728x90
반응형
SMALL
결측치
결측치 (Missing Value)는 말 그대로 데이터에 값이 없는 것을 뜻한다. 줄여서 'NA'라고 표현하기도 하고, 다른 언어에서는 Null 이란 표현을 많이 쓴다. 결측치는 데이터를 분석하는데에 있어서 매우 방해가 되는 존재이다. 결측치의 특성이 '무작위로 손실' 되지 않았다면, 대부분의 경우 가장 좋은 방법은 제거하는 것이다. 제거하는 방식은 목록 삭제 (Listwist) 단일값 삭제 (Pairwise) 방식으로 다시 구분된다. pandas에서 제공하는 Na/NaN과 같은 누락 데이터를 제거하는 함수가 있다.
df.isnull()
null_count = df.isnull().sum()상가업소번호 0
상호명 0
지점명 105507
상권업종대분류코드 0
상권업종대분류명 0
상권업종중분류코드 0
상권업종중분류명 0
상권업종소분류코드 0
상권업종소분류명 0
표준산업분류코드 7179
표준산업분류명 7179
시도코드 0
시도명 0
시군구코드 0
시군구명 0
행정동코드 0
행정동명 0
법정동코드 0
법정동명 0
지번코드 0
대지구분코드 0
대지구분명 0
지번본번지 0
지번부번지 26633
지번주소 1
도로명코드 1
도로명 1
건물본번지 1
건물부번지 116007
건물관리번호 1
건물명 69019
도로명주소 1
구우편번호 1
신우편번호 18
동정보 122835
층정보 52231
호정보 132673
경도 1
위도 1
dtype: int64null_count.plot()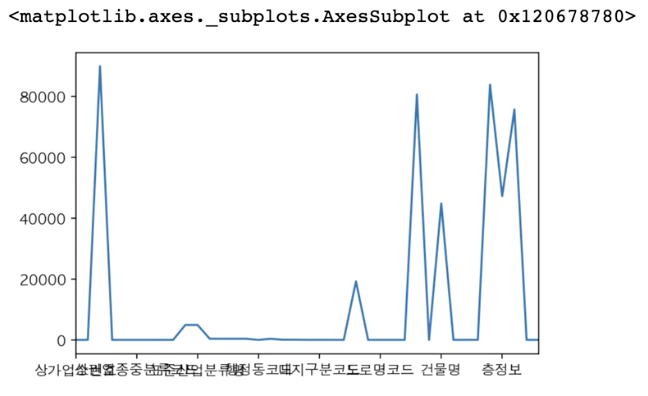
null_count.plot.bar()
# rot를 옵션으로 글자 60도 회전
null_count.plot.bar(rot=60)
# barh() 세로 막대형 그래프
null_count.plot.barh(figsize=(5,7))
컬럼명 변경
df_null_count = null_count.reset_index()
df_null_count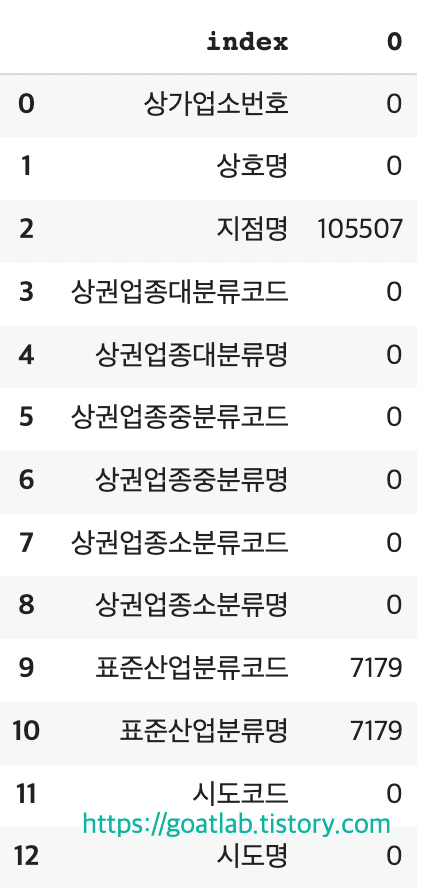
df_null_count.columnsIndex(['index', 0], dtype='object')df_null_count.columns = ["컬럼명", "결측치 수"]
df_null_count
df_null_count.head()
df_null_count.sort_values(by = "결측치 수")
df_null_count.sort_values(by = "결측치 수", ascending = False)
# 결측치가 많은 상위 10개
df_null_count_top = df_null_count.sort_values(by = "결측치 수", ascending = False).head(10)
특정 컬럼만 불러 오기
NaN은 Not a Number의 약자로 결측치로 보면 된다.
df["지점명"]0 NaN
1 NaN
2 NaN
3 NaN
4 NaN
...
