의학에서 신경망 응용 (Neural network applications in medicine)
알츠하이머병, 파킨슨병, 자폐 스펙트럼 장애, 주의력 결핍 과잉행동장애 등의 신경계 질환은 중추신경계의 손상과 퇴화로 인해 발생하는 질환이다. 질병의 초기 단계에서는 다양한 치료를 통해 증상을 중화시킬 수 있지만 데이터의 이질성과 다양한 인적 입력으로 인해 초기 단계의 정확한 진단이 어렵다. 이러한 경우 인공 신경망 (ANN)을 적용하여 조기에 보다 정확한 진단을 제공하여 보다 우수하고 효과적인 치료를 제공할 수 있다. ANN은 데이터 볼륨과 다양성이 뛰어난 이종 데이터 세트의 바이오마커를 추출하는 데 더 나은 성능을 발휘하는 것으로 입증되었다. 따라서, 보다 정확한 검출을 위해서는 자동 검출 방법을 사용하는 것이 매우 중요하며, 분류 및 예측 접근 방식이 필요하다.
인공 신경망 (ANN)
인공 신경망 (ANN)은 인간 두뇌의 생리학적 능력을 모방한 고도로 계산된 세포의 네트워크이다. 이러한 세포는 층으로 발생하며 종종 노드라고 한다. 뇌의 주요 기능은 신호의 형태로 정보를 신체에 보내는 것이다. 결과적으로 뇌는 적응하고, 새로운 것을 배우고, 불완전하고 불분명한 정보를 분석하고, 적절한 판단을 내릴 수 있다. 손글씨가 우리와 같지 않거나 공과 사과를 구별하는 인간 두뇌의 능력이 같지 않아도 다른 사람이 쓴 글자와 단어를 읽을 수 있다는 간단한 비유이다. 인간의 두뇌는 지능, 패턴 및 물체 인식과 관련된 수많은 작업을 수행할 수 있다. 이러한 작업은 자동화하기가 매우 어려워 보이지만 ANN을 사용하여 수행할 수 있다. 이러한 이유로 유사한 작업을 수행하는 모든 컴퓨팅 시스템은 인간의 두뇌가 작동하는 방식과 프로세스를 모방하는 방법을 이해함으로써 큰 이점을 얻을 수 있다. 이를 위해서는 신경망에 대한 연구가 필요하다. 인간의 중추 신경계에는 축색 돌기, 세포체 및 수상 돌기의 세 가지 주요 기능 부분을 가진 수십억 개의 뉴런이 있다. 축삭은 한 뉴런에서 다른 뉴런으로 신호를 전달하고, 세포체 (체체)는 세포를 지지하는 핵을 포함하는 반면 수상돌기는 뉴런에서 신호를 받아 세포체로 전달한다. 따라서 뉴런은 수상돌기를 통해 다른 뉴런으로부터 신호를 받습니다. 뉴런은 서로를 만지지 않으며 근육, 조직 또는 수상돌기를 만지지도 않는다 (전기 시냅스의 경우 제외). 오히려 그들은 접점에서 상호 작용한다. 이것은 일반적으로 시냅스라고 하는 간격이다. 틈에는 뉴런에서 뉴런, 근육 및 조직으로 충동을 전달하는 화학 물질이 포함되어 있다. 이러한 화학 물질을 신경 전달 물질이라고 합니다. 인간의 뇌에 존재하는 가장 중요한 신경 전달 물질에는 글루타메이트, 아스파테이트, 감마-아미노부티르산, 아세틸콜린, 도파민 및 세로토닌이 포함되며, 이는 또한 많은 신경 질환에 관여한다.
인공 신경망은 복잡한 세계 문제와 관련하여 학습, 적응 및 탁월한 판단을 내리는 인간 두뇌의 탁월한 능력에서 영감을 받았다. 최초의 인공 뉴런은 1943년 신경 생리학자이자 수학자 McCulloch와 Pitts에 의해 제안되었다. 컴퓨팅 모델이 유한 수와 시냅스 가중치 조정을 사용하여 계산 가능한 기능을 수행할 수 있음이 입증되었다. 그 이후로 ANN은 의학을 비롯한 여러 분야에서 인정을 받았으며 실제 문제를 해결할 수 있는 능력을 보여주었다. 인공 신경망에서 뉴런은 뇌의 생물학적 신경망과 동일한 방식으로 연결된다. 데이터는 다음 계층의 뉴런으로 전송된 결과로 수학적으로 처리된다.
