728x90
반응형
SMALL
전이 학습 (Transfer Learning)
CNN 기반의 딥러닝 모델을 훈련시키려면 많은 양의 데이터가 필요하지만 큰 데이터셋을 얻 는 것은 쉽지 않다. 이러한 현실적인 어려움을 해결한 것이 전이 학습인데, 전이 학습은 ImageNet처럼 아주 큰 데이터셋을 써서 사전 학습 모델 (pre-trained model)의 가중치를 가져와 분석하려는 데이터에 맞게 보정해서 사용하는 것을 의미한다.

특징 추출기 (feature extractor)는 컨볼루션 층과 풀링 층의 조합으로 구성되어 있으며 ImageNet 데이터에 대해 이미 학습되어 있다. 분류기 (classifier)는 완전 연결 층 (Dense) 조합으로 구성되며 이미지에 대한 정답을 분류하는 역할을 한다.
Cats and Dogs
고양이와 개 이미지의 집합이다. Cats and Dogs 데이터셋은 CNN 아키텍처를 구축하고 평가하기 위한 일종의 Hello World 라고 할 수 있다.
import os
import tensorflow as tf
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Dense, Dropout, Input
from tensorflow.keras.layers import Flatten, Conv2D, MaxPooling2D
!wget https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
print(os.getcwd())
print(os.listdir())/content
['.config', 'cats_and_dogs_filtered.zip', 'cats_and_dogs_filtered.zip.1', 'cats_and_dogs_filtered', 'sample_data']import shutil
if os.path.exists('/content/cats_and_dogs_filtered/'): # 작업 디렉토리 cats_and_dogs_filtered
shutil.rmtree('/content/cats_and_dogs_filtered/')
print('/content/cats_and_dogs_filtered/ is removed.')
# 압축파일 풀기
import zipfile
with zipfile.ZipFile('/content/cats_and_dogs_filtered.zip', 'r') as target_file:
target_file.extractall('/content/cats_and_dogs_filtered/')
import glob
# 데이터 정답 (label) 개수 및 종류 확인
cats_train_list = os.listdir('/content/cats_and_dogs_filtered/cats_and_dogs_filtered/train/cats')
dogs_train_list = os.listdir('/content/cats_and_dogs_filtered/cats_and_dogs_filtered/train/dogs')
cats_validation_list = os.listdir('/content/cats_and_dogs_filtered/cats_and_dogs_filtered/validation/cats')
dogs_validation_list = os.listdir('/content/cats_and_dogs_filtered/cats_and_dogs_filtered/validation/dogs')
print('cats train file nums = ', len(cats_train_list))
print('dogs train file nums = ', len(dogs_train_list))
print('cats validation file nums = ', len(cats_validation_list))
print('dogs validation file nums = ', len(cats_validation_list))
print('=================================================')cats train file nums = 1000
dogs train file nums = 1000
cats validation file nums = 500
dogs validation file nums = 500
=================================================
데이터 전처리
import cv2
import numpy as np
from datetime import datetime
image_list = []
label_list = []
train_base_dir = '/content/cats_and_dogs_filtered/cats_and_dogs_filtered/train/'
train_label_list = os.listdir(train_base_dir) # 정답이름
print('train label # => ', len(train_label_list))
start_time = datetime.now()
for train_label_name in train_label_list:
# cats => 0.0, dogs => 1.0 변환
if train_label_name == 'cats':
label_num = 0.0
elif train_label_name == 'dogs':
label_num = 1.0
# 이미지 파일 읽어오기
file_path = train_base_dir + train_label_name
train_img_file_list = glob.glob(file_path+'/*.jpg')
# 각각의 정답 디렉토리에 있는 이미지 파일, 즉 .jpg 파일 읽어서 리스트에 저장
for train_img_file in train_img_file_list:
train_img = cv2.imread(train_img_file, cv2.IMREAD_COLOR)
train_img = cv2.resize(train_img, dsize=(32,32)) # (32,32) 변환
train_img = cv2.cvtColor(train_img, cv2.COLOR_BGR2RGB)
image_list.append(train_img)
label_list.append(label_num)
# numpy 변환
x_train = np.array(image_list).astype('float32')
y_train = np.array(label_list).astype('float32')
print('x_train.shape = ', x_train.shape, ', y_train.shape = ', y_train.shape)
end_time = datetime.now()
print('train data generation time => ', end_time-start_time)train label # => 2
x_train.shape = (2000, 32, 32, 3) , y_train.shape = (2000,)
