EfficientNet
Resnet이 이미지 분류 분야의 전반적인 성능을 높인 이후 CNN은 성능에 초점을 맞추거나, 효율에 초점을 두는 두가지 방향으로 발전하였다. CNN의 성능을 올리기 위해 scaling up을 시도하는 것이 매우 일 반적인 일이었는데 그 예로 ResNet은 ResNet-18부터 ResNet-200까지 망의 깊이를 늘려 성능 향상을 이루었다. 신경망의 성능을 내기 위해 네트워크 모델의 크기를 키우는 이러한 scalingup 방식은 대표적으로 채널의 개수를 늘리는 width scaling, 레이어의 개수를 늘리는 depth scaling, 그리고 입력 영상의 해상도를 높이는 resolution scaling이 사용된다.
| 1) Width : 기존의 연구에 따르면 width를 넓게 할수록 미세한 정보들을 더 많이 담을 수 있다는 것이 알려져 있다. 2) Depth : 가장 흔한 scaling-up 방법으로 깊은 망은 더 높은 성능을 내는 것을 잘 알려진 사실이지만 이를 계속 깊게 쌓는 것은 한계가 있다. 그 예로 ResNet-1000은 ResNet-101과 거의 비슷한 성능을 가지고 있다. 3) Resolution : 입력에 더 큰 영상을 넣으면 성능이 올라가는 것은 실험을 통해 입증되어 있다. |
ResNet이 depth scaling을 통해 모델의 크기를 조절하는 대표적인 모델이며 MobileNet, ShuffleNet 등이 width scaling을 통해 모델의 크기를 조절하는 대표적인 모델이다. 하지만 기존 방식에서는 위의 3가지 scaling을 동시에 고려하는 경우가 거의 없었다.
또한, scaling 기법 중에 어떤 기법을 사용할지에 대해서도 마땅한 가이드라인이 존재하지 않고, 실제로 무작정 키운다고 정확도가 계속 오르는 것도 아니라 일일이 실험을 해봐야하는 어려움도 존재하였다.

| FLOPS (Floating point Operations Per Second) : 컴퓨터의 성능을 수치로 나타낼 때 주로 사용되는 단위 |
Width/depth/resolution을 각각 키웠을 때의 결과이다. Width scaling, depth scaling은 비교적 이른 시점에 정확도가 saturation되며 그나마 resolution scaling이 키우면 키울수록 정확도가 잘 오르는 것 을 확인할 수 있었다. 키울수록 성능을 올라가지만 얻어지는 이득이 적어지는 것을 알 수 있다.
비슷한 방식으로 depth와 resolution을 고정하고 Width의 증가에 따른 성능 변화를 실험해본 결과, 같은 FLOPS임에도 불구하고 크게는 1.5%까지 정확도가 날 수 있음을 알아냈다. 초록색 선과 노란색 선을 비교해 보면, Depth와 Resolution을 변경하지 않은 상태에서는 금방 Width의 증가에 따른 성능 증가가 saturation되지만 Depth와 Resolution을 같이 늘려줄 경우, 천천히 포화되는 모습을 볼 수 있다.
EfficientNet은 제한된 리소스 범위 내에서 3가지 scaling-up 방식에 대한 최적의 조합을 어떻게 찾을 수 있는지 연구하였고 압도적으로 적은 parameter 수로 뛰어난 성능을 낼 수 있도록 하였다. 직관적으로 생각해보았을 때, 높은 해상도 (Resolution)를 가진 이미지를 CNN의 input으로 넣게 되면 그로부터 더욱 잘 정제된 특징을 여러 개의 필터들 (Width)이 학습할 수 있고, 더 큰 receptive field로부터 더욱더 추상적인 특징을 CNN 레이어 (Depth)에서 학습할 수 있다. 따라서, 각 요소들을 같이 증가시켜주게 되며 더욱 큰 시너지 효과를 기대할 수 있을 것이다.
Compound Scaling
EfficientNet의 저자는 3가지 요소들을 조화롭게 사용하는 Compound scaling method를 제안하여, CNN의 width, depth, resolution을 함께 늘려 컴퓨팅 리소스에 비례하여 효율적인 CNN 모델을 만들 수 있었다.
