sklearn.ensemble.HistGradientBoostingClassifier
이 추정기는 큰 데이터 세트(n_samples >= 10,000)에서 GradientBoostingClassifier보다 훨씬 빠르다. 이 추정기는 누락된 값 (NaN)을 기본적으로 지원한다. 훈련하는 동안 나무 재배자는 누락된 값이 있는 샘플이 잠재적 이득에 따라 왼쪽 또는 오른쪽 자식으로 이동해야 하는지 여부를 각 분할 지점에서 학습한다. 예측할 때 누락된 값이 있는 샘플은 결과적으로 왼쪽 또는 오른쪽 자식에 할당된다. 교육 중에 지정된 기능에 대해 누락된 값이 없으면 누락된 값이 있는 샘플은 가장 많은 샘플이 있는 하위 항목에 매핑된다.
결측치 처리
import numpy as np
import pandas as pd
from time import perf_counter
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import (GradientBoostingClassifier,
HistGradientBoostingClassifier)
from sklearn.metrics import accuracy_score, roc_auc_score, f1_score
import matplotlib.pyplot as plt
import seaborn as sns
pd.options.display.max_columns = 6
sns.set(style='darkgrid', context='talk', palette='rainbow')
n = 10 ** 4
X, y = make_classification(n, random_state=42)
X = pd.DataFrame(X, columns=[f'feature{i}' for i in range(X.shape[1])])
# Randomly add missing data for all columns
for i, col in enumerate(X.columns):
np.random.seed(i)
X.loc[np.random.choice(range(n), 1000, replace=False), col] = np.nan
print(f"Target shape: {y.shape}")
print(f"Features shape: {X.shape}")
X.head()
GBM으로 학습시킬 경우 다음과 같다.
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
print("========== Training data ========== ")
print(f"Features: {X_train.shape} | Target:{y_train.shape}")
print("========== Test data ========== ")
print(f"Features: {X_test.shape} | Target:{y_test.shape}")
gbm = GradientBoostingClassifier(random_state=42)
gbm.fit(X_train, y_train)
gbm.score(X_test, y_test)
대부분의 Scikit-learn 추정치와 마찬가지로 결측값이 있는 데이터에 모형을 맞추려고 하면 ValueError가 트리거된다. 입력에 NaN, 무한대 또는 dtype('float32')에 대해 너무 큰 값이 포함되어 있다.
hgbm = HistGradientBoostingClassifier(random_state=42)
hgbm.fit(X_train, y_train)
hgbm.score(X_test, y_test)0.9248
놀랍게도 HGBM 추정기는 누락된 데이터를 기본적으로 처리할 수 있기 때문에 완벽하게 작동한다. 이는 HGBM이 GBM에 비해 제공하는 이점 중 하나이다.
더 큰 데이터로 원활하게 스케일링
HGBM은 구현 속도가 빠른 GBM이며 대규모 데이터셋과 함께 원활하게 확장된다. 두 추정치가 서로 다른 크기의 표본 데이터와 어떻게 비교되는지 살펴본다.
n_samples = 10**np.arange(2,7)
tuples = [*zip(np.repeat(n_samples,2), np.tile(['gbm', 'hgbm'], 2))]
summary = pd.DataFrame(
index=pd.MultiIndex.from_tuples(tuples,
names=["n_records", "model"])
)
models = [('gbm', GradientBoostingClassifier(random_state=42)),
('hgbm', HistGradientBoostingClassifier(random_state=42))]
for n in n_samples:
X, y = make_classification(n, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(
X, y, random_state=42
)
for name, model in models:
start = perf_counter()
model.fit(X_train, y_train)
end = perf_counter()
summary.loc[(n, name), 'fit_time'] = end - start
start = perf_counter()
y_proba = model.predict_proba(X_test)[:,1]
end = perf_counter()
summary.loc[(n, name), 'score_time'] = end - start
summary.loc[(n, name), 'roc_auc'] = roc_auc_score(y_test, y_proba)
y_pred = np.round(y_proba)
summary.loc[(n, name), 'accuracy'] = accuracy_score(y_test, y_pred)
summary.loc[(n, name), 'f1'] = f1_score(y_test, y_pred)
summary
HGBM을 사용하면 교육 데이터가 증가함에 따라 교육 시간이 훨씬 빨라지는 것을 알 수 있다. 데이터가 클수록 HGBM의 속도는 더 인상적이다. HGBM은 데이터를 bins 기능으로 조잡하게 만들어 놀라운 속도를 달성한다.
