728x90
반응형
SMALL
Chest X-Ray Images (Pneumonia)

정상 흉부 X-선 (왼쪽 패널)은 이미지에서 비정상적인 혼탁 영역이 없는 깨끗한 폐를 나타낸다. 세균성 폐렴 (가운데)은 일반적으로 이 경우 우상엽 (흰색 화살표)에서 국소 대엽 경화 (lobar lobar consolidation)를 나타내는 반면, 바이러스성 폐렴 (오른쪽)은 양쪽 폐에서 더 확산된 '간질' 패턴으로 나타난다.
데이터 세트는 3개의 폴더 (train, test, val)로 구성되며 각 이미지 범주 (Pneumonia/Normal)에 대한 하위 폴더를 포함한다. 5,863개의 X-Ray 이미지 (JPEG)와 2개의 카테고리 (폐렴/정상)가 있다.
흉부 X선 영상 (전후부)은 광저우에 있는 광저우 여성 아동 의료 센터에서 1세에서 5세 사이의 소아 환자의 후향적 코호트에서 선택되었다. 모든 흉부 X선 영상은 환자의 일상적인 임상 치료의 일부로 수행되었다.
캐글에서 파일을 받아 구글 드라이브에 업로드하고 마운트를 한다.
import os
import glob
import math
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Dropout, Dense, GlobalAveragePooling2D
from tensorflow.keras.applications import MobileNet
from tensorflow.keras.models import Model,Sequential
from tensorflow.keras.preprocessing.image import ImageDataGenerator
ROOT_DIR = '/content'
DATA_ROOT_DIR = os.path.join(ROOT_DIR, 'chest_xray')
TRAIN_DATA_ROOT_DIR = os.path.join(DATA_ROOT_DIR, 'train')
VALIDATION_DATA_ROOT_DIR = os.path.join(DATA_ROOT_DIR, 'val')
TEST_DATA_ROOT_DIR = os.path.join(DATA_ROOT_DIR, 'test')from google.colab import drive
drive.mount('/content/gdrive/')import shutil
try:
dataset_path = '/content/gdrive/My Drive/Colab Notebooks/dataset'
shutil.copy(os.path.join(dataset_path, 'chest-xray-pneumonia.zip'), '/content')
except Exception as err:
print(str(err))if os.path.exists(DATA_ROOT_DIR):
shutil.rmtree(DATA_ROOT_DIR)
print(DATA_ROOT_DIR + ' is removed.')# 압축파일 풀기
import zipfile
with zipfile.ZipFile(os.path.join(ROOT_DIR, 'chest-xray-pneumonia.zip'), 'r') as target_file:
target_file.extractall(ROOT_DIR)
데이터 확인
# train 정답 및 전체 데이터 개수 확인
train_label_name_list = os.listdir(TRAIN_DATA_ROOT_DIR)
print(train_label_name_list)
for label_name in train_label_name_list:
print('train label : ', label_name,' => ', len(os.listdir(os.path.join(TRAIN_DATA_ROOT_DIR, label_name))))
print('='*35)
# test 정답 및 전체 데이터 개수 확인
test_label_name_list = os.listdir(TEST_DATA_ROOT_DIR)
print(test_label_name_list)
for label_name in test_label_name_list:
print('test label : ', label_name, ' => ', len(os.listdir(os.path.join(TEST_DATA_ROOT_DIR, label_name))))
print('='*35)
# validation 정답 및 전체 데이터 개수 확인
validation_label_name_list = os.listdir(VALIDATION_DATA_ROOT_DIR)
print(validation_label_name_list)
for label_name in validation_label_name_list:
print('test label : ', label_name, ' => ', len(os.listdir(os.path.join(VALIDATION_DATA_ROOT_DIR, label_name))))
print('='*35)['NORMAL', 'PNEUMONIA']
train label : NORMAL => 1341
train label : PNEUMONIA => 3875
===================================
['NORMAL', 'PNEUMONIA']
test label : NORMAL => 234
test label : PNEUMONIA => 390
===================================
['NORMAL', 'PNEUMONIA']
test label : NORMAL => 8
test label : PNEUMONIA => 8
===================================
데이터 전처리
IMG_WIDTH = 224
IMG_HEIGHT = 224
train_datagen = ImageDataGenerator(rescale=1./255, validation_split=0.2)
validation_datagen = ImageDataGenerator(rescale=1./255, validation_split=0.2)
test_datagen = ImageDataGenerator(rescale=1./255 )
