리프 방식 (최상 우선) 트리 매개변수 조정
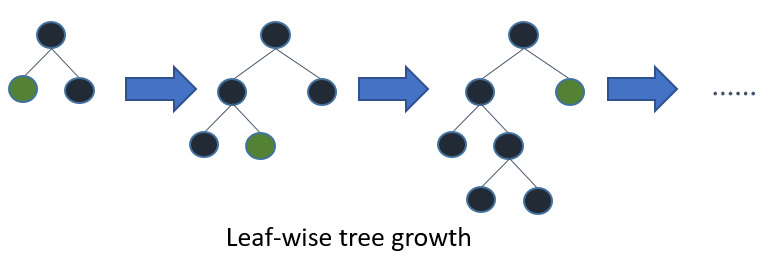
LightGBM은 잎별 트리 성장 알고리즘을 사용하는 반면 다른 많은 인기 도구는 깊이별 트리 성장을 사용한다. 깊이별 성장과 비교할 때 잎별 알고리즘은 훨씬 빠르게 수렴할 수 있다. 그러나 적절한 매개변수와 함께 사용하지 않으면 잎사귀 성장이 과적합될 수 있다.
리프 방식 트리를 사용하여 좋은 결과를 얻으려면 다음과 같은 몇 가지 중요한 매개변수가 있다.
|
Add More Computational Resources
시스템에서 LightGBM은 OpenMP를 사용하여 많은 작업을 병렬화한다. LightGBM이 사용하는 최대 스레드 수는 매개변수 num_threads에 의해 제어된다. 기본적으로 이것은 OpenMP의 기본 동작을 따른다 (실제 CPU 코어당 스레드 하나 또는 환경 변수 값 OMP_NUM_THREADS이 설정되어 있는 경우). 최상의 성능을 위해 사용 가능한 실제 CPU 코어 수로 설정하면 된다.
사용 가능한 CPU 코어가 더 많은 머신으로 이동하여 더 빠른 훈련을 달성할 수 있다. 분산 (다중 머신) 학습을 사용하면 교육 시간을 줄일 수도 있다. 자세한 내용은 분산 학습 가이드를 참조하면 된다.
Use a GPU-enabled version of LightGBM
LightGBM의 GPU 지원 빌드를 사용하면 훈련이 더 빨라질 수 있다. 자세한 내용은 GPU 자습서를 참조하면 된다.
Grow Shallower Trees
LightGBM의 총 교육 시간은 추가된 총 트리 노드 수에 따라 늘어난다. LightGBM에는 트리당 노드 수를 제어하는 데 사용할 수 있는 여러 매개변수가 있다.
아래는 훈련 속도를 높이지만 훈련 정확도를 떨어뜨릴 수 있다.
| Decrease max_depth | 이 매개변수는 각 트리의 루트 노드와 리프 노드 사이의 최대 거리를 제어하는 정수입니다. max_depth훈련 시간을 줄이기 위해 줄인다. |
| Decrease num_leaves | LightGBM은 깊이에 관계없이 해당 노드를 추가함으로써 얻은 이득을 기반으로 트리에 노드를 추가한다. |
| Increase min_gain_to_split | 새 트리 노드를 추가할 때 LightGBM은 이득이 가장 큰 분할점을 선택한다. 기본적으로 분할점 추가로 인한 훈련 손실의 감소가 발생한다. LightGBM은 min_gain_to_split0.0으로 설정되며, 이는 "너무 작은 개선이 없음"을 의미한다. 그러나 실제로는 훈련 손실의 아주 작은 개선이 모델의 일반화 오류에 의미 있는 영향을 미치지 않는다는 것을 알 수 있다. 훈련 시간을 줄이려면 min_gain_to_split을 늘린다. |
| Increase min_data_in_leaf and min_sum_hessian_in_leaf |
훈련 데이터의 크기와 기능의 분포에 따라 LightGBM은 소수의 관찰만 설명하는 트리 노드를 추가할 수 있다. 가장 극단적인 경우 훈련 데이터의 단일 관측값만 해당하는 트리 노드를 추가하는 것을 고려해야 한다. 이것은 잘 일반화될 가능성이 거의 없으며 아마도 과적합의 신호일 것이다. 이것은 max_depth 및 num_leaves와 같은 매개변수를 사용하여 간접적으로 방지할 수 있지만 LightGBM은 이러한 지나치게 특정한 트리 노드를 추가하는 것을 직접 방지하는 데 도움이 되는 매개변수도 제공한다. |
|
|
https://lightgbm.readthedocs.io/en/latest/Parameters-Tuning.html
Parameters Tuning — LightGBM 3.3.2.99 documentation
num_leaves. This is the main parameter to control the complexity of the tree model. Theoretically, we can set num_leaves = 2^(max_depth) to obtain the same number of leaves as depth-wise tree. However, this simple conversion is not good in practice. The re
lightgbm.readthedocs.io
'Learning-driven Methodology > ML (Machine Learning)' 카테고리의 다른 글
| [Machine Learning] 비선형 SVM 분류 (0) | 2022.09.30 |
|---|---|
| [LightGBM] 매개변수 조정 (Parameters Tuning) (2) (0) | 2022.07.04 |
| [LightGBM] Features (2) (0) | 2022.06.28 |
| [LightGBM] Features (1) (0) | 2022.06.28 |
| [LightGBM] Python 패키지 (2) (0) | 2022.06.28 |