fig, ax = plt.subplots(2, 1, figsize=(9,6), sharex=True)
sns.lineplot(data=summary['fit_time'].reset_index(),
x='n_records', y='fit_time', hue='model', ax=ax[0])
ax[0].legend(loc='upper right', bbox_to_anchor=(1.3, 1))
sns.lineplot(data=summary['score_time'].reset_index(),
x='n_records', y='score_time', hue='model',
legend=False, ax=ax[1])
ax[1].set_xscale('log')
fig.tight_layout();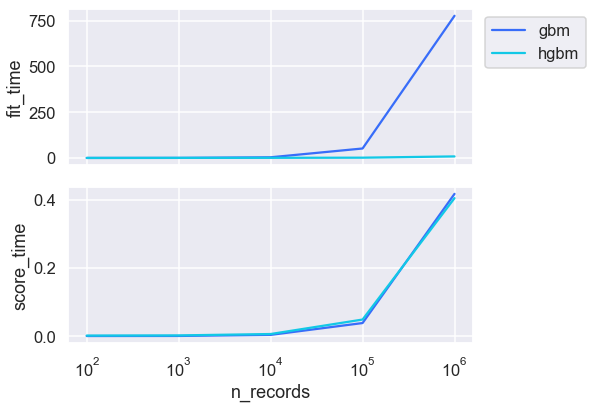
학습 시간은 GBM의 경우 훈련 예제의 수가 증가함에 따라 크게 증가하는 반면 대규모 데이터 세트의 경우 HGBM의 경우 여전히 상대적으로 빠르다. 득점 시간은 둘 사이에 꽤 가깝다.
fig, ax = plt.subplots(3, 1, figsize=(9,9), sharex=True)
sns.lineplot(data=summary['roc_auc'].reset_index(),
x='n_records', y='roc_auc', hue='model', ax=ax[0])
ax[0].legend(loc='upper right', bbox_to_anchor=(1.3, 1))
sns.lineplot(data=summary['accuracy'].reset_index(),
x='n_records', y='accuracy', hue='model',
legend=False, ax=ax[1])
sns.lineplot(data=summary['f1'].reset_index(),
x='n_records', y='f1', hue='model',
legend=False, ax=ax[2])
ax[2].set_xscale('log')
fig.tight_layout();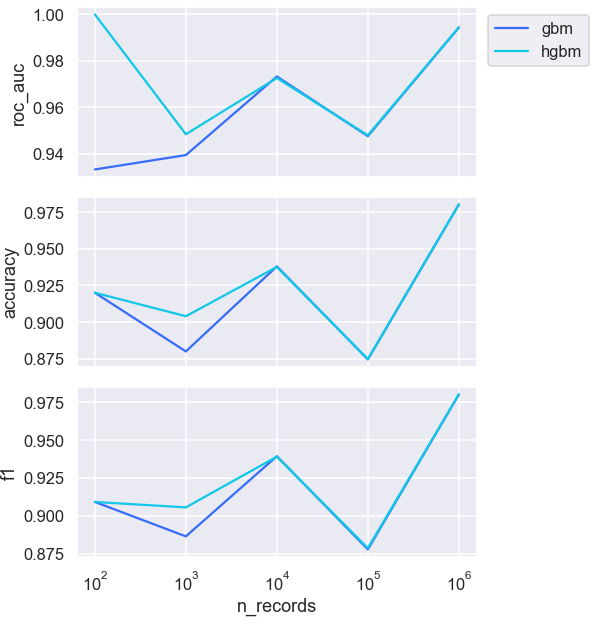
전체적으로 예측 성능은 훈련 데이터가 75와 750으로 작을 때 약간의 차이가 있지만 둘 사이에 상당히 유사하다. HGBM의 두 번째 이점은 GBM에 비해 대규모 데이터셋에서 매우 잘 확장된다는 것이다.
https://towardsdatascience.com/meet-histgradientboostingclassifier-54a9df60d066
Meet HistGradientBoostingClassifier
A more flexible and scalable GradientBoostingClassifier
towardsdatascience.com
'Python Library > Scikit-Learn' 카테고리의 다른 글
| [Scikit-Learn] train_test_split 모듈을 활용하여 학습과 테스트 세트 분리 (0) | 2021.12.20 |
|---|---|
| 사이킷런 (Scikit-Learn) (0) | 2021.12.20 |