train_generator = train_datagen.flow_from_directory(TRAIN_DATA_ROOT_DIR, batch_size=32,
color_mode='rgb', class_mode='sparse',
target_size=(IMG_WIDTH,IMG_HEIGHT),
subset='training')
validation_generator = validation_datagen.flow_from_directory(TRAIN_DATA_ROOT_DIR, batch_size=32,
color_mode='rgb', class_mode='sparse',
target_size=(IMG_WIDTH,IMG_HEIGHT),
subset='validation')
test_generator = test_datagen.flow_from_directory(TEST_DATA_ROOT_DIR, batch_size=32,
color_mode='rgb', class_mode='sparse',
target_size=(IMG_WIDTH,IMG_HEIGHT))Found 4173 images belonging to 2 classes.
Found 1043 images belonging to 2 classes.
Found 624 images belonging to 2 classes.print(train_generator.class_indices)
print(train_generator.num_classes){'NORMAL': 0, 'PNEUMONIA': 1}
2import matplotlib.pyplot as plt
IMG_NUMS = 16
image_data, image_label = train_generator.next()
data = image_data[:IMG_NUMS]
label = image_label[:IMG_NUMS]
class_dict = {0.0: 'NORMAL', 1.0: 'PNEUMONIA'}
plt.figure(figsize=(8,8))
for i in range(len(label)):
plt.subplot(4, 4, i+1)
plt.title(str(class_dict[label[i]]))
plt.xticks([]); plt.yticks([])
plt.imshow(data[i])
plt.show()
모델 생성
class_nums = train_generator.num_classes # 정답개수
pre_trained_model = MobileNet(weights='imagenet', include_top=False, input_shape=(IMG_WIDTH,IMG_HEIGHT,3))
model = Sequential()
model.add(pre_trained_model)
model.add(GlobalAveragePooling2D())
model.add(Dense(16,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(class_nums, activation='softmax'))
model.summary()17227776/17225924 [==============================] - 0s 0us/step
17235968/17225924 [==============================] - 0s 0us/step
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
mobilenet_1.00_224 (Functio (None, 7, 7, 1024) 3228864
nal)
global_average_pooling2d (G (None, 1024) 0
lobalAveragePooling2D)
dense (Dense) (None, 16) 16400
dropout (Dropout) (None, 16) 0
dense_1 (Dense) (None, 2) 34
=================================================================
Total params: 3,245,298
Trainable params: 3,223,410
Non-trainable params: 21,888
_________________________________________________________________from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
from datetime import datetime
model.compile(loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(2e-5), metrics=['acc'])
save_file_name = './Chest_Xray_Pneumonia_MobileNet_Colab.h5'
checkpoint = ModelCheckpoint(save_file_name, # file명을 지정
monitor='val_loss', # val_loss 값이 개선되었을때 호출
verbose=1, # 로그를 출력
save_best_only=True, # 가장 best 값만 저장
mode='auto' # auto는 알아서 best를 찾음. min/max
)
earlystopping = EarlyStopping(monitor='val_loss', # 모니터 기준 설정 (val loss)
patience=5, # 5회 Epoch동안 개선되지 않는다면 종료
verbose=1 # 로그를 출력
)
start_time = datetime.now()
hist = model.fit(train_generator, epochs=20, validation_data=validation_generator)
end_time = datetime.now()
print('Elapsed Time => ', end_time-start_time)plt.plot(hist.history['acc'], label='train')
plt.plot(hist.history['val_acc'], label='validation')
plt.title('Accuracy Trend')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(loc='best')
