What is TensorFlow lite (TFLite)?
배터리와 메모리는 모바일, edge 또는 IoT 장치에 가장 중요한 두 가지 리소스이다. 클라우드나 사내 서버에 비해 제한된 양으로 제공된다. 딥러닝 (DL) 기반 훈련된 모델을 직접 배포하면 리소스가 부족하기 때문에 작동하지 않는다. 따라서, 이러한 장치에 대한 DL 모델 기반 추론은 모델의 다음 특성을 고려해야 한다. (i) 메모리를 절약하려면 크기가 더 작아야 한다. (ii) 배터리 수명을 절약하기 위해 적은 에너지를 소비해야 하고 (iii) 사용자가 모델이 즉시 반응한다고 느낄 수 있도록 낮은 대기 시간 또는 높은 추론 시간을 가져야 한다. 요컨대, 모바일 및 에지 장치에 배포하기 위해 메모리, 에너지 및 프로세서 사용량에 대해 모델을 효율적으로 만드는 것이 중요하다. TensorFlow Lite (기기 내 추론을 위한 오픈 소스 DL 프레임워크)와 양자화는 주요 최적화 방법이다. 양자화는 모델 크기를 줄이는 데 도움이 되며 모델이 장치에서 실행될 수 있도록 호환됩니다.
모델의 모든 기준을 충족하기 위해 Google은 TensorFlow-lite (TFLite)라는 기기 내 추론 엔진을 제공한다. TFLite는 특히 모바일, edge 또는 IoT 장치를 대상으로 하여 속도, 모델 크기 및 전력 소비를 최적화한다. 또한, GPU 대리자를 통한 GPU 기반 모델 추론을 지원한다. 이러한 대리자는 API를 통해 GPU 가속을 위한 기본 라이브러리와 통신할 수 있다. 예를 들어, Android 장치의 경우 GPU 대리자는 Android Neural Network API를 사용하고 iOS 장치의 경우 하드웨어 가속 추론 작업에 Metal API를 사용한다. 그림은 TFLite의 내부 아키텍처를 보여준다. TFLite는 두 가지 주요 구성 요소로 구성된다.
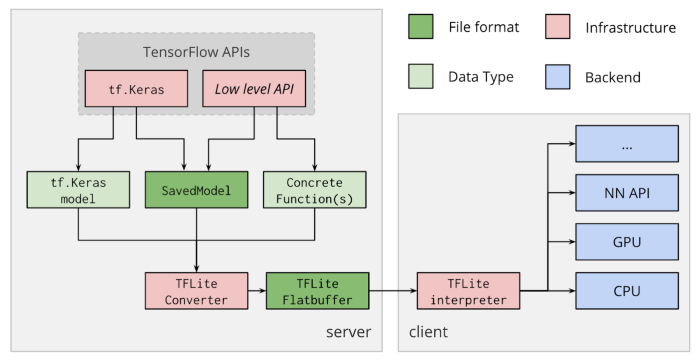
|
What is model quantization and why do we need it?
TFLite가 사용하는 가장 유용한 최적화 중 하나는 양자화이다. 양자화는 주어진 실수 값에 대해 상위 비트보다 하위 비트 표현을 사용한다. 예를 들어, 32비트 (또는 4바이트) 부동 소수점 숫자와 같은 연속 실수를 8비트 (또는 1바이트) 정수와 같은 이산 숫자로 나타낼 수 있다. 딥러닝에서 가중치와 편향 (또는 단순히 신경망의 매개변수)은 32비트 부동 소수점 숫자로 저장되므로 모델 교육 중에 고정밀 계산이 발생할 수 있다. 그리고 모델이 훈련될 때 8비트 정수로 축소될 수 있으며 이는 결국 모델 크기의 축소를 의미한다. 16비트 부동 소수점 (크기 2배 감소) 또는 8비트 정수 (크기 4배 감소)로 줄일 수 있다. 물론, 이것은 모델 예측의 정확성에 대한 절충과 함께 올 수 있다. 그러나, 그것은 양자화된 모델은 특히 16비트 부동 소수점을 사용하여 모델의 크기를 절반으로 줄이는 경우 상당한 감쇠를 겪지 않거나 전혀 감쇠하지 않음을 많은 상황에서 경험적으로 보여준다. 마찬가지로 활성화 값을 양자화할 수도 있지만 대표적인 데이터 세트에서 일부 스케일링 매개변수를 결정하려면 보정 단계가 필요하다. 이것은 "전체 양자화" 하위 섹션에 자세히 설명되어 있다. 그림은 각각 모델 크기, 대기 시간 및 정확도에 대한 전체 양자화 (8비트 INT에 대한 가중치 및 활성화 값)의 영향과 관련된 몇 가지 예를 보여준다. 그들은 실험을 위해 Google Android Pixel 2를 사용했다.