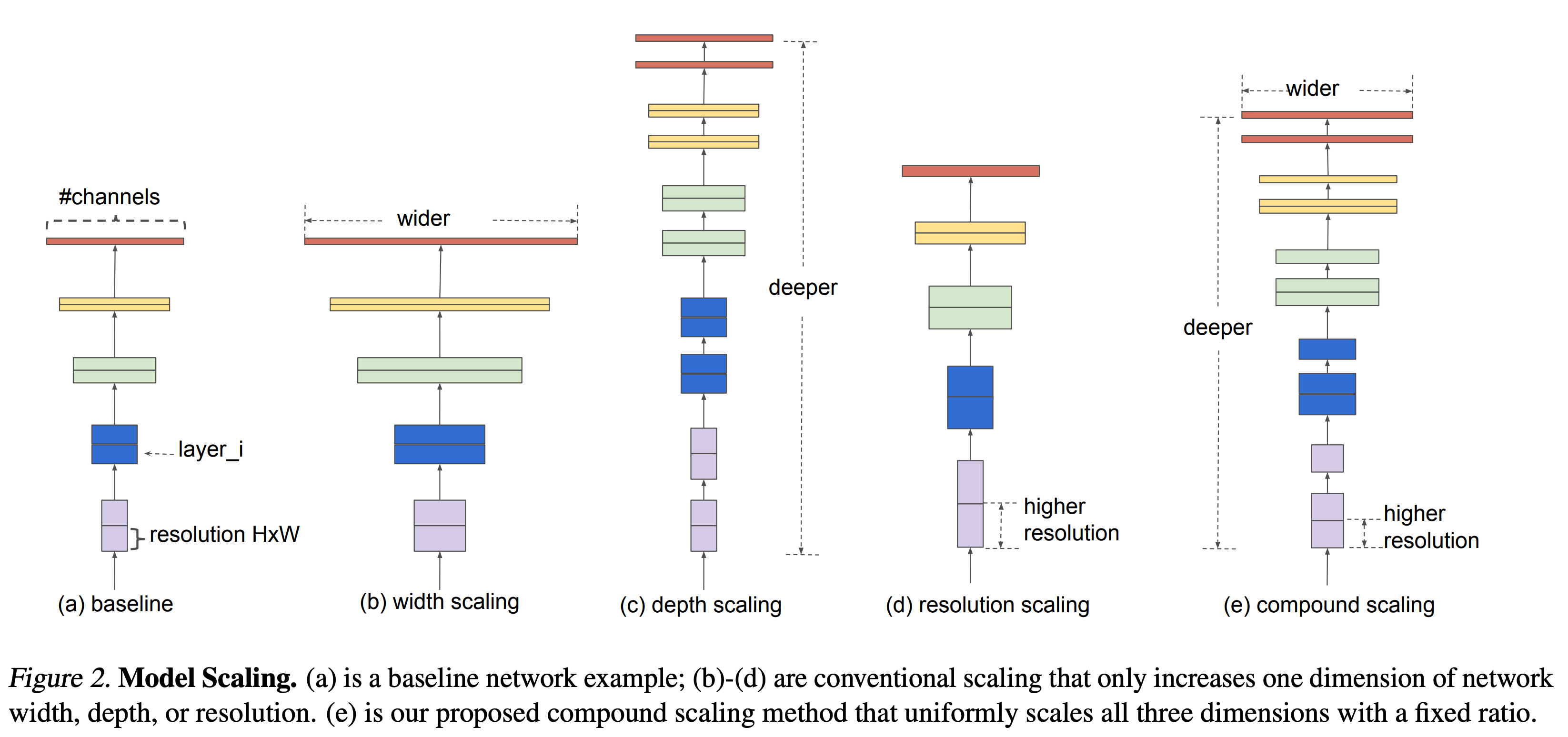
Compound Scaling method는 d, w, r은 서로 독립적인 관계가 아니며 리소스의 제약이 존재한다는 조건 하에서 CNN의 Width, Depth, Resolution을 함께 늘려준다. 연구 하에 제안된 Compound scaling method는 다음과 같이 표현될 수 있다.
