728x90
반응형
SMALL
Surface Crack Detection

Surface Crack Detection은 콘크리트 표면 결함 (concrete surface crack)을 발견하고 예측하기 위한 Kaggle의 공개 데이터이다. 평균적으로 227 x 227 크기를 가지는 color 이미지이며, crack 없는 Negative 데이터 2만개와 crack 발생한 Positive 데이터 2만개, 총 4만 개의 이미지 데이터로 구성되어 있다. 코랩에서 하고자 할 때 zip 파일을 구글 드라이브에 저장하고 마운트한다.
import os
import tensorflow as tf
import tensorflow as tf
from tensorflow.keras.layers import Dropout, Dense, Conv2D, GlobalAveragePooling2D, MaxPool2D
from tensorflow.keras.models import Sequential
print(os.getcwd())
print(os.listdir())/content
['gdrive', 'sample_data']from google.colab import drive
drive.mount('/content/gdrive/')Mounted at /content/gdrive/print(os.getcwd())
print(os.listdir())['gdrive', 'sample_data']import shutil
try:
shutil.copy('/content/gdrive/My Drive/Colab Notebooks/surface_crack.zip', '/content/')
except Exception as err:
print(str(err))
print(os.getcwd())
print(os.listdir())/content
['surface_crack.zip', 'gdrive', 'sample_data']if os.path.exists(DATA_ROOT_DIR): # 작업 디렉토리 surface_crack
shutil.rmtree(DATA_ROOT_DIR)
print(DATA_ROOT_DIR + ' is removed.')
ROOT_DIR = '/content'
DATA_ROOT_DIR = os.path.join(ROOT_DIR, 'surface_crack')
TRAIN_DATA_ROOT_DIR = os.path.join(DATA_ROOT_DIR, 'train')
TEST_DATA_ROOT_DIR = os.path.join(DATA_ROOT_DIR, 'test')/content/surface_crack is removed.# 압축파일 풀기
import zipfile
with zipfile.ZipFile(os.path.join(ROOT_DIR, 'surface_crack.zip'), 'r') as target_file:
target_file.extractall(DATA_ROOT_DIR)
# 데이터 전체 개수 확인
import glob
# 데이터 정답 (label) 개수 및 종류 확인
label_name_list = os.listdir('/content/surface_crack/')
print('total label nums = ', len(label_name_list))
print('=================================================')
print(label_name_list)
for label_name in label_name_list:
label_dir = os.path.join(DATA_ROOT_DIR, label_name)
print('train label : ' + label_name + ' => ', len(os.listdir(os.path.join(DATA_ROOT_DIR, label_name))))total label nums = 2
=================================================
['Negative', 'Positive']
train label : Negative => 20000
train label : Positive => 20000try:
shutil.copytree(DATA_ROOT_DIR, TRAIN_DATA_ROOT_DIR)
except Exception as err:
print(str(err))
# Positive / Negative 전체 데이터 개수 확인
label_name_list = os.listdir(TRAIN_DATA_ROOT_DIR)
print(label_name_list)
for label_name in label_name_list:
label_dir = os.path.join(TRAIN_DATA_ROOT_DIR, label_name)
print('train label : ' + label_name + ' => ', len(os.listdir(os.path.join(TRAIN_DATA_ROOT_DIR, label_name))))
print('=====================================================')['Negative', 'Positive']
train label : Negative => 20000
train label : Positive => 20000
=====================================================
디렉토리
# test dir 생성
if not os.path.exists(TEST_DATA_ROOT_DIR):
os.mkdir(TEST_DATA_ROOT_DIR)
print(TEST_DATA_ROOT_DIR + ' is created.')
else:
print(TEST_DATA_ROOT_DIR + ' already exists.')
# test/Positive 생성
if not os.path.exists(os.path.join(TEST_DATA_ROOT_DIR, 'Positive')):
os.mkdir(os.path.join(TEST_DATA_ROOT_DIR, 'Positive'))
print(os.path.join(TEST_DATA_ROOT_DIR, 'Positive') + ' is created.')
else:
print(os.path.join(TEST_DATA_ROOT_DIR, 'Positive') + ' already exists.')
# test/Negative 생성
if not os.path.exists(os.path.join(TEST_DATA_ROOT_DIR, 'Negative')):
os.mkdir(os.path.join(TEST_DATA_ROOT_DIR, 'Negative'))
print(os.path.join(TEST_DATA_ROOT_DIR, 'Negative') + ' is created.')
else:
print(os.path.join(TEST_DATA_ROOT_DIR, 'Negative') + ' already exists.')/content/surface_crack/test already exists.
/content/surface_crack/test/Positive already exists.
/content/surface_crack/test/Negative already exists.