train data generation time => 0:00:06.264235image_list = []
label_list = []
validation_base_dir = '/content/cats_and_dogs_filtered/cats_and_dogs_filtered/validation/'
validation_label_list = os.listdir(validation_base_dir) # 정답이름
print('validation label # => ', len(validation_label_list))
start_time = datetime.now()
for validation_label_name in validation_label_list:
# cats => 0.0, dogs => 1.0 변환
if validation_label_name == 'cats':
label_num = 0.0
elif validation_label_name == 'dogs':
label_num = 1.0
# 이미지 파일 읽어오기
file_path = validation_base_dir + validation_label_name
validation_img_file_list = glob.glob(file_path+'/*.jpg')
# 각각의 정답 디렉토리에 있는 이미지 파일, 즉 .jpg 파일 읽어서 리스트에 저장
for validation_img_file in validation_img_file_list:
validation_img = cv2.imread(validation_img_file, cv2.IMREAD_COLOR)
validation_img = cv2.resize(validation_img, dsize=(32,32)) # (32, 32) 변환
validation_img = cv2.cvtColor(validation_img, cv2.COLOR_BGR2RGB)
image_list.append(validation_img)
label_list.append(label_num)
# numpy 변환
x_val = np.array(image_list).astype('float32')
y_val = np.array(label_list).astype('float32')
print('x_val.shape = ', x_val.shape, ', y_val.shape = ', y_val.shape)
end_time = datetime.now()
print('validation data generation time => ', end_time-start_time)validation label # => 2
x_val.shape = (1000, 32, 32, 3) , y_val.shape = (1000,)
validation data generation time => 0:00:03.148208# validation data random shuffle
s = np.arange(len(x_val))
# index random shuffle
np.random.shuffle(s)
# x_val, y_val 재 생성
x_val = x_val[s]
y_val = y_val[s]
# validation, test data 분리
ratio = 0.5
split_num = int(ratio*len(x_val))
print('split num => ', split_num)
x_test = x_val[0:split_num]
y_test = y_val[0:split_num]
x_val = x_val[split_num:]
y_val = y_val[split_num:]
print('x_val.shape = ', x_val.shape, ', y_val.shape = ', y_val.shape)
print('x_test.shape = ', x_test.shape, ', y_test.shape = ', y_test.shape)
# 정규화
x_train = x_train / 255.0
x_val = x_val / 255.0
x_test = x_test / 255.0split num => 500
x_val.shape = (500, 224, 224, 3) , y_val.shape = (500,)
x_test.shape = (500, 224, 224, 3) , y_test.shape = (500,)
CNN 모델 구축
model = Sequential()
model.add(Conv2D(32, (3,3), activation='relu', padding='SAME', input_shape=(224,224,3)))
model.add(Conv2D(32, (3,3), activation='relu', padding='SAME'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3,3), activation='relu', padding='SAME'))
model.add(Conv2D(64, (3,3), activation='relu', padding='SAME'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(128, (3,3), activation='relu', padding='SAME'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(128, (3,3), activation='relu', padding='SAME'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(256, (3,3), activation='relu', padding='SAME'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(8, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(2, activation='softmax'))
model.summary()Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_14 (Conv2D) (None, 224, 224, 32) 896
conv2d_15 (Conv2D) (None, 224, 224, 32) 9248
max_pooling2d_10 (MaxPoolin (None, 112, 112, 32) 0
g2D)
dropout_12 (Dropout) (None, 112, 112, 32) 0
conv2d_16 (Conv2D) (None, 112, 112, 64) 18496
conv2d_17 (Conv2D) (None, 112, 112, 64) 36928
max_pooling2d_11 (MaxPoolin (None, 56, 56, 64) 0
g2D)
dropout_13 (Dropout) (None, 56, 56, 64) 0
conv2d_18 (Conv2D) (None, 56, 56, 128) 73856
max_pooling2d_12 (MaxPoolin (None, 28, 28, 128) 0
...