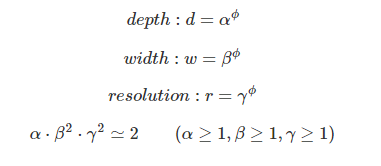
𝛼, 𝛽, 𝛾값을 grid search를 이용해 찾고 𝜙를 사용자가 원하는 컴퓨팅 리소스를 고려해서 늘려주게 되면, 컴퓨팅 리소스에 비례해 성능이 증가하는 효율적인 CNN 모델을 가질 수 있다. 이때, width와 resolution에 제곱이 들어간 이유는 depth는 2배로 키워주면 FLOPS도 비례해서 2배 증가하지만, width와 resolution은 가로와 세로가 각각 곱해지기 때문에 제곱 배 증가한다. 따라서, 제곱을 곱해 계산을 해야 한다. 그 뒤 전체 모델의 크기는 𝛼, 𝛽, 𝛾에 똑같은 𝜙만큼 제곱하여 조절을 하게 된다. 연구에서 찾아낸 변수의 값은 𝛼=1.2, 𝛽=1.1, 𝛾=1.15이다.
| 하이퍼 파라미터 (Hyper parameter, 초매개변수) |
모델을 생성할 때, 사용자가 직접 설정하는 변수 ex) 레이어의 개수, 학습횟수의 수 cf) 파라미터 (매개변수)는 학습 과정에서 생성되는 변수들로, 딥러닝 모델의 학습 가중치들이 파라미터에 해당된다. |
| Grid Search | Grid Search는 모델 하이퍼 파라미터에 넣을 수 있는 값들을 순차적으로 입력한 뒤에 가장 높은 성능을 보이는 하이퍼 파라미터들을 찾는 탐색 방법이다. |
모델 스케일링의 효과는 기준 네트워크에 크게 의존하기 때문에 저자는 성능을 향상시키기 위해 AutoML MNAS 프레임워크를 사용하여 신경 아키텍처 검색을 수행하여 정확도와 효율성 (FLOPS)을 모두 최적화한 새로운 기준 네트워크 (EfficientNet-B0)를 개발하였다. 컴퓨팅 리소스 양에 따라 확장할 경우 그 크기에 따라 EfficientNet B0 (가장 작은 모델) ~ B7 (가장 큰 모델) 모델로 이름 붙일 수 있다. 이때, EfficientNet-B0을 시작으로 다음 순서에 따라 scale을 확장한다.
| Step 1. 𝛼, 𝛽, 𝛾 탐색 먼저 𝜙 = 1로 고정한 뒤 grid search를 수행하여 𝛼, 𝛽, 𝛾를 찾는다 이때 위의 식을 만족해야 한다. Step 2. 𝛼, 𝛽, 𝛾 값을 고정한 뒤 서로 다른 𝜙값을 조절하여 모델을 만든다. |
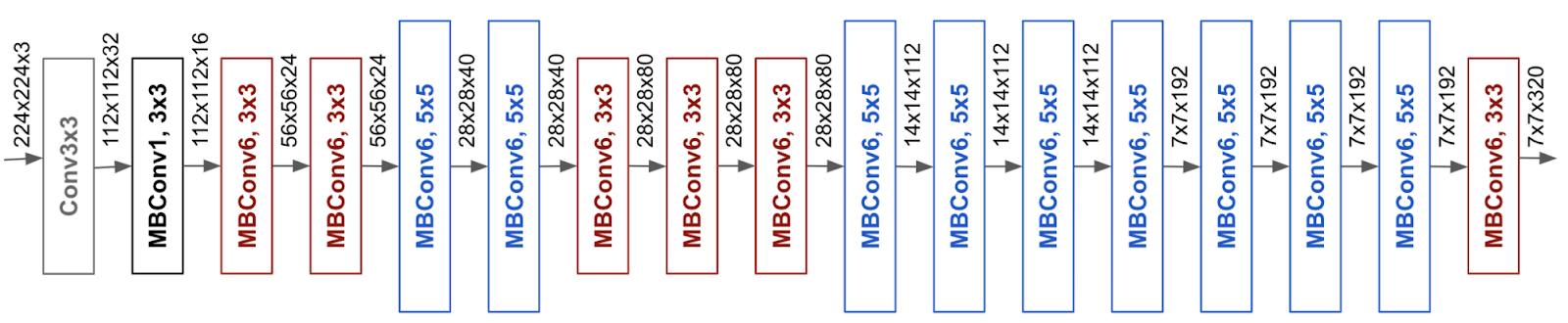
연구에서 사용된 base 모델은 기존 MNasNet보다 더 크고 SE Block을 추가한 형태로 구조는 다음의 그림과 같다.
EfficientNet은 ImageNet 데이터셋을 사용하여 다른 기존 CNN을 비교하였다.