132668 NaN
132669 NaN
132670 관악장군점
132671 NaN
132672 NaN
Name: 지점명, Length: 132673, dtype: objectdf_null_count["컬럼명"]0 상가업소번호
1 상호명
2 지점명
3 상권업종대분류코드
4 상권업종대분류명
5 상권업종중분류코드
6 상권업종중분류명
7 상권업종소분류코드
8 상권업종소분류명
9 표준산업분류코드
10 표준산업분류명
11 시도코드
12 시도명
13 시군구코드
14 시군구명
15 행정동코드
16 행정동명
17 법정동코드
18 법정동명
19 지번코드
20 대지구분코드
21 대지구분명
22 지번본번지
23 지번부번지
24 지번주소
25 도로명코드
26 도로명
27 건물본번지
28 건물부번지
29 건물관리번호
30 건물명
31 도로명주소
32 구우편번호
33 신우편번호
34 동정보
35 층정보
36 호정보
37 경도
38 위도
Name: 컬럼명, dtype: objectdrop_columns = df_null_count_top["컬럼명"].tolist()['호정보',
'동정보',
'건물부번지',
'지점명',
'건물명',
'층정보',
'지번부번지',
'표준산업분류명',
'표준산업분류코드',
'신우편번호']
컬럼 제거하기
df[drop_columns].head()
열을 기준으로 삭제해야 하기 때문에 axis = 1을 지정한다. 행을 삭제하려면 0을 넣어야 한다.
print(df.shape)
df = df.drop(drop_columns, axis = 1)
print(df.shape)(132673, 39)
(132673, 39)df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 132673 entries, 0 to 132672
Data columns (total 29 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 상가업소번호 132673 non-null int64
1 상호명 132673 non-null object
2 상권업종대분류코드 132673 non-null object
3 상권업종대분류명 132673 non-null object
4 상권업종중분류코드 132673 non-null object
5 상권업종중분류명 132673 non-null object
6 상권업종소분류코드 132673 non-null object
7 상권업종소분류명 132673 non-null object
8 시도코드 132673 non-null int64
9 시도명 132673 non-null object
10 시군구코드 132673 non-null int64
11 시군구명 132673 non-null object
12 행정동코드 132673 non-null int64
13 행정동명 132673 non-null object
14 법정동코드 132673 non-null int64
15 법정동명 132673 non-null object
16 지번코드 132673 non-null int64
17 대지구분코드 132673 non-null int64
18 대지구분명 132673 non-null object
19 지번본번지 132673 non-null int64
20 지번주소 132672 non-null object
21 도로명코드 132672 non-null float64
22 도로명 132672 non-null object
23 건물본번지 132672 non-null float64
24 건물관리번호 132672 non-null object
25 도로명주소 132672 non-null object
26 구우편번호 132672 non-null float64
27 경도 132672 non-null float64
28 위도 132672 non-null float64
dtypes: float64(5), int64(8), object(16)
memory usage: 29.4+ MB
drop을 한 후, 39개 였던 열이 29개가 되었고, 메모리도 29MB로 줄어들었다.
728x90
반응형
LIST
'Data-driven Methodology > DS (Data Science)' 카테고리의 다른 글
| [Data Science] 공공포털 데이터 (4) (0) | 2022.09.21 |
|---|---|
| [Data Science] 공공포털 데이터 (3) (0) | 2022.09.21 |
| [Data Science] 공공포털 데이터 (1) (0) | 2022.09.18 |
| [Data Science] Pandas Cheat Sheet (2) (0) | 2022.09.18 |
| [Data Science] Pandas Cheat Sheet (1) (0) | 2022.09.18 |



