MobileNet V1
모바일, embedded vision 앱에서 사용되는 것을 목적으로 한 MobileNet이라는 효율적인 모델을 제시한다. Depth-wise separable convolutions라는 구조에 기반하며 2개의 단순한 hyper parameter를 가진다. 이 2가지는 사용되는 환경에 따라 적절히 선택하여 적당한 크기의 모델을 선택할 수 있게 한다. 수많은 실험을 통해 가장 좋은 성능을 보이는 설정을 찾았으며 타 모델에 비해 성능이 거의 떨어지지 않으면서 모델 크기는 몇 배까지 줄였다.

모델 크기를 줄이는 방법은 크게 2가지로 나뉘는데, 사전 학습된 네트워크를 압축하거나 작은 네트워크를 직접 학습하는 방식이다. 이외에도 모델을 잘 압축하거나 양자화, hashing, pruning 등이 사용되었다. MobileNet은 기본적으로 작은 모델이지만 latency를 최적화하는 데 초점을 맞춘다. MobileNets은 Depthwise separable convolutions을 사용한다.
Depthwise Separable Convolution
Factorized convolutions의 한 형태로, 표준 convolution을 Depthwise convolution (dwConv)과 Pointwise convolution (pwConv, 1×1 convolution)으로 쪼갠 것이다.
dwConv는 각 입력 채널당 1개의 filter를 적용하고, pwConv는 dwConv의 결과를 합치기 위해 1×1 conv를 적용한다. 이와 비교해서 표준 conv는 이 2가지 step이 하나로 합쳐져 있는 것이라 보면 된다. DSConv (depthwise separable convolution)은 이를 2개의 layer로 나누어 filtering을 위한 separate layer, combining을 위한 separate layer로 구성된다. 이는 모델 크기를 많이 줄일 수 있게 해 준다.

