비용 함수 (Cost Function)
가설이 얼마나 정확한지 판단하는 기준을 말하며, loss function의 합, 평균 에러를 다룬다. 여기서 single data set이 아니라 entire data set을 다룬다. 순간마다의 loss를 판단할 땐 loss function을 사용하고 학습이 완료된 후에는 cost function을 확인한다.
제곱합 (Sum of squared)


제곱합은 신경망 연구 초기부터 사용된 cost function으로 델타 규칙을 이용해 오차를 구하고 weight를 조정한다.
교차 엔트로피 (Cross Entropy)

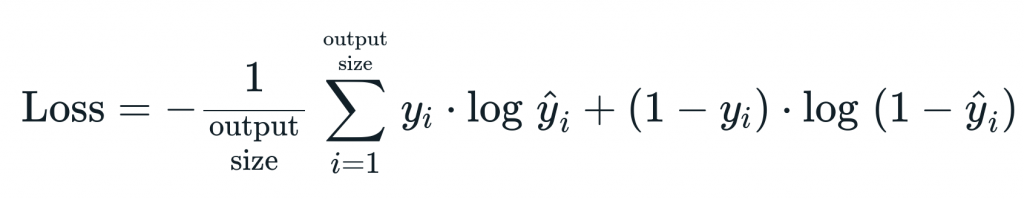
교차 엔트로피는 다중 클래스 분류 (multi class classification) 신경망에서 많이 사용된다. 출력 (y)의 범위는 0 < y < 1이다. cross entropy cost function는 activation function으로 sigmoid 함수나 softmax 함수로 설정한 신경망과 함께 많이 사용된다.
Cross Entropy 역전파 알고리즘
출력 node의 activation function이 sigmoid 함수일 경우에 cross entropy 함수로부터 유도된 역전파 알고리즘으로 다층 신경망을 학습시킨다.
정칙화 (Regularization)
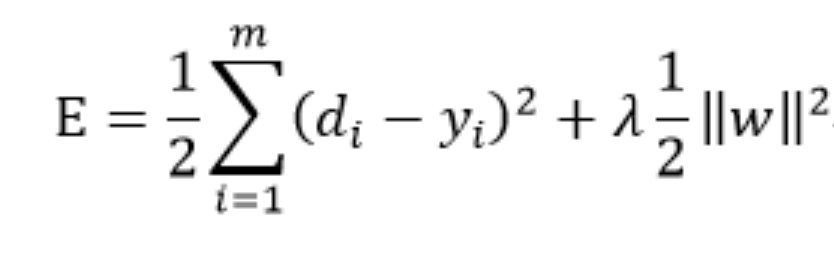

regularization은 overfitting을 예방하려는 방법이다. 이는 모델을 최대한 단순하게 만드는 것이다. regularization은 cost function에 weight의 크기를 모두 더한 것이다.
코사인 유사도 (Cosine Similarity)

코사인 유사도는 두 벡터가 가리키는 방향이 얼마나 비슷한가를 나타낸다. 두 벡터의 방향이 완전히 같다면 유사도는 1이되고, 완번히 반대면 -1이 된다.
cost function은 더 일반적인 함수이다. 어떤 모델의 페널티의 복잡성을 줄이는 것 (regularization)과 train set에 전반적인 loss function의 총합이 될 수도 있다. 예측값과 실제값의 차이가 줄어들수록 더 우리는 많은 값들을 예측할 가능성이 늘어난다. cost function은 그 차이를 나타내므로 cost function이 줄어들수록 더 정확한 예측이 가능하다.
underfitting은 트레이닝이 부족할 때 나타난다. underfitting은 high bias, high variance의 결과를 가져오는 경우가 많다. low bias, high variance인 overfitting이 되어도 문제인데, train set에만 맞는 값들이 예측되어 bias는 낮지만 실제 미래에 있을 값들이나 새로운 값들에는 맞지 않을 수 있기 때문에 주의해야한다. 따라서 low bias, low variance인 cost function을 찾는 것이 중요하다. 에러함수에서 fit이 너무 되면 추가적으로 페널티를 줘서 overfitting도 막아주고 하는 함수를 튜닝하는 것으로 생각하면 될 것이다.
'Learning-driven Methodology > DL (Deep Learning)' 카테고리의 다른 글
| [Deep Learning] 활성화 함수 (Activation Function) (1) (0) | 2022.01.03 |
|---|---|
| [Deep Learning] 손실 함수 (Loss function) (0) | 2022.01.03 |
| [Deep Learning] 목적 함수 (Objective Function) (0) | 2021.12.30 |
| [Deep Learning] 회귀 (Regression) (0) | 2021.12.23 |
| 딥러닝 (Deep Learning) (0) | 2021.12.23 |