plt.grid()
plt.show()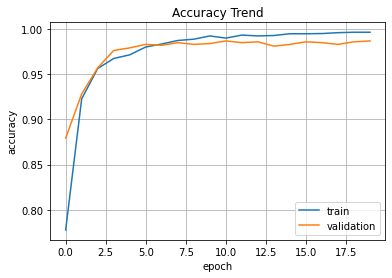
plt.plot(hist.history['loss'], label='train')
plt.plot(hist.history['val_loss'], label='validation')
plt.title('Loss Trend')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(loc='best')
plt.grid()
plt.show()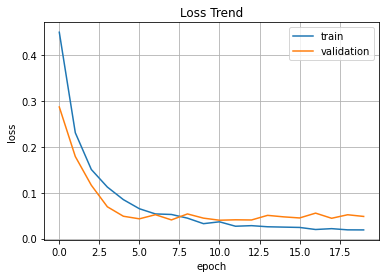
model.evaluate(test_generator)[1.2295359373092651, 0.8125]test_simple_datagen = ImageDataGenerator(rescale=1./255 )
test_simple_generator = test_datagen.flow_from_directory(VALIDATION_DATA_ROOT_DIR, batch_size=32,
color_mode='rgb', class_mode='sparse',
target_size=(IMG_WIDTH,IMG_HEIGHT))Found 16 images belonging to 2 classes.model.evaluate(test_simple_generator)[0.22053740918636322, 0.875]
homogeneous를 위한 data mix
test_label_name_list = os.listdir(TEST_DATA_ROOT_DIR)
print(test_label_name_list)
for label_name in test_label_name_list: # Testing 디렉토리 각각의 label에서 실행
test_path = os.path.join(TEST_DATA_ROOT_DIR, label_name)
test_file_list = os.listdir(test_path)
train_path = os.path.join(TRAIN_DATA_ROOT_DIR, label_name)
moved_num = 0
for test_image_file in test_file_list: # test 모든 data를 train 디렉토리로 이동
# already exists error 방지
# 참고소스: https://stackoverflow.com/questions/31813504
shutil.move(os.path.join(test_path, test_image_file),
os.path.join(train_path, test_image_file))
moved_num = moved_num + 1
print(str(moved_num) + ' is moved into ' + label_name + ' (test => train)')['NORMAL', 'PNEUMONIA']
234 is moved into NORMAL (test => train)
390 is moved into PNEUMONIA (test => train)validation_label_name_list = os.listdir(VALIDATION_DATA_ROOT_DIR)
print(validation_label_name_list)
for label_name in validation_label_name_list: # val 디렉토리 각각의 label에서 실행
validation_path = os.path.join(VALIDATION_DATA_ROOT_DIR, label_name)
validation_file_list = os.listdir(validation_path)
train_path = os.path.join(TRAIN_DATA_ROOT_DIR, label_name)
moved_num = 0
for validation_image_file in validation_file_list: # val 모든 data를 train 디렉토리로 이동
# already exists error 방지
# 참고소스: https://stackoverflow.com/questions/31813504
shutil.move(os.path.join(validation_path, validation_image_file),
os.path.join(train_path, validation_image_file))
moved_num = moved_num + 1
print(str(moved_num) + ' is moved into ' + label_name + ' (val => train)')['NORMAL', 'PNEUMONIA']
8 is moved into NORMAL (val => train)
8 is moved into PNEUMONIA (val => train)# 파일 move 비율
MOVE_RATIO = 0.2 # train : test = 80 : 20, 즉 train 데이터 20% 데이터를 test 데이터로 사용
# 파일 move train_data_dir => test_data_dir
label_name_list = os.listdir(TRAIN_DATA_ROOT_DIR)
for label_name in label_name_list:
# 파일 move 하기 위한 src_dir_path, dst_dir_path 설정
src_dir_path = os.path.join(TRAIN_DATA_ROOT_DIR,label_name)
dst_dir_path = os.path.join(TEST_DATA_ROOT_DIR,label_name)
train_data_file_list = os.listdir(src_dir_path)
print('========================================================================')
print('total [%s] data file nums => [%s]' % (label_name ,len(train_data_file_list)))
# data shuffle
random.shuffle(train_data_file_list)
print('train data shuffle is done !!!')