데이터셋
# 파일 move 비율
MOVE_RATIO = 0.2 # train : test = 80 : 20, 즉 train 데이터 20% 데이터를 test 데이터로 사용
import random
# 파일 move train_data_dir => test_data_dir
label_name_list = os.listdir(TRAIN_DATA_ROOT_DIR)
for label_name in label_name_list:
# 파일 move 하기 위한 src_dir_path, dst_dir_path 설정
src_dir_path = os.path.join(TRAIN_DATA_ROOT_DIR,label_name) # /content/surfae_crack/train/Positive
dst_dir_path = os.path.join(TEST_DATA_ROOT_DIR,label_name) # /content/surfae_crack/test/Positive
train_data_file_list = os.listdir(src_dir_path)
print('========================================================================')
print('total [%s] data file nums => [%s]' % (label_name ,len(train_data_file_list)))
# data shuffle
random.shuffle(train_data_file_list)
print('train data shuffle is done !!!')
split_num = int(MOVE_RATIO*len(train_data_file_list))
print('split nums => ', split_num)
# extract test data from train data
test_data_file_list = train_data_file_list[0:split_num]
move_nums = 0
for test_data_file in test_data_file_list:
try:
shutil.move(os.path.join(src_dir_path, test_data_file),
os.path.join(dst_dir_path, test_data_file))
except Exception as err:
print(str(err))
move_nums = move_nums + 1
print('total move nums => ', move_nums)
print('========================================================================')========================================================================
total [Negative] data file nums => [20000]
train data shuffle is done !!!
split nums => 4000
total move nums => 4000
========================================================================
========================================================================
total [Positive] data file nums => [20000]
train data shuffle is done !!!
split nums => 4000
total move nums => 4000
========================================================================# Positive / Negative 전체 데이터 개수 확인
label_name_list = os.listdir(TRAIN_DATA_ROOT_DIR)
print(label_name_list)
for label_name in label_name_list:
label_dir = os.path.join(TRAIN_DATA_ROOT_DIR, label_name)
print('train label : ' + label_name + ' => ', len(os.listdir(os.path.join(TRAIN_DATA_ROOT_DIR, label_name))))
print('=====================================================')
# test 파일 개수 확인
# Positive / Negative 전체 데이터 개수 확인
label_name_list = os.listdir(TEST_DATA_ROOT_DIR)
print(label_name_list)
for label_name in label_name_list:
label_dir = os.path.join(TEST_DATA_ROOT_DIR, label_name)
print('test label : ' + label_name + ' => ', len(os.listdir(os.path.join(TEST_DATA_ROOT_DIR, label_name))))
print('=====================================================')['Negative', 'Positive']
train label : Negative => 16000
train label : Positive => 16000
=====================================================
['Negative', 'Positive']
test label : Negative => 4000
test label : Positive => 4000
=====================================================
이미지 전처리
import cv2
import numpy as np
from datetime import datetime
IMG_WIDTH = 64 # 128 die
IMG_HEIGHT = 64 # 128 die
class_dict = { 'Negative' : 0, 'Positive' : 1 }
train_data_list = []
train_label_list = []
image_label_list = os.listdir(TRAIN_DATA_ROOT_DIR) # 정답이름
for label_name in image_label_list:
# 이미지 파일 읽어오기
file_path = os.path.join(TRAIN_DATA_ROOT_DIR, label_name)
img_file_list = glob.glob(file_path+'/*.jpg')
# 각각의 정답 디렉토리에 있는 이미지 파일, 즉 .jpg 파일 읽어서 리스트에 저장
for img_file in img_file_list:
try:
src_img = cv2.imread(img_file, cv2.IMREAD_COLOR)
src_img = cv2.resize(src_img, dsize=(IMG_WIDTH, IMG_HEIGHT))
src_img = cv2.cvtColor(src_img, cv2.COLOR_BGR2RGB)
train_data_list.append(src_img)
train_label_list.append(float(class_dict[label_name])) # 정답은 문자열 => 실수로 변환
except Exception as err:
print(str(err), img_file)
continue
# numpy 변환
x_train = np.array(train_data_list).astype('float32')
y_train = np.array(train_label_list).astype('float32')
print('x_train.shape = ', x_train.shape, ', y_train.shape = ', y_train.shape)x_train.shape = (32000, 64, 64, 3) , y_train.shape = (32000,)test_data_list = []
test_label_list = []
image_label_list = os.listdir(TEST_DATA_ROOT_DIR) # 정답이름
for label_name in image_label_list:
# 이미지 파일 읽어오기
file_path = os.path.join(TEST_DATA_ROOT_DIR, label_name)
img_file_list = glob.glob(file_path+'/*.jpg')