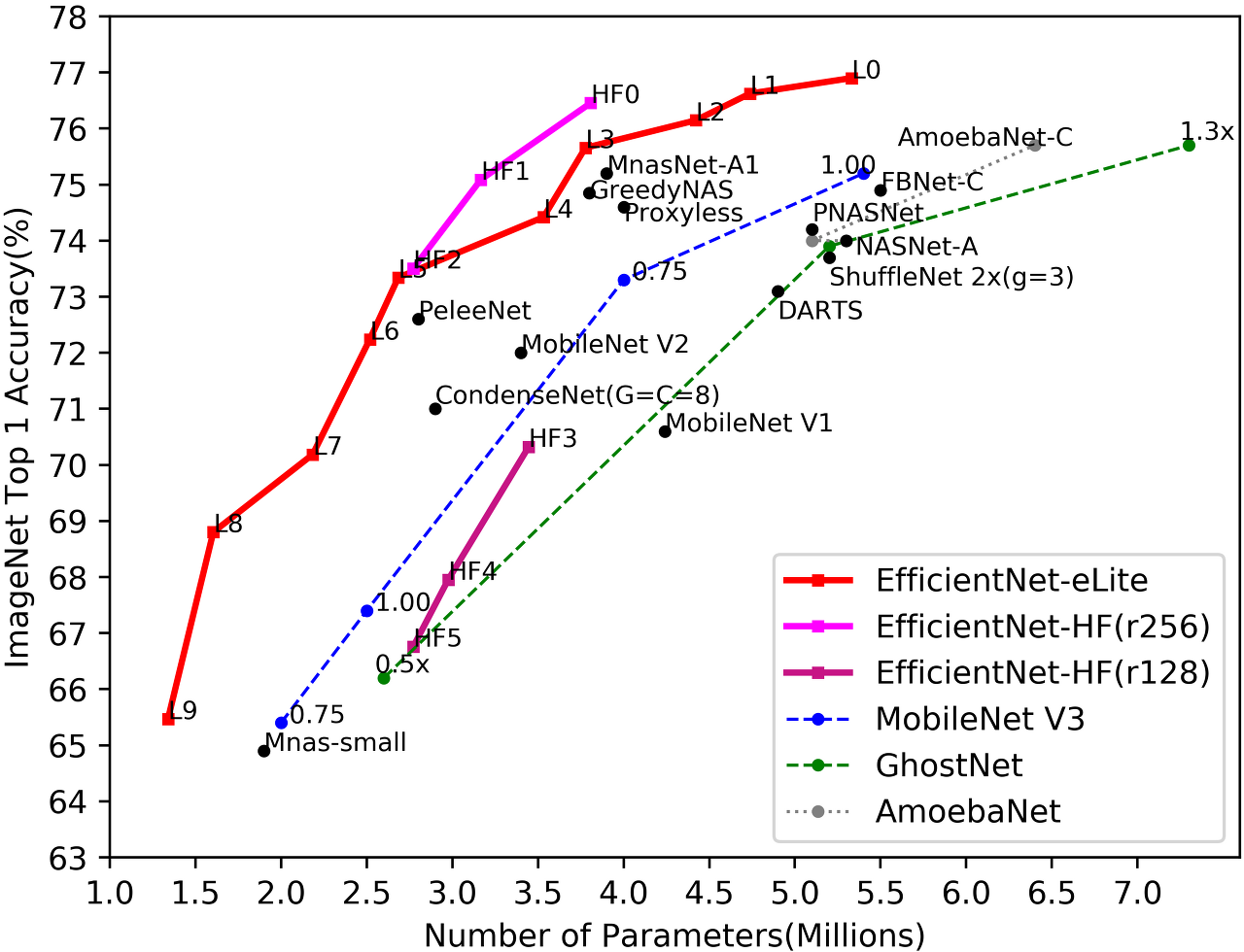
그래프에서와 같이 기존의 최신 CNN 모델들보다 더 높은 정확도를 보여주고 있으며 기존 모델들보다 적은 파라미터 수를 가지고 있어 매우 빠른 속도로 추론을 진행할 수 있기에 기존 모델보다 훨씬 효율적이라 할 수 있다
'Visual Intelligence > Image Classification' 카테고리의 다른 글
| [Image Classification] MobileNet V1 (0) | 2022.09.14 |
|---|---|
| [Image Classification] EfficientNet (cats-and-dogs) (0) | 2022.09.14 |
| [Image Classification] DenseNet (MNIST) (0) | 2022.09.14 |
| [Image Classification] DenseNet (0) | 2022.09.13 |
| [Image Classification] ResNet (2) (0) | 2022.09.13 |