인공 신경망 아키텍처
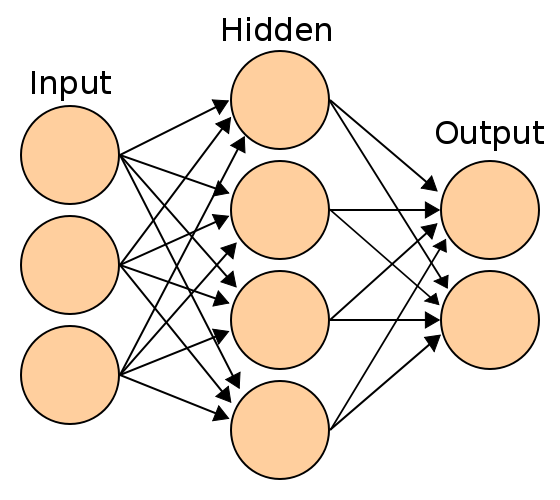
ANN 아키텍처는 입력 계층, 은닉 계층 및 출력 계층을 포함한다. 입력 레이어는 원시 입력 데이터/값을 받는다. 이 값은 출력 계층으로 더 전송되기 전에 은닉 계층으로 전송된다. 은닉층은 단일 또는 다중일 수 있다. ANN에서 교육은 지도 및 비지도 학습의 두 가지 주요 학습 방법을 기반으로 한다.
지도 학습 방법은 입력 데이터 (훈련 세트)와 목표 데이터 간의 연결을 찾으려는 시도이다. 간단히 말해서, 컴퓨터 프로그램 (학습자)에게 먼저 훈련 데이터를 제공하고 이어서 데이터를 테스트하는 예를 통해 학습하는 것이다. 레이블이 지정된 훈련 데이터를 컴퓨터 프로그램에 제공함으로써 레이블 없이 제공될 때 데이터를 분류하거나 회귀하고 동일한 데이터 클래스를 식별하는 모델을 개발할 것이다. 지도 학습에서는 정확성이 매우 중요하다. 결과적으로 컴퓨터 프로그램은 다양한 정도의 모양, 들여쓰기 및 차이가 있는 동일한 클래스의 이미지에 대한 많은 양의 데이터로 훈련하는 것이 좋다. 이렇게 하면 동일한 이미지가 들여쓰기되거나 구부러져도 컴퓨터가 이미지를 식별할 수 있다. 이것에 대한 간단한 비유는 학습자에게 각 이미지의 과일 이름이 주어지는 다양한 과일 이미지 세트 (ex: 캐슈, 사과, 오렌지, 딸기)가 있는 컴퓨터 프로그램을 제공하는 것이다. 그 후 학습자는 초기에 제공된 동일한 클래스의 레이블이 지정되지 않은 과일 이미지 세트를 제공받고 각 과일을 높은 정확도로 식별하기 위해 테스트한다.
비지도 학습 방법은 단순히 학습이 교사 없이 관찰에 의해 수행되는 것이다. 비지도 학습에서는 훈련 세트에 레이블이 포함되지 않는다. 컴퓨터 프로그램은 입력을 받지만 감독 대상 출력이나 환경의 영향을 얻지 못한다. 미래의 입력과 의사 결정을 예측하는 데 사용할 수 있는 입력의 표현을 구축하여 이를 수행한다. 비지도 학습의 성공 여부는 네트워크가 관련 비용 함수를 줄이거나 늘릴 수 있는지 여부에 따라 결정된다.
'Biomedical & AI > Neural network applications in medicine' 카테고리의 다른 글
| 자폐 스펙트럼 장애 (0) | 2022.06.03 |
|---|---|
| 주의 결핍 과잉 행동 장애 (0) | 2022.06.03 |
| 파킨슨병 (0) | 2022.06.03 |
| 신경 및 신경 정신 질환에 대한 응용 (알츠하이머병) (0) | 2022.06.02 |



