", "recommend")
src/main.py
import os
import sys
sys.path.append(
os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
)
import fire
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from tqdm import tqdm
from src.dataset.watch_log import get_datasets
from src.model.movie_predictor import MoviePredictor
from src.utils.utils import init_seed, model_dir, auto_increment_run_suffix
from src.train.train import train
from src.evaluate.evaluate import evaluate
from src.model.movie_predictor import MoviePredictor, model_save
from utils.constant import Optimizers, Models
import wandb
import numpy as np
from src.inference.inference import load_checkpoint, init_model, inference, recommend_to_df
from src.postprocess.postprocess import write_db
from dotenv import load_dotenv
load_dotenv()
init_seed()
def get_runs(project_name):
return wandb.Api().runs(path=project_name, order="-created_at")
def get_latest_run(project_name):
runs = get_runs(project_name)
if not runs:
return f"{project_name}-000"
return runs[0].name
def run_train(model_name, optimizer, num_epochs=10, lr=0.001, model_ext="pth"):
api_key = os.environ["WANDB_API_KEY"]
wandb.login(key=api_key)
project_name = model_name.replace("_", "-")
wandb.init(
project=project_name,
notes="content-based movie recommend model",
tags=["content-based", "movie", "recommend"],
config=locals(),
)
Models.validation(model_name)
Optimizers.validation(optimizer)
# 데이터셋 및 DataLoader 생성
train_dataset, val_dataset, test_dataset = get_datasets()
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=0, pin_memory=False)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False, num_workers=0, pin_memory=False)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False, num_workers=0, pin_memory=False)
# 모델 초기화
model_params = {
"input_dim": train_dataset.features_dim,
"num_classes": train_dataset.num_classes
}
model_class = Models[model_name.upper()].value
model = model_class(**model_params)
# 손실 함수 및 옵티마이저 정의
criterion = nn.CrossEntropyLoss()
optimizer_class = Optimizers[optimizer.upper()].value
optimizer = optimizer_class(model.parameters(), lr=lr)
# 학습 루프
epoch = 0
train_loss = 0
num_epochs = 10
for epoch in tqdm(range(num_epochs)):
train_loss = train(model, train_loader, criterion, optimizer)
val_loss, _ = evaluate(model, val_loader, criterion)
wandb.log({"Loss/Train": train_loss})
wandb.log({"Loss/Valid": val_loss})
print(f"Epoch {epoch + 1}/{num_epochs}, "
f"Train Loss: {train_loss:.4f}, "
f"Val Loss: {val_loss:.4f}, "
f"Val-Train Loss : {val_loss-train_loss:.4f}")
model_ext = "pth" # or "pth"
model_save(
model=model,
model_params=model_params,
epoch=num_epochs,
optimizer=optimizer,
loss=train_loss,
scaler=train_dataset.scaler,
contents_id_map=train_dataset.contents_id_map,
ext=model_ext,
)
# 테스트
model.eval()
test_loss, predictions = evaluate(model, test_loader, criterion)
print(f"Test Loss : {test_loss:.4f}")
# print([train_dataset.decode_content_id(idx) for idx in predictions])
def run_inference(data=None, batch_size=64):
checkpoint = load_checkpoint()
model, criterion, scaler, contents_id_map = init_model(checkpoint)
if data is None:
data = []
data = np.array(data)
recommend = inference(model, criterion, scaler, contents_id_map, data, batch_size)
print(recommend)
write_db(recommend_to_df(recommend), "mlops", "recommend")
if __name__ == '__main__':
fire.Fire({
"preprocessing": run_preprocessing,
"train": run_train,
"inference": run_inference,
})
src/webapp.py
import os
import sys
sys.path.append(
os.path.dirname(
os.path.dirname(
os.path.abspath(__file__)
)
)
)
import numpy as np
import uvicorn
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from dotenv import load_dotenv
from src.inference.inference import load_checkpoint, init_model, inference
from src.postprocess.postprocess import read_db
app = FastAPI()
load_dotenv()
checkpoint = load_checkpoint()
model, criterion, scaler, contents_id_map = init_model(checkpoint)
class InferenceInput(BaseModel):
