728x90
반응형
SMALL
CountVectorizer를 이용한 토큰화
import sklearn
print(sklearn.__version__)from sklearn.feature_extraction.text import CountVectorizer
vector = CountVectorizer()
text = ['Text mining, also referred to as text data mining, similar to text analytics, is the process of deriving high-quality information from text.']
vector.fit_transform(text).toarray()array([[1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 4, 1, 2]],
dtype=int64)# 단어별 인덱스 확인
print(vector.vocabulary_)
print(vector.fit_transform(text).toarray()){'text': 15, 'mining': 9, 'also': 0, 'referred': 13, 'to': 17, 'as': 2, 'data': 3, 'similar': 14, 'analytics': 1, 'is': 8, 'the': 16, 'process': 11, 'of': 10, 'deriving': 4, 'high': 6, 'quality': 12, 'information': 7, 'from': 5}
[[1 1 1 1 1 1 1 1 1 2 1 1 1 1 1 4 1 2]]# CountVectorizer에서 제공하는 불용어 리스트 사용
vector1 = CountVectorizer(stop_words = "english")
print(vector1.fit_transform(text).toarray())
print(vector1.vocabulary_)[[1 1 1 1 1 2 1 1 1 1 4]]
{'text': 10, 'mining': 5, 'referred': 8, 'data': 1, 'similar': 9, 'analytics': 0, 'process': 6, 'deriving': 2, 'high': 3, 'quality': 7, 'information': 4}
DTM and TF-IDF
import pandas as pd
from math import log
docs = ['We love horror films','We also like romance films','But my favorite genre is musical','So we want to watch West Side Story']
vocab = list(set(w for doc in docs for w in doc.split()))
vocab.sort()
print(vocab)['But', 'Side', 'So', 'Story', 'We', 'West', 'also', 'favorite', 'films', 'genre', 'horror', 'is', 'like', 'love', 'musical', 'my', 'romance', 'to', 'want', 'watch', 'we']N = len(docs)
# 특정 문서 d에서 특정 단어 w가 등장하는 횟수
def tf(w, d):
return d.count(w)
# df: 특정단어 w가 등장하는 문서의 수
# idf: df(w)에 반비례하는 수
def idf(w):
df = 0
for doc in docs:
# +=: 왼쪽 변수에 오른쪽 값을 더한 후, 결과를 왼쪽 변수에 저장
df += w in doc
return log(N/(df+1))
# 최종적으로 구하려는 TF-IDF 함수
def tfidf(w, d):
return tf(w, d) * idf(w)# DTM
result = []
# 각 문서 하나하나를 호출한 후 단어별로 카운트
for i in range(N):
result.append([])
d = docs[i]
for j in range(len(vocab)):
w = vocab[j]
result[-1].append(tf(w, d))
tf_ = pd.DataFrame(result, columns = vocab)
tf_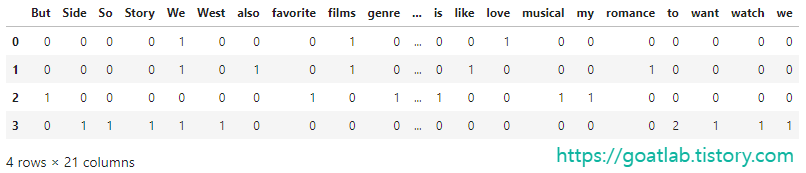
# calculating IDF values
result = []
for j in range(len(vocab)):
result.append([])
t = vocab[j]
result[-1].append(idf(t))
idf_ = pd.DataFrame(result, index = vocab, columns = ["IDF"])
idf_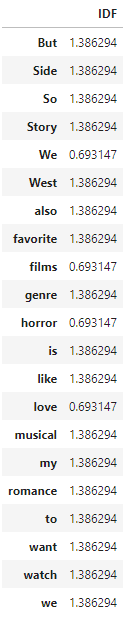
# TF-IDF matrix
result = []
for i in range(N):
result.append([])
d = docs[i]
for j in range(len(vocab)):
w = vocab[j]
result[-1].append(tfidf(w, d))
tfidf_ = pd.DataFrame(result, columns = vocab)
tfidf_
from sklearn.feature_extraction.text import CountVectorizer
vector = CountVectorizer()
print(vector.fit_transform(docs).toarray())
print(vector.vocabulary_)[[0 0 0 1 0 1 0 0 1 0 0 0 0 0 0 0 0 0 1 0]
[1 0 0 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 1 0]
[0 1 1 0 1 0 1 0 0 1 1 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1]]
{'we': 18, 'love': 8, 'horror': 5, 'films': 3, 'also': 0, 'like': 7, 'romance': 11, 'but': 1, 'my': 10, 'favorite': 2, 'genre': 4, 'is': 6, 'musical': 9, 'so': 13, 'want': 16, 'to': 15, 'watch': 17, 'west': 19, 'side': 12, 'story': 14}from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer().fit(docs)
print(tfidf.vocabulary_)
print(tfidf.transform(docs).toarray()){'we': 18, 'love': 8, 'horror': 5, 'films': 3, 'also': 0, 'like': 7, 'romance': 11, 'but': 1, 'my': 10, 'favorite': 2, 'genre': 4, 'is': 6, 'musical': 9, 'so': 13, 'want': 16, 'to': 15, 'watch': 17, 'west': 19, 'side': 12, 'story': 14}
[[0. 0. 0. 0.4530051 0. 0.57457953
0. 0. 0.57457953 0. 0. 0.
0. 0. 0. 0. 0. 0.
0.36674667 0. ]
[0.49819711 0. 0. 0.39278432 0. 0.
0. 0.49819711 0. 0. 0. 0.49819711
0. 0. 0. 0. 0. 0.
0.31799276 0. ]
[0. 0.40824829 0.40824829 0. 0.40824829 0.
0.40824829 0. 0. 0.40824829 0.40824829 0.
0. 0. 0. 0. 0. 0.
0. 0. ]
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0.36742339 0.36742339 0.36742339 0.36742339 0.36742339 0.36742339from afinn import Afinn
afn = Afinn()
text = 'I love horror films.'
afn.score(text)3.0text = 'I like horror films.'
afn.score(text)2.0afn = Afinn(emoticons = True)
text = 'I love horror films. :('
afn.score(text)1.0afn.score(':(')-2.0from textblob import TextBlob
# polarity: from -1 (negative) to 1 (positive)
# subjectivity: from 0 (very objective) to 1 (very subjective)
TextBlob("I love horror films").sentimentSentiment(polarity=0.5, subjectivity=0.6)TextBlob("I like horror films").sentimentSentiment(polarity=0.0, subjectivity=0.0)TextBlob("So I want to watch West Side Story").sentimentSentiment(polarity=0.0, subjectivity=0.0)728x90
반응형
LIST
'Data-driven Methodology > DS (Data Science)' 카테고리의 다른 글
| [Data Science] Bokeh를 활용한 대화형 웹 시각화 (0) | 2022.10.26 |
|---|---|
| [Data Science] 시계열 데이터 (Time Series Data) (0) | 2022.10.11 |
| [Data Science] Text Preprocessing (0) | 2022.09.29 |
| [Data Science] Text Data (2) (0) | 2022.09.29 |
| [Data Science] Text Data (1) (0) | 2022.09.29 |