Total params: 682,554
Trainable params: 682,554
Non-trainable params: 0
_________________________________________________________________from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
model.compile(loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(), metrics=['acc'])
save_file_name = './cats_and_dogs_Native_Colab.h5'
checkpoint = ModelCheckpoint(save_file_name, # file명 지정
monitor='val_loss', # val_loss 값이 개선되었을 때 호출
verbose=1, # 로그 출력
save_best_only=True, # 가장 best 값만 저장
mode='auto' # auto는 알아서 best를 찾음 (min/max)
)
earlystopping = EarlyStopping(monitor='val_loss', # 모니터 기준 설정 (val loss)
patience=5, # 5회 Epoch동안 개선되지 않는다면 종료
)
start_time = datetime.now()
hist = model.fit(x_train, y_train,
epochs=30, batch_size=16,
validation_data=(x_val, y_val))
end_time = datetime.now()
print('Elapsed Time => ', end_time-start_time)import matplotlib.pyplot as plt
plt.plot(hist.history['acc'], label='train')
plt.plot(hist.history['val_acc'], label='validation')
plt.title('Accuracy Trend')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(loc='best')
plt.grid()
plt.show()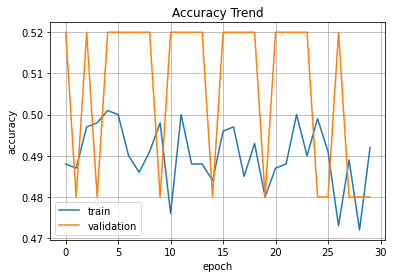
plt.plot(hist.history['loss'], label='train')
plt.plot(hist.history['val_loss'], label='validation')
plt.title('Loss Trend')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(loc='best')
plt.grid()
plt.show()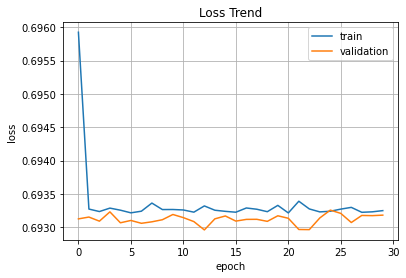
사전 학습 모델
image_list = []
label_list = []
train_base_dir = '/content/cats_and_dogs_filtered/cats_and_dogs_filtered/train/'
train_label_list = os.listdir(train_base_dir) # 정답이름
print('train label # => ', len(train_label_list))
start_time = datetime.now()
for train_label_name in train_label_list:
# cats => 0.0, dogs => 1.0 변환
if train_label_name == 'cats':
label_num = 0.0
elif train_label_name == 'dogs':
label_num = 1.0
# 이미지 파일 읽어오기
file_path = train_base_dir + train_label_name
train_img_file_list = glob.glob(file_path+'/*.jpg')
# 각각의 정답 디렉토리에 있는 이미지 파일, 즉 .jpg 파일 읽어서 리스트에 저장
for train_img_file in train_img_file_list:
train_img = cv2.imread(train_img_file, cv2.IMREAD_COLOR)
train_img = cv2.resize(train_img, dsize=(224,224)) # (224,224) 변환
train_img = cv2.cvtColor(train_img, cv2.COLOR_BGR2RGB)
image_list.append(train_img)
label_list.append(label_num)
# numpy 변환
x_train = np.array(image_list).astype('float32')
y_train = np.array(label_list).astype('float32')
print('x_train.shape = ', x_train.shape, ', y_train.shape = ', y_train.shape)
end_time = datetime.now()
print('train data generation time => ', end_time-start_time)from tensorflow.keras.applications import VGG16, ResNet50, MobileNet, InceptionV3
pre_trained_model = MobileNet(weights = 'imagenet', include_top = True, input_shape = (224, 224, 3))
pre_trained_model.summary()conv_dw_11_relu (ReLU) (None, 14, 14, 512) 0
conv_pw_11 (Conv2D) (None, 14, 14, 512) 262144
conv_pw_11_bn (BatchNormali (None, 14, 14, 512) 2048
zation)
conv_pw_11_relu (ReLU) (None, 14, 14, 512) 0
conv_pad_12 (ZeroPadding2D) (None, 15, 15, 512) 0
conv_dw_12 (DepthwiseConv2D (None, 7, 7, 512) 4608
)
conv_dw_12_bn (BatchNormali (None, 7, 7, 512) 2048
zation)
conv_dw_12_relu (ReLU) (None, 7, 7, 512) 0
conv_pw_12 (Conv2D) (None, 7, 7, 1024) 524288
conv_pw_12_bn (BatchNormali (None, 7, 7, 1024) 4096
zation)
conv_pw_12_relu (ReLU) (None, 7, 7, 1024) 0
conv_dw_13 (DepthwiseConv2D (None, 7, 7, 1024) 9216
)
conv_dw_13_bn (BatchNormali (None, 7, 7, 1024) 4096