user_id: int
content_id: int
watch_seconds: int
rating: float
popularity: float
# https://api.endpoint/movie-predictor/inference?user_id=12345&content_id=456...
@app.post("/predict")
async def predict(input_data: InferenceInput):
try:
data = np.array([
input_data.user_id,
input_data.content_id,
input_data.watch_seconds,
input_data.rating,
input_data.popularity
])
recommend = inference(model, criterion, scaler, contents_id_map, data)
return {"recommended_content_id": recommend}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.get("/batch-predict")
async def batch_predict(k: int = 5):
try:
recommend = read_db("mlops", "recommend", k=k)
return {"recommended_content_id": recommend}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
API 서버 시작 스크립트 작성
vi start_api_server.sh#!/bin/bash
nohup python src/webapp.py &chmod +x start_api_server.sh
docker commit my-mlops my-mlops:v1
docker run -itd --name my-mlops-api --network mlops -p 9999:8000 my-mlops:v1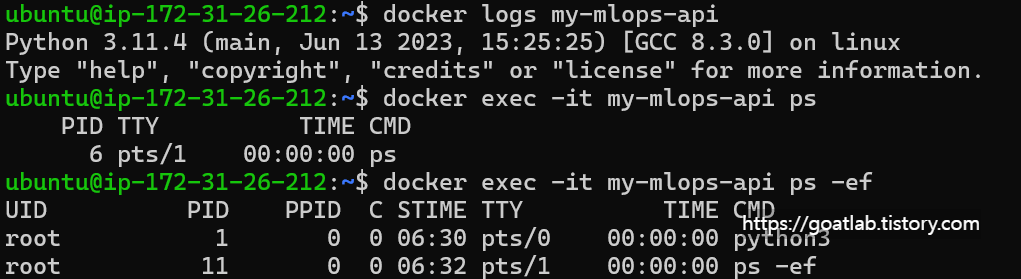

cat nohup.out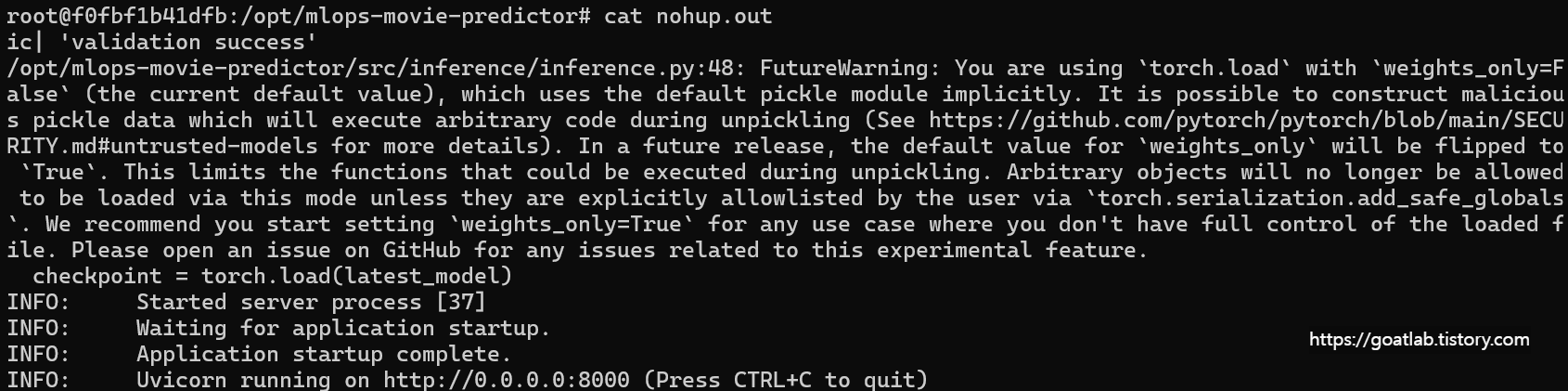
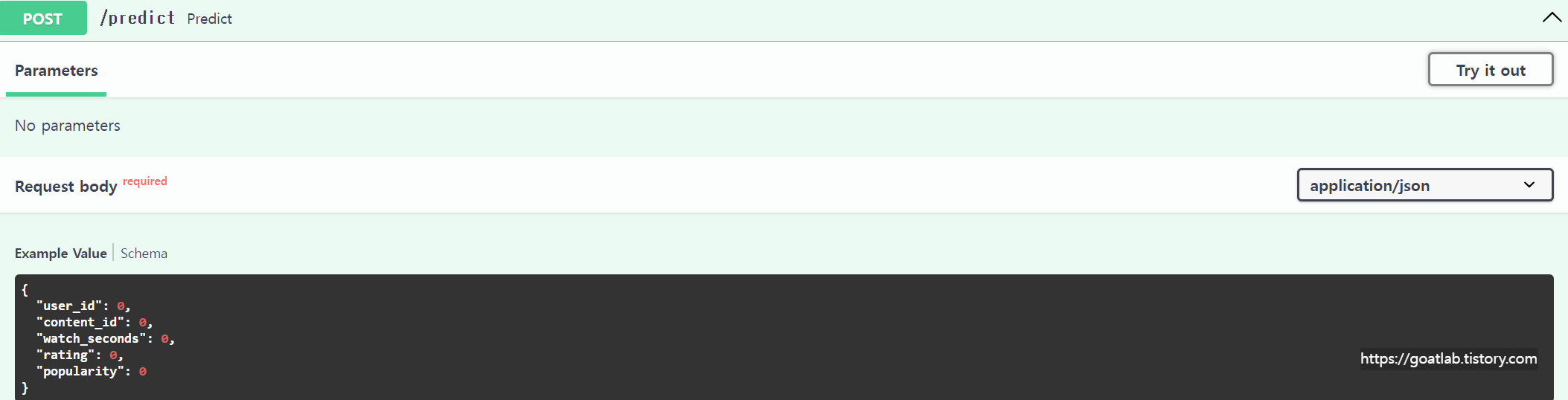
FastAPI 서버 실행
인바운드 규칙에 9999번 포트를 사용한다.

EC2 퍼블릭 IP로 서버에 접속한다.
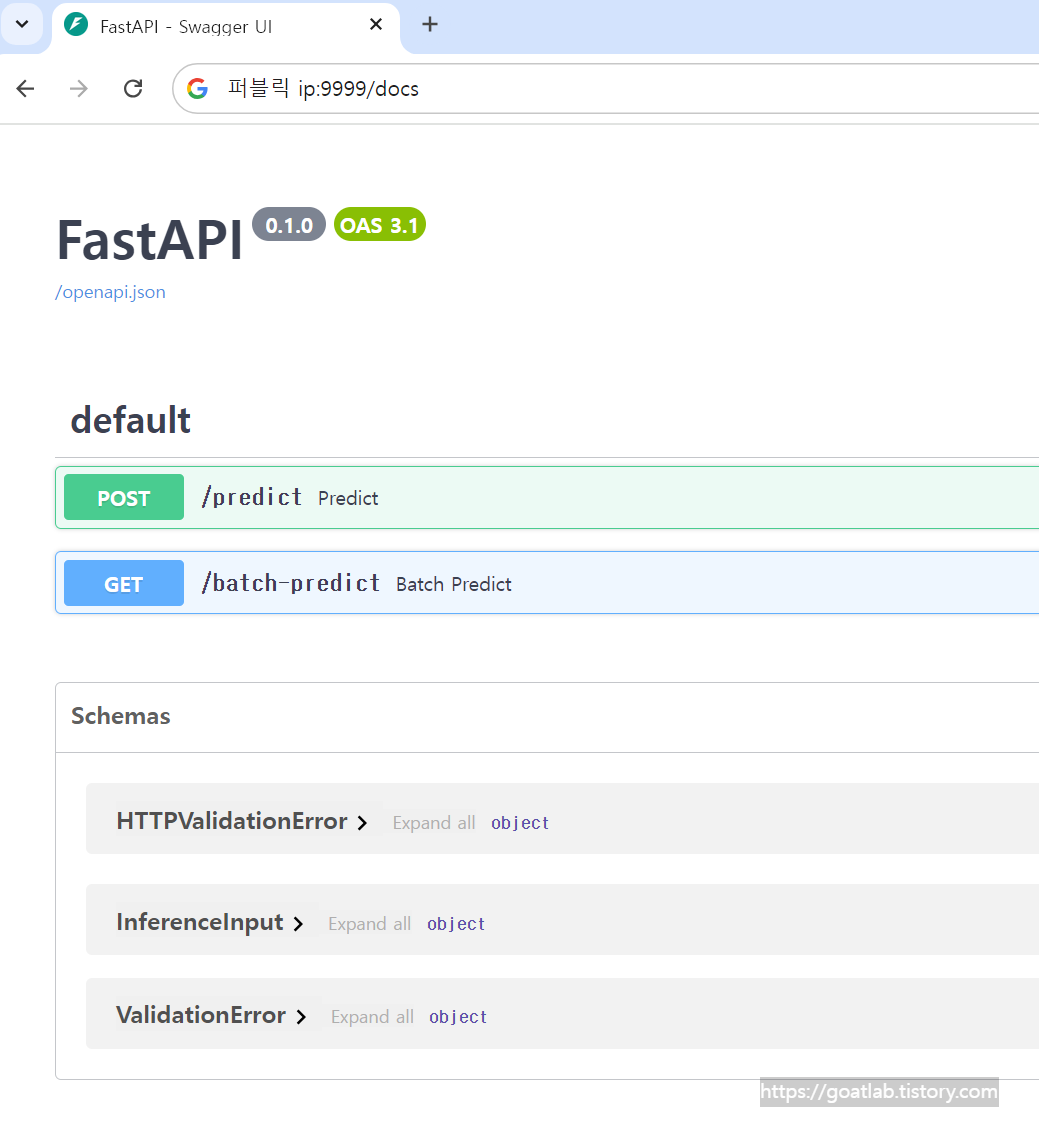
