불균형한 데이터 균형 조정
필요한 양보다 많으면 본질적으로 좋은 것은 없다. 더 많은 양의 CO2가 지구를 따뜻하게 할 것이고, 더 많은 양의 비가 도시에 범람할 것이고, 더 많은 생각은 당신의 실행을 망칠 것이다. 이러한 것은 데이터에도 동일하게 적용된다. 한 클래스의 인스턴스 수가 많을수록 가짜 예측이 발생한다. 간단한 예를 통해 이를 이해할 수 있다. 빨간 공과 파란 공이 가득한 가방이 있다고 상상하고 어떤 색 공을 그릴지 묻는다. 환자의 암 발병 여부를 예측하는 기계 학습 모델이라고 상상했을 때, 분명히 논리적인 선택은 대부분의 환자가 암이 아니기 때문에 환자에게 암이 없다고 결론을 내리는 것이다. 실제로 모델로서 모든 사람에게 암이 없다고 표시하는 것만으로도 높은 정확도를 얻을 수 있다.
데이터가 불균형한 경우 위의 예에서 두 가지 가능한 결론을 내릴 수 있다. 첫 번째는 모델이 다른 매개변수에 관계없이 높은 수의 클래스를 예측하는 경향이 있다는 것이다. 둘째, 모델 정확도는 실제 그림을 보여주지 않는다. 왜냐하면 클래스 1의 99개 인스턴스가 포함된 100개 레코드의 데이터 세트가 있는 경우 모델은 모든 인스턴스를 클래스 1로 예측하여 99%의 정확도를 얻게 되기 때문이다.
이제 문제는 데이터에서 이러한 불균형을 어떻게 제거할 수 있느냐는 것이다. 먼저, 모든 클래스의 인스턴스 수가 동일하면 데이터의 균형이 유지된다.
언더샘플링 (UnderSampling)
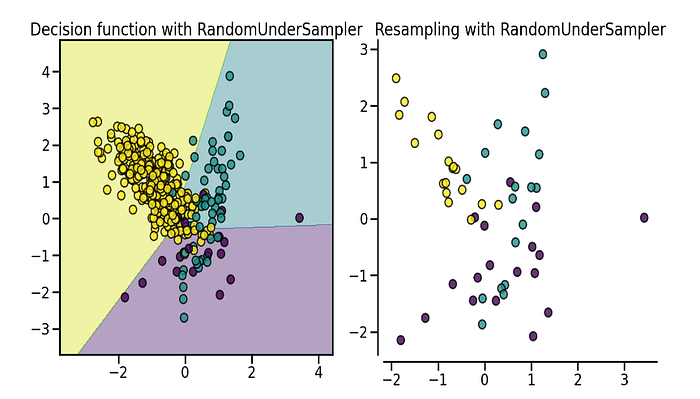
이 방법에서는 다수 클래스의 인스턴스 수를 줄여 소수 클래스와 동일하게 만든다. 이를 수행하는 한 가지 간단한 방법은 다수 클래스의 인스턴스를 무작위로 선택하는 것이다. 예를 들어, 다수 클래스의 인스턴스가 900개이고 소수 클래스의 인스턴스가 400개인 경우 다수 클래스의 인스턴스 400개를 무작위로 선택하여 다수 클래스를 과소 샘플링할 수 있다. imblearn의 RandomUnderSampler를 사용하여 이를 수행할 수 있다.
from imblearn.under_sampling import RandomUnderSampler
sampler = RandomUnderSampler(random_state = 0)
x_resampled , y_resampled = sampler.fit_resample(X, y)
오버샘플링 (OverSampling)
데이터 균형을 맞추는 또 다른 방법은 소수 클래스의 인스턴스를 더 많이 만드는 것이다. 이를 달성하는 가장 쉬운 방법은 소수 클래스의 무작위 인스턴스를 복사하는 것이다. Imblearn은 이를 위해 RandomOverSampler를 제공한다. 샘플 반복이 문제인 경우 RandomOverSampler에는 데이터를 약간 오프셋하기 위해 매개변수 축소 기능이 있다. shrinkage를 사용하려면 데이터가 숫자여야 한다.
from imblearn.under_sampling import RandomUnderSampler
sampler = RandomUnderSampler(random_state = 0)
x_resampled , y_resampled = sampler.fit_resample(X, y)
이 외에도 데이터를 오버샘플링하는 인기 있는 기술이 하나 더 있다. 바로 합성 소수 오버샘플링 기술 (SMOTE)이다. RandomOverSampler가 소수 클래스의 원본 샘플 중 일부를 복제하여 오버샘플링하는 동안 SMOTE는 보간을 통해 새 샘플을 생성한다.
from imblearn.over_sampling import SMOTE
sampler = SMOTE()
X_resampled , y_resampled = sampler.fit_resample(X,y)
SMOTE의 한 가지 문제는 숫자 데이터만 가져야 한다는 것입니다. 범주형 데이터만 있는 경우 SMOTEN 변형을 사용할 수 있다. 범주형 데이터와 숫자형 데이터가 혼합된 경우 SMOTENC 변형을 사용할 수 있다. SMOTENC는 categorical_features 매개변수를 통해 범주형 기능의 인덱스를 가져온다.
from imblearn.over_sampling import SMOTEN , SMOTENC
#use SMOTEN if you only have categorical data
smote_n = SMOTEN()
X1_resampled , y1_resampled = smote_n.fit_resample(X,y)
#use SMOTENC if you have mix of categorical and numerical data
smote_nc = SMOTENC(categorical_features = [0,2]) #here 0 and 2 are the indices of categorical columns
X2_resampled , y2_resampled = smote_nc.fit_resample(X, y)
앙상블 (Ensemble) 방법
이 기술을 이해하기 위해 3000개의 인스턴스가 있는 다수 클래스와 1000개의 인스턴스가 있는 소수 클래스가 있는 데이터가 있다고 가정한다. 이제 각각 다수 클래스의 서로 다른 1000개의 인스턴스와 소수 클래스의 동일한 1000개의 인스턴스를 갖는 3개의 서로 다른 모델을 만들 수 있다. 예측 시 투표를 통해 예측한다. 즉, 모델 1이 클래스 0을 예측하고 모델 2와 모델 3이 클래스 1을 예측하면 최종 예측은 1이 된다.
Imblearn은 scikit-learn의 추정기를 매개변수로 사용하는 BalancedBaggerClassifier를 제공한다. 원하는 샘플링 전략, 추정기 수 등을 결정할 수도 있다.
from sklearn.tree import DecisionTreeClassifier
from imblearn.ensemble import BalancedBaggingClassifier
#here i have used DecisionTree as base estimator, you can use any.
bbc = BalancedBaggingClassifier(base_estimator = DecisionTreeClassifier(),
sampling_strategy = 'auto',
random_state = 0 )
#just like scikit-learn
bbc.fit(X_train , y_train)
y_pred = bbc.predict(X_test)
Balancing your imbalanced data
Nothing is good in nature if it is more than the required quantity. A higher amount of CO₂ will warm the planet, a higher amount of rain…
medium.com
'Data-driven Methodology > DS (Data Science)' 카테고리의 다른 글
| [Data Science] 주성분 분석 (Principal Component Analysis, PCA) (0) | 2023.10.30 |
|---|---|
| [Data Science] Random UnderSampling (0) | 2023.10.04 |
| [Data Science] 데이터 불균형 (0) | 2023.09.06 |
| [Data Science] 탐색적 데이터 분석 (Exploratory Data Analysis) (0) | 2023.07.17 |
| [Data Science] 모델 평가 (0) | 2022.11.29 |