zation)
conv_dw_13_relu (ReLU) (None, 7, 7, 1024) 0
conv_pw_13 (Conv2D) (None, 7, 7, 1024) 1048576
conv_pw_13_bn (BatchNormali (None, 7, 7, 1024) 4096
zation)
conv_pw_13_relu (ReLU) (None, 7, 7, 1024) 0
global_average_pooling2d (G (None, 1, 1, 1024) 0
lobalAveragePooling2D)
dropout (Dropout) (None, 1, 1, 1024) 0
conv_preds (Conv2D) (None, 1, 1, 1000) 1025000
reshape_2 (Reshape) (None, 1000) 0
predictions (Activation) (None, 1000) 0
=================================================================
Total params: 4,253,864
Trainable params: 4,231,976
Non-trainable params: 21,888
_________________________________________________________________image_list = []
label_list = []
validation_base_dir = '/content/cats_and_dogs_filtered/cats_and_dogs_filtered/validation/'
validation_label_list = os.listdir(validation_base_dir) # 정답이름
print('validation label # => ', len(validation_label_list))
start_time = datetime.now()
for validation_label_name in validation_label_list:
# cats => 0.0, dogs => 1.0 변환
if validation_label_name == 'cats':
label_num = 0.0
elif validation_label_name == 'dogs':
label_num = 1.0
# 이미지 파일 읽어오기
file_path = validation_base_dir + validation_label_name
validation_img_file_list = glob.glob(file_path+'/*.jpg')
# 각각의 정답 디렉토리에 있는 이미지 파일, 즉 .jpg 파일 읽어서 리스트에 저장
for validation_img_file in validation_img_file_list:
validation_img = cv2.imread(validation_img_file, cv2.IMREAD_COLOR)
validation_img = cv2.resize(validation_img, dsize=(224,224)) # (224,224) 변환
validation_img = cv2.cvtColor(validation_img, cv2.COLOR_BGR2RGB)
image_list.append(validation_img)
label_list.append(label_num)
# numpy 변환
x_val = np.array(image_list).astype('float32')
y_val = np.array(label_list).astype('float32')
print('x_val.shape = ', x_val.shape, ', y_val.shape = ', y_val.shape)
end_time = datetime.now()
print('validation data generation time => ', end_time-start_time)
# 이미지 데이터 정규화
x_train = x_train / 255.0
x_val = x_val / 255.0
x_test = x_test / 255.0
MobileNet
base_model = MobileNet(weights='imagenet', include_top=False, input_shape=(224,224,3))
model = Sequential()
model.add(base_model)
model.add(Flatten()) # 또는 GlobalAveragePooling2D()
model.add(Dense(16, activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(2, activation='softmax'))
model.summary()from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
from datetime import datetime
model.compile(loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(2e-5), metrics=['acc'])
save_file_name = './mobilenet.h5'
checkpoint = ModelCheckpoint(save_file_name, # file 명 지정
monitor='val_loss', # val_loss 값이 개선되었을 때 호출
verbose=1, # 로그 출력
save_best_only=True, # 가장 best 값만 저장
mode='auto' # auto는 min/max best 값을 찾음
)
earlystopping = EarlyStopping(monitor='val_loss', # 모니터 기준 설정 (val loss)
patience=5, # 5회 Epoch동안 개선되지 않는다면 종료
)
start_time = datetime.now()
hist = model.fit(x_train, y_train,
epochs=10, batch_size=16, # batch_size는 시스템 메모리에 맞게 설정
validation_data=(x_val, y_val))
end_time = datetime.now()
print('Elapsed Time => ', end_time-start_time)
728x90
반응형
LIST
'Visual Intelligence > Image Deep Learning' 카테고리의 다른 글
| [시각 지능] Image Data Augmentation (0) | 2022.08.20 |
|---|---|
| [시각 지능] 사전 학습 모델 (Pre-Trained Model) (0) | 2022.08.20 |
| [시각 지능] Surface Crack Detection (0) | 2022.08.14 |
| [시각 지능] GTSRB (0) | 2022.08.13 |
| [시각 지능] Google Photos Prototype (0) | 2022.08.13 |



