Train / Validation / Test set
ML 모델링을 하고자 할 때 데이터 set을 나누어 사용한다.
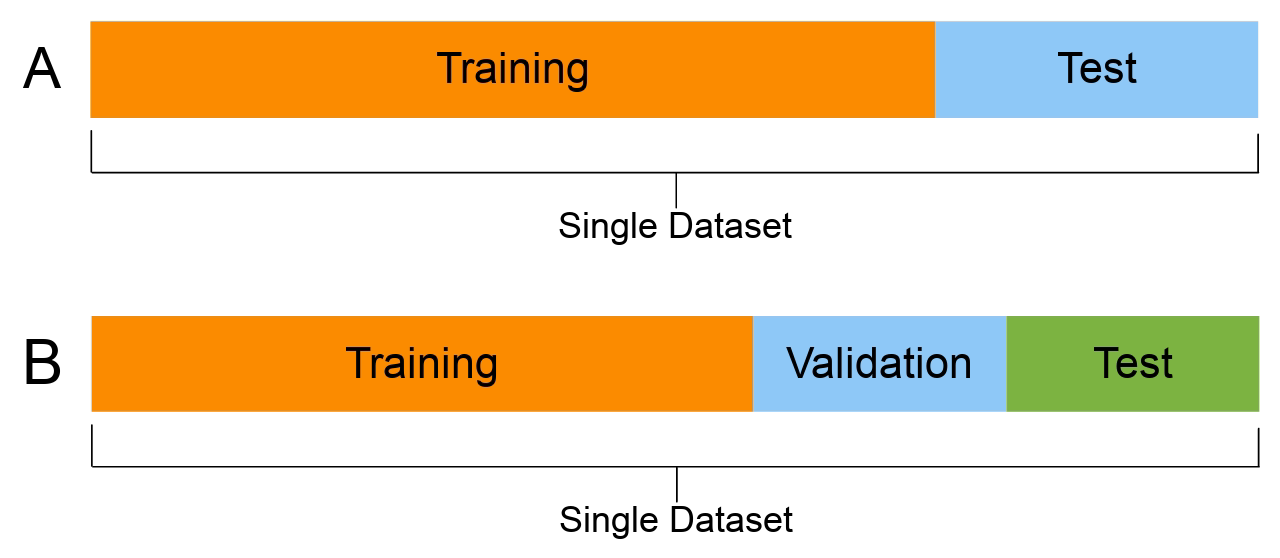
일반적으로 train : validation : test = 60 : 20 : 20 의 비율을 사용한다.
훈련 데이터 (train set)
train set은 모델을 학습하는데 사용된다. train set으로 모델을 만든 뒤 동일한 데이터로 성능을 평가해보기도 하지만, 이는 cheating이 되기 때문에 유효한 평가는 아니다. train set은 test set이 아닌 나머지 데이터 set을 의미하기도 하며, train set 내에서 또 다시 쪼갠 validation set이 아닌 나머지 데이터 set을 의미하기도 한다. 따라서 test set과 구분하기 위해 사용되는지, validation set과 구분하기 위해 사용되는지를 확인해야 한다.
검정 데이터 (validation set)
validation set은 train set으로 만들어진 모델의 성능을 측정하기 위해 사용된다. 일반적으로 어떤 모델이 가장 데이터에 적합한지 찾아내기 위해서 다양한 parameter와 모델을 사용해보게 되며, 그 중 validation set으로 가장 성능이 좋은 모델을 선택한다. 모델을 update, 즉 train을 시키진 않지만 train에 관여는 한다. 적당한 epoch을 찾고 그 epoch까지 학습시키기 위해 사용되는 것이다.
테스트 데이터 (test set)
test set은 validation set으로 사용할 모델이 결정 된 후, 마지막으로 딱 한 번 해당 모델의 예상되는 최종 성능을 측정하기 위해 사용된다. 이미 validation set은 여러 모델에 반복적으로 사용되었고 그 중 운 좋게 성능이 보다 더 뛰어난 것으로 측정되어 모델이 선택되었을 수도 있기 때문에 이러한 오차를 줄이기 위해 한 번도 사용해본 적 없는 test set을 사용하여 최종 모델의 성능을 측정하게 된다.
⚠️ validation set은 여러 모델들 각각에 적용되어 성능을 측정하며, 최종 모델을 선정하기 위해 사용된다. 반면 test set은 최종 모델에 대해 단 한번 성능을 측정하며, 앞으로 기대되는 성능을 예측하기 위해 사용된다. 만약 여러 모델을 성능 평가하여 그 중에서 가장 좋은 모델을 선택하고 싶지 않은 경우에는 validation set을 만들지 않아도 된다. 하지만 이 경우에는 test accuracy를 예측할 수도 없고, 모델 튜닝을 통해 overfitting을 방지할 수도 없는 문제가 발생할 것이다.
그러면 모델의 성능 평가를 왜 하는 것인가?
첫 번째는 test accuracy를 가늠해볼 수 있다는 것이다. ML의 목적은 결국 unseen data 즉, test data에 대해 좋은 성능을 내는 것이다. 그러므로 모델을 만든 후 이 모델이 unseen data에 대해 얼마나 잘 동작할지에 대해서 반드시 확인이 필요하다. 하지만 train data를 사용해 성능을 평가하면 안되기 때문에 따로 validation set을 만들어 정확도를 측정하는 것이다. 두 번째는 모델을 튜닝하여 모델의 성능을 높일 수 있다. 예를 들어 overfitting을 막기 위해 어떠한 모델이 train accuracy는 높은데 validation accuracy는 낮다면 데이터가 training set에 overfitting이 일어났을 가능성을 생각해볼 수 있다. 그렇다면 overfitting을 막아서 training accuracy를 낮추더라도 validation accuracy와 train accuracy를 비슷하게 맞춰줄 필요가 있다. 예를 들어, DL 모델을 구축하기 위해 regularization을 한다거나 epoch을 줄이는 등의 방식으로 overfitting을 막을 수 있다.
example code
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, shuffle=True, stratify=None, random_state=1)
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size=0.25, random_state=1, shuffle=False)
'Learning-driven Methodology > DL (Deep Learning)' 카테고리의 다른 글
| [Deep Learning] 비용 함수 (Cost Function) (0) | 2021.12.30 |
|---|---|
| [Deep Learning] 목적 함수 (Objective Function) (0) | 2021.12.30 |
| [Deep Learning] 회귀 (Regression) (0) | 2021.12.23 |
| 딥러닝 (Deep Learning) (0) | 2021.12.23 |
| [Deep Learning] 경사 하강법 (Gradient Descent) / 배치 사이즈 (Batch Size) / 에포크 (Epoch) (0) | 2021.12.22 |