# 각각의 정답 디렉토리에 있는 이미지 파일, 즉 .jpg 파일 읽어서 리스트에 저장
for img_file in img_file_list:
try:
src_img = cv2.imread(img_file, cv2.IMREAD_COLOR)
src_img = cv2.resize(src_img, dsize=(IMG_WIDTH, IMG_HEIGHT))
src_img = cv2.cvtColor(src_img, cv2.COLOR_BGR2RGB)
test_data_list.append(src_img)
test_label_list.append(float(class_dict[label_name])) # 정답은 문자열을 실수로 변환
except Exception as err:
print(str(err), img_file)
continue
# numpy 변환
x_test = np.array(test_data_list).astype('float32')
y_test = np.array(test_label_list).astype('float32')
print('x_test.shape = ', x_test.shape, ', y_test.shape = ', y_test.shape)x_test.shape = (8000, 64, 64, 3) , y_test.shape = (8000,)random_index_list = random.sample( list(range(len(y_train))), 16)
print(random_index_list)
print(y_train[random_index_list])[26768, 2293, 848, 6614, 12895, 31046, 15937, 13000, 2381, 3953, 14649, 14232, 2336, 25731, 4839, 2283]
[1. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]
정규화
import matplotlib.pyplot as plt
x_train = x_train / 255.0
x_test = x_test / 255.0
class_names = { 0 : 'Negative', 1 : 'Positive'}
plt.figure(figsize=(9,9))
pos = 0
for i in random_index_list:
plt.subplot(4, 4, pos+1)
plt.title(str(class_names[y_train[i]]))
plt.xticks([]); plt.yticks([])
plt.imshow(x_train[i])
pos += 1
plt.tight_layout()
plt.show()
CNN 모델 구축
class_nums = len(os.listdir(TRAIN_DATA_ROOT_DIR)) # 정답개수
model = Sequential()
model.add(Conv2D(kernel_size=(3,3), filters=32, activation='relu', padding='same', input_shape=(IMG_WIDTH,IMG_HEIGHT,3)))
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(kernel_size=(3,3), filters=64, activation='relu', padding='same'))
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(kernel_size=(3,3), filters=128, activation='relu', padding='same'))
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(GlobalAveragePooling2D())
# 32개면 정확도가 낮음. 256은 약 98% 이나 trend 가 거칠다
# 512 일때 정확도가 더 높고 256에 비해 정확도와 손실값이 그나마 안정적이다
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(class_nums, activation='softmax'))
model.summary()Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 64, 64, 32) 896
max_pooling2d (MaxPooling2D (None, 32, 32, 32) 0
)
dropout (Dropout) (None, 32, 32, 32) 0
conv2d_2 (Conv2D) (None, 32, 32, 64) 18496
max_pooling2d_1 (MaxPooling (None, 16, 16, 64) 0
2D)
dropout_1 (Dropout) (None, 16, 16, 64) 0
conv2d_3 (Conv2D) (None, 16, 16, 128) 73856
max_pooling2d_2 (MaxPooling (None, 8, 8, 128) 0
2D)
dropout_2 (Dropout) (None, 8, 8, 128) 0
global_average_pooling2d (G (None, 128) 0
lobalAveragePooling2D)
dense (Dense) (None, 512) 66048
dropout_3 (Dropout) (None, 512) 0
dense_1 (Dense) (None, 2) 1026
=================================================================
Total params: 160,322
Trainable params: 160,322
Non-trainable params: 0
_________________________________________________________________from tensorflow.keras.callbacks import EarlyStopping
model.compile(loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(), metrics=['acc'])
earlystopping = EarlyStopping(monitor='val_loss', patience=5, verbose=1)
start_time = datetime.now()
hist = model.fit(x_train, y_train, epochs=30, validation_data=(x_test, y_test),
callbacks=[earlystopping])
end_time = datetime.now()
print('Elapsed Time => ', end_time-start_time)plt.plot(hist.history['acc'], label='train')
plt.plot(hist.history['val_acc'], label='validation')
plt.title('Accuracy Trend')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(loc='best')
plt.grid()
plt.show()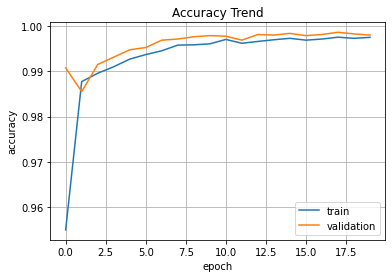
plt.plot(hist.history['loss'], label='train')
plt.plot(hist.history['val_loss'], label='validation')
plt.title('Loss Trend')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(loc='best')
plt.grid()
plt.show()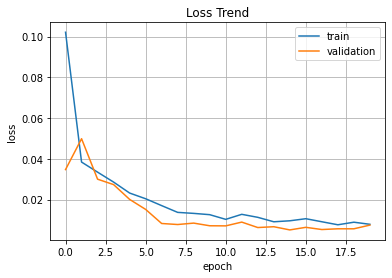
model.evaluate(x_test, y_test)250/250 [==============================] - 1s 4ms/step - loss: 0.0075 - acc: 0.9980
[0.007472064811736345, 0.9980000257492065]728x90
반응형
LIST
'Visual Intelligence > Image Deep Learning' 카테고리의 다른 글
| [시각 지능] 사전 학습 모델 (Pre-Trained Model) (0) | 2022.08.20 |
|---|---|
| [시각 지능] 전이 학습 (Transfer Learning) (0) | 2022.08.14 |
| [시각 지능] GTSRB (0) | 2022.08.13 |
| [시각 지능] Google Photos Prototype (0) | 2022.08.13 |
| [시각 지능] 사전 학습된 CIFAR-10 모델로 이미지 예측 (1) | 2022.08.13 |