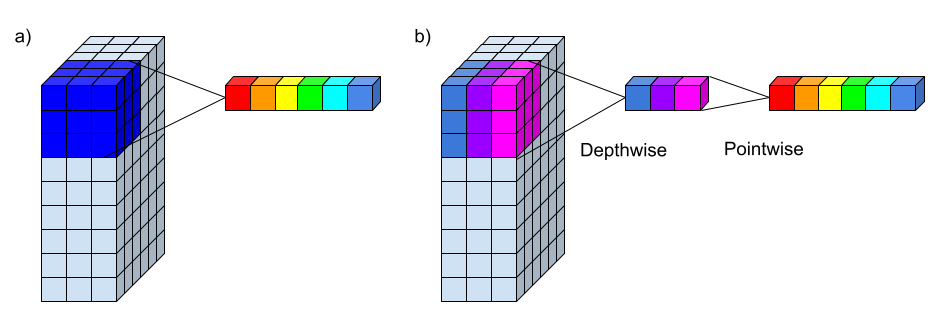
Network Structure

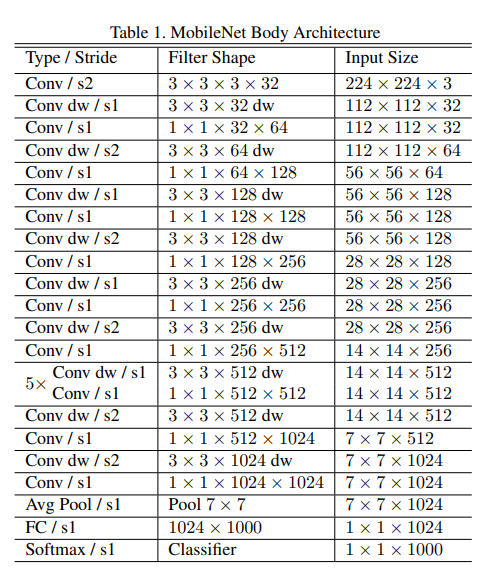
MobileNet은 맨 처음 layer를 full conv로 쓰는 것을 제외하면 전부 DSConv로 사용한다. dwConv는 표에는 Convdw라고 표시되어 있다. 1×1 conv를 수행하는 부분이 pwConv이다. Tensorflow 그리고 Inception V3와 비슷하게 asynchronous gradient descent를 사용하는 RMSProp으로 학습을 진행하였다. DSConv에는 parameter가 별로 없어서 weight decay는 사용하지 않는 것이 좋다.
Width Multiplier : Thinner Models
이미 충분히 작지만 더 빠르게 만들어야 하는 경우 width multiplier라 부르는 α 하이퍼 파라미터는 각 layer마다 얼마나 얇게 만드는지 결정한다. 입출력 채널 수는 M, N에서 αM, αN이 된다. α는 (0, 1]에 포함되며 0.25, 0.5, 0.75 등의 값을 쓸 수 있다. α=1은 기본 MobileNet이다. 이 α를 통해 얼마든지 작은 시스템에도 모델을 집어 넣어 사용할 수 있다. 물론 정확도, latency, 크기 사이에는 trade-off가 존재한다.
Resolution Multiplier: Reduced Represent
해상도에 관한 multiplier인 𝜌 하이퍼 파라미터는 입력 이미지와 각 레이어의 내부 표현 전부를 이 mulitiplierfmf 곱해 줄인다. 이 역시 α와 비슷하게 𝜌 (0, 1]에 포함되며 보통 이미지 해상도를 224, 192, 160, 128 정도로 만들게 한다. 계산량은 𝜌의 제곱에 비례하여 줄어든다.
Experiments
MobileNet을 여러 multiplier 등 여러 세팅을 바꿔가면서 실험한 결과인데, 주로 성능 하락 은 크지 않으면서도 모델 크기나 계산량이 줄었음을 보여준다. 혹은 정확도는 낮아도 크기 가 많이 작기 때문에 여러 embedded 환경에서 쓸만하다는 주장을 한다.
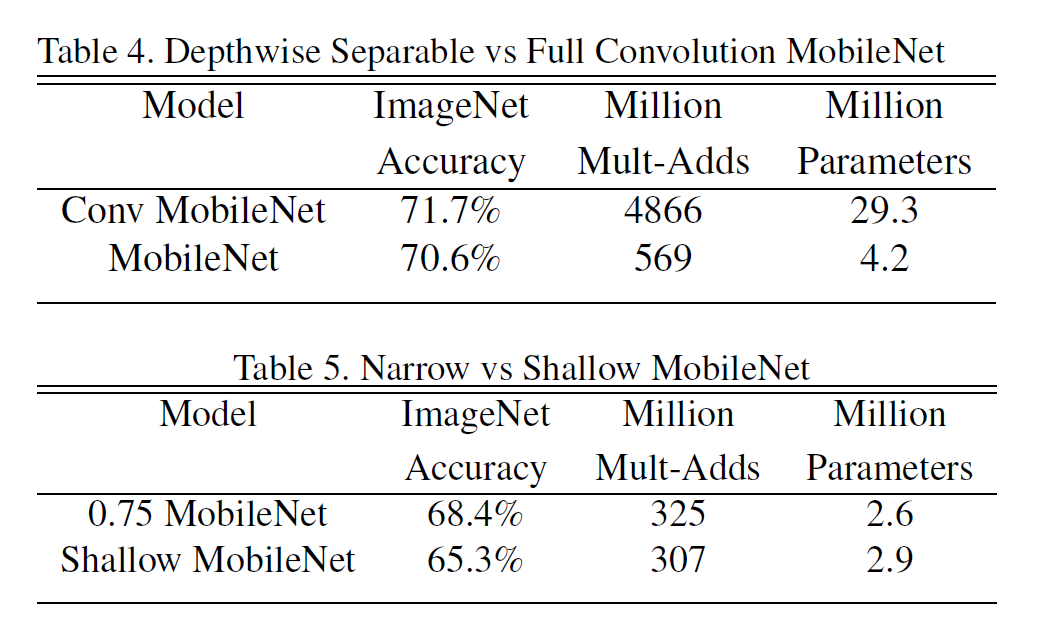
Full Conv와 DS Conv의 차이는 명확하다. 정확도는 1% 낮지만, 모델 크기는 7배 이상 작다. 또한, Narrow와 Shallow와 비교한 것도 있다.

모델이 작을수록 성능도 떨어진다.

계산량과 성능 상의 trade-off는 위와 같다. 계산량이 지수적으로 늘어나면, 정확도는 거의 선형적으로 늘어난다.


다른 모델 (GoogleNet, VGG16 등)과 비교했을 때, MobileNet은 성능은 비슷하면서 계산량과 모델 크기에서 확실한 우위를 점한다.

대량의 noisy한 데이터를 사용하여 학습한 다음 Stanford Dogs dataset에서 테스한 결과이다.
Conclusion
Depthwise Separable Convolutions을 사용한 경량화된 모델인 MobileNet은 모델 크기나 연산량에 비해 성능은 크게 떨어지지 않고, 시스템의 환경에 따라 적절한 크기의 모델을 선택할 수 있도록 하는 여러 옵션 (multiplier)를 제공하였다.
'Visual Intelligence > Image Classification' 카테고리의 다른 글
| [Image Classification] MobileNet V2 (0) | 2022.09.23 |
|---|---|
| [Image Classification] EfficientNet (cats-and-dogs) (0) | 2022.09.14 |
| [Image Classification] EfficientNet (0) | 2022.09.14 |
| [Image Classification] DenseNet (MNIST) (0) | 2022.09.14 |
| [Image Classification] DenseNet (0) | 2022.09.13 |