POST에서 Try it out을 누르면 테스트도 가능하다.
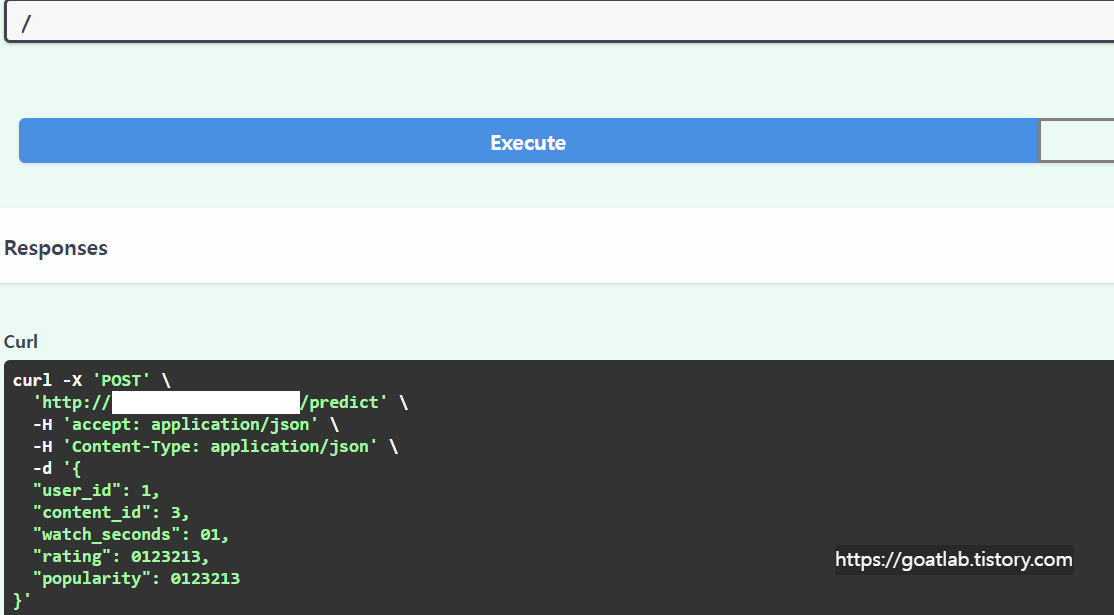
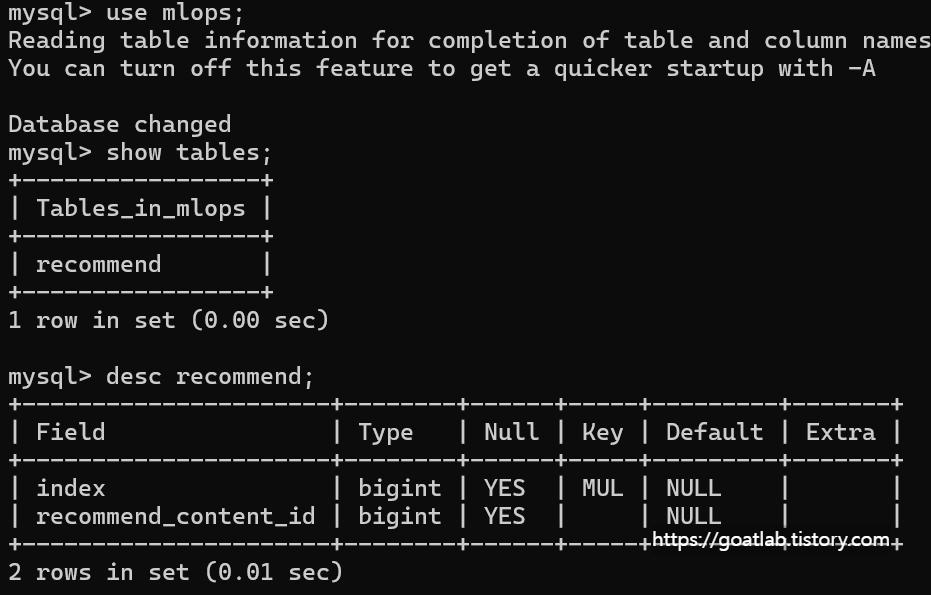
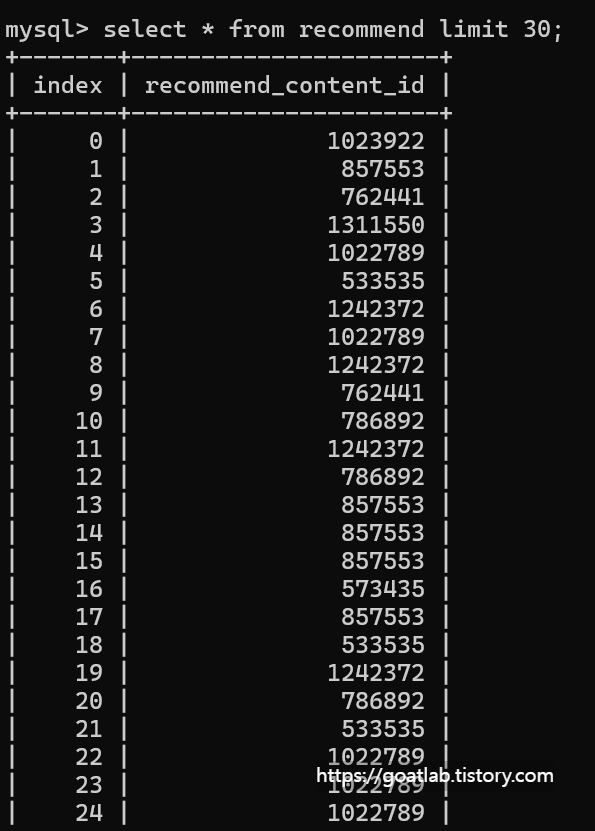
데이터베이스 조회
728x90
반응형
LIST
'App Programming > MLops' 카테고리의 다른 글
| [MLops] MLflow (0) | 2024.08.19 |
|---|---|
| [MLops] GitHub Action (0) | 2024.08.17 |
| [MLops] 모델 추론 (0) | 2024.08.13 |
| [MLops] 학습 결과 기록하기 (0) | 2024.08.12 |
| [MLops] 모델 저장하기 (0) | 2024.08.12 |