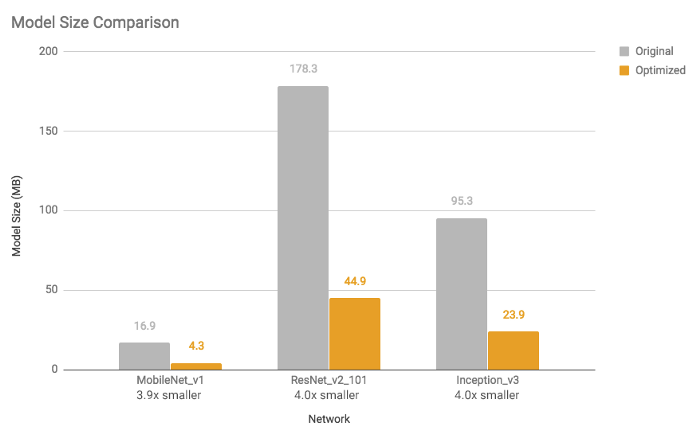
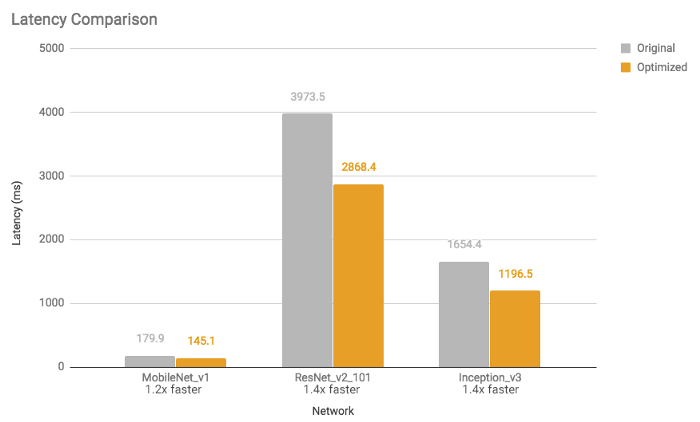
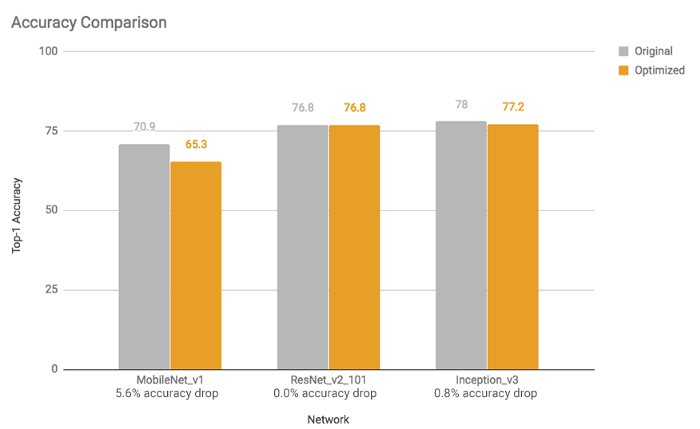
https://medium.com/sclable/model-quantization-using-tensorflow-lite-2fe6a171a90d
Model Quantization Using Tensorflow Lite
Deployment of deep learning models on mobile devices
medium.com
'DNN with Keras > TensorFlow' 카테고리의 다른 글
| [TensorFlow] The kernel appears to have died. It will restart automatically. (0) | 2022.08.29 |
|---|---|
| TensorFlow Lite (2) (0) | 2022.08.23 |
| [TensorFlow] 텐서 작업 (0) | 2022.06.20 |
| [TensorFlow] Pandas 데이터 프레임 전처리 (0) | 2022.06.16 |
| [TensorFlow] NumPy 전처리 (0) | 2022.06.16 |



