728x90
반응형
SMALL
와인 종류 : red, white 두가지 타입으로 예측
winequality-white.csv
0.25MB
winequality-red.csv
0.08MB
import pandas as pd
# 데이터 로드
# 원본 파일은 분리자가 세미콜론
red_df = pd.read_csv('./winequality-red.csv', sep=';')
white_df = pd.read_csv('./winequality-white.csv', sep=';')
# 분리자를 콤마로 사본 저장 (일반적으로 csv 파일은 세미콜론이 아닌 콤마로 분리자를 사용)
red_df.to_csv('./winequality-red2.csv', index=False)
white_df.to_csv('./winequality-white2.csv', index=False)
red_df = pd.read_csv('./winequality-red2.csv')
white_df = pd.read_csv('./winequality-white2.csv')
# red wine 표준화 시행
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
red_scaled_np = scaler.fit_transform(red_df)
# scale 리턴값은 numpy 이므로 다시 DataFrame 생성
red_scaled_df = pd.DataFrame(red_scaled_np, columns=red_df.columns)
red_scaled_df.describe()
# white wine 표준화 시행
white_scaled_np = scaler.fit_transform(white_df)
# scale 리턴값은 numpy 이므로 다시 DataFrame 생성
white_scaled_df = pd.DataFrame(white_scaled_np, columns=white_df.columns)
white_scaled_df.describe()# 구분을 위해 type 열 추가
print('before => ',red_scaled_df.shape, white_scaled_df.shape)
red_scaled_df['type'] = 'red'
white_scaled_df['type'] = 'white'
print('after => ',red_scaled_df.shape, white_scaled_df.shape)
white_scaled_df.head()
red_scaled_df.head()# pd.concat() 이용해서 하나로 합치기
wine_scaled_df = pd.concat([red_scaled_df, white_scaled_df],axis=0)
wine_scaled_df.shape
wine_scaled_df['type']
wine_scaled_df.info()
wine_scaled_df.describe()wine_scaled_df.isnull().sum()
wine_scaled_df['type'].unique()
wine_scaled_df['type'].value_counts()
wine_scaled_df['type'].isna()
# type 항목의 'red' = 0, white = 1로 변경
wine_scaled_df['type'] = wine_scaled_df['type'].replace('red', 0)
wine_scaled_df['type'] = wine_scaled_df['type'].replace('white', 1)
wine_scaled_df.head()
# 입력 데이터
feature_col = wine_scaled_df.columns.difference(['type'])
# 정답 데이터
label_col = wine_scaled_df['type']
wine_feature_df = wine_scaled_df[feature_col]
wine_label_df = label_col
wine_feature_df.head()
wine_label_df.head()
import numpy as np
wine_feature_np = wine_feature_df.to_numpy().astype('float32')
wine_label_np = wine_label_df.to_numpy().astype('float32')
print(wine_feature_np.shape, wine_label_np.shape)
# shuffle
s = np.arange(len(wine_feature_np))
np.random.shuffle(s)
wine_feature_np = wine_feature_np[s]
wine_label_np = wine_label_np[s]
print(wine_feature_np.shape, wine_label_np.shape)
# 85% : 15% 비율로 train / test data 분리
split_ratio = 0.15
test_num = int(split_ratio*len(wine_feature_np))
x_test = wine_feature_np[:test_num]
y_test = wine_label_np[:test_num]
x_train = wine_feature_np[test_num:]
y_train = wine_label_np[test_num:]import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as plt
model = Sequential()
model.add(Dense(128, activation='relu', input_shape=(x_train.shape[1],)))
model.add(Dense(1, activation='sigmoid')) # type
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 128) 1664
dense_1 (Dense) (None, 1) 129
=================================================================
Total params: 1,793
Trainable params: 1,793
Non-trainable params: 0
_________________________________________________________________model.compile(optimizer=tf.keras.optimizers.Adam(),
loss='binary_crossentropy', metrics=['accuracy'] )
from datetime import datetime
start_time = datetime.now()
hist = model.fit(x_train, y_train,
epochs=200, batch_size=32,
validation_data=(x_test, y_test))
end_time = datetime.now()
print('elapsed time => ', end_time-start_time)pred = model.predict(x_test[-5:])
print(pred.flatten())
print(y_test[-5:])[0.4170394 0.99991196 1. 0.4412927 0.98263514]
[1. 1. 1. 0. 0.]model.evaluate(x_test, y_test)31/31 [==============================] - 0s 3ms/step - loss: 0.1381 - accuracy: 0.9630
[0.13809409737586975, 0.9630390405654907]plt.plot(hist.history['loss'], label='train')
plt.plot(hist.history['val_loss'], label='validation')
plt.title('loss trend')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(loc='best')
plt.grid()
plt.show()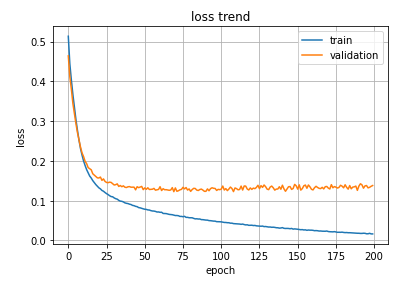
plt.plot(hist.history['accuracy'], label='train')
plt.plot(hist.history['val_accuracy'], label='validation')
plt.title('accuracy trend')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(loc='best')
plt.grid()
plt.show()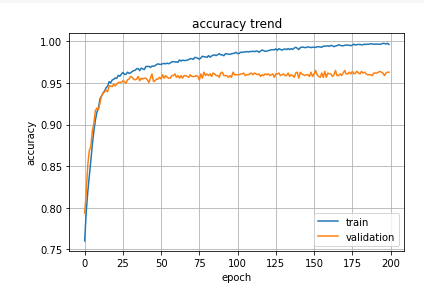
728x90
반응형
LIST
'AI-driven Methodology > Artificial Intelligence' 카테고리의 다른 글
| [AI] 정확도 (Accuracy) / 손실 (Loss) (0) | 2022.08.18 |
|---|---|
| [AI] 콜백 (Callback) (0) | 2022.07.31 |
| [AI] 와인 품질 예측 (0) | 2022.07.24 |
| [AI] 표준화 (Standardization) (0) | 2022.07.24 |
| [AI] 분류 (Classification) (0) | 2022.07.23 |