split_num = int(MOVE_RATIO*len(train_data_file_list))
print('split nums => ', split_num)
# extract test data from train data
test_data_file_list = train_data_file_list[0:split_num]
move_nums = 0
for test_data_file in test_data_file_list:
try:
shutil.move(os.path.join(src_dir_path, test_data_file),
os.path.join(dst_dir_path, test_data_file))
except Exception as err:
print(str(err))
move_nums = move_nums + 1
print('total move nums => ', move_nums)
print('========================================================================')========================================================================
total [NORMAL] data file nums => [1583]
train data shuffle is done !!!
split nums => 316
total move nums => 316
========================================================================
========================================================================
total [PNEUMONIA] data file nums => [4273]
train data shuffle is done !!!
split nums => 854
total move nums => 854
========================================================================# train 파일 개수 확인
label_name_list = os.listdir(TRAIN_DATA_ROOT_DIR)
print(label_name_list)
for label_name in label_name_list:
label_dir = os.path.join(TRAIN_DATA_ROOT_DIR, label_name)
print('train label : ' + label_name + ' => ', len(os.listdir(os.path.join(TRAIN_DATA_ROOT_DIR, label_name))))
print('=====================================================')
# test 파일 개수 확인
label_name_list = os.listdir(TEST_DATA_ROOT_DIR)
print(label_name_list)
for label_name in label_name_list:
label_dir = os.path.join(TEST_DATA_ROOT_DIR, label_name)
print('test label : ' + label_name + ' => ', len(os.listdir(os.path.join(TEST_DATA_ROOT_DIR, label_name))))
print('=====================================================')['NORMAL', 'PNEUMONIA']
train label : NORMAL => 1267
train label : PNEUMONIA => 3419
=====================================================
['NORMAL', 'PNEUMONIA']
test label : NORMAL => 316
test label : PNEUMONIA => 854
=====================================================IMG_WIDTH = 224
IMG_HEIGHT = 224
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255 )
train_generator = train_datagen.flow_from_directory(TRAIN_DATA_ROOT_DIR, batch_size=16,
color_mode='rgb', class_mode='sparse',
target_size=(IMG_WIDTH,IMG_HEIGHT))
test_generator = test_datagen.flow_from_directory(TEST_DATA_ROOT_DIR, batch_size=16,
color_mode='rgb', class_mode='sparse',
target_size=(IMG_WIDTH,IMG_HEIGHT))
print(train_generator.class_indices)
print(train_generator.num_classes)data, label = train_generator.next()
class_dict = {0.0: 'NORMAL', 1.0: 'PNEUMONIA'}
plt.figure(figsize=(8,8))
for i in range(len(label)):
plt.subplot(4, 4, i+1)
plt.title(str(class_dict[label[i]]))
plt.xticks([]); plt.yticks([])
plt.imshow(data[i])
plt.show()hist = model.fit(train_generator, epochs=20, validation_data=test_generator)
model.evaluate(test_generator)[0.11736276745796204, 0.976068377494812]728x90
반응형
LIST
'Visual Intelligence > Image Deep Learning' 카테고리의 다른 글
| [시각 지능] Coffee Classification (0) | 2022.08.28 |
|---|---|
| [시각 지능] COVID-19 Radiography (0) | 2022.08.27 |
| [시각 지능] Brain Tumor Classification (MRI) (1) | 2022.08.21 |
| [시각 지능] imgaug (0) | 2022.08.21 |
| [시각 지능] Image Data Augmentation + Transfer Learning (0) | 2022.08.20 |



