ResNet

Residual Network (ResNet) 은 마이크로소프트의 Kaiming He에 의해 개발되었고, 2015년 ISVRC에서 우승하였다.
MNIST와 같은 데이터셋에서는 얕은 층의 CNN으로도 높은 분류 성능을 얻을 수 있다. 하지만, CIFAR나 ImageNet과 같이 좀 더 복잡하고 도전적인 데이터셋에서 얕은 네트워크로는 한계가 있어 연구자들은 점점 더 깊은 층을 가진 CNN을 만드려는 노력을 했다.
딥러닝에서 neural networks가 깊어질수록 성능은 더 좋지만 train이 어렵다는 것은 알려진 사실이다. 그래서 잔차를 이용한 잔차 학습 (residual learning framework)를 이용해서 깊은 신경망에서도 training이 쉽게 이뤄질 수 있다는 것을 보 이고 방법론을 제시한다.
결과적으로 152개의 layer를 쌓아서 기존의 VGGNet보다 좋은 성능을 내면서 복잡성은 줄였다. 3.57%의 error를 달성해서 ILSVRC 2015에서 1등을 차지했으며, CIFAR-10 데이터를 사용하여 100개에서 1000개의 레이어를 구성하여 테스트했다.
ResNet에서 참조한 많은 논문들로 인해 deep model일수록 성능이 좋다는 것은 알려져 있다. 깊어지는 layer와 함께 떠오르는 의문은 "과연 더 많은 레이어를 쌓는 것만큼 신경망을 학습시키는 것이 쉬운가" 이다. 이 질문에 답하는 데 있어 장애물은 처음부터 수렴을 방해 는 그레이디언트 소실/발산이라는 문제였다. 그러나 이 문제는 정규화된 초기화와 중간 정규화 계층으로 대부분 해결되었으며, 이는 수십 개의 계층을 가진 네트워크가 역전파와 함께 확률적 경사하강 (SGD)을 위한 수렴을 시작할 수 있게 한다.
층을 쌓을 때마다 각 레이어에 weight와 bias의 파라미터를 갖는데, 신경망을 학습시킨다는 것은 이 파라미터를 SGD (stochastic gradient descent)로 업데이트 한다는 것을 의미한다. 여기서, 기울기를 통해 weight를 업데이트 할 때, 기울기 소실/발산으로 인해 안정적이지 않은 문제가 있다. 기울기가 안정적이지 않은 이유는 신경망에서 사용하는 activation function과 연관성이 있다. 작은 값을 가지는 난수로 네트워크의 가중치를 초기화하면 모든 activation이 0이 되는 현상이 발생한다.
이렇게 모든 activation이 0이나 -1, 1로 포화되는 문제를 해결하기 위해 Xavier initialization과 같은 초기화 방법이나 batch normalization 등의 기법이 나왔다. 초기화와 정규화는 이와 같은 기울기 문제 점을 해결해 더 깊은 네트워크의 학습이 가능하게 했지만 이에 비례하여 train loss가 증가하는 문제가 생겼다.
Xavier Initialization
Xavier initialization은 각 layer의 활성화 값을 더 광범위하게 분포시킬 목적으로 weight의 적절한 분포를 가지는 tanh 또는 sigmoid에서 활성화되는 초기값을 위해 이 방법을 주로 사용한다. 이전 layer의 neuron의 개수가 n이라면 표준편차가 1/√n인 분포를 사용하는 개념이다. 너무 크지도 않고 작지도 않은 weight을 사용하여 gradient가 소실되거나 발산하는 문제를 막는다. Xavier Initialization을 사용하게 된다면, 뉴런의 개수가 많을수록 초기값으로 설정하는 weight이 더 좁게 퍼짐을 알 수 있다 (활성화 함수가 ReLU인 경우 비선형성이 발생해서 멈추게 된다. ReLU는 He Initialization 사용함).
네트워크가 깊어지면서 top-5 error가 낮아진 것을 확인할 수 있다. 한 마디로 성능이 좋아진 것이다. 그렇다면 "망을 깊게 하면 무조건 성능이 좋아질까?" 이것을 확인하기 위해 ResNet의 저자들은 컨볼루션 층들과 fully-connected층들로 20층의 네트워크와 56층의 네트워크를 각각 만들고 성능을 테스트 해보았다.

더 깊은 구조를 갖는 56층의 네트워크가 20층의 네트 워크보다 더 나쁜 성능을 보임을 알 수 있다. 기존의 방식으로는 망을 무조건 깊게 한다고 능사가 아니라는 것을 확인한 것이다. 따라서, 새로운 방법이 있어야 망을 깊게 만드는 효과를 볼 수 있다는 것을 알게 되었다.
Residual Block
새로운 방법은 ResNet의 핵심인 Residual Block이다. 그림에서 오른쪽이 Residual Block을 나타낸다. 기존의 망과 차이가 있다면 입력값을 출력값에 더해줄 수 있도록 지름길 (shortcut)을 하나 만들어준 것 뿐이다.

기존의 신경망은 입력값 x를 타겟값 y로 매핑하는 함수 H(x)를 얻는 것이 목적이었다. 그러나 ResNet은 F(x) + x를 최소화하는 것을 학습 목표로 한다. x는 현시점에서 변할 수 없는 값이므로 F(x)를 0에 가깝게 만드는 것이 목적이 된다. F(x)가 0이 되면 출력과 입력이 모두 x로 같아지게 된다. F(x) = H(x) - x이므로 F(x)를 최소로 해준다는 것은 H(x) - x를 최소로 해주는 것과 동일한 의미를 지닌다. 여기서, H(x) - x를 잔차 (residual)라고 한다. 즉, 잔차를 최소로 해주는 것이므로 ResNet이란 이름이 붙게 된다.
기존의 신경망이 direct mapping을 학습했다면 Residual learning은 입력부터 얼마만큼 달라져야 하는지를 학습한다. H(x)가 학습해야 하는 mapping이라면 이를 H(x)=F(x)+x로 새롭게 정의한다. 이때, 레이어의 입력을 레이어의 출력에 바로 연결하는 “Skip Connection, Shortcut”을 사용하였다. 앞에 그림에서 이는 항등 함수 (identity) x로 표현되어 있다.
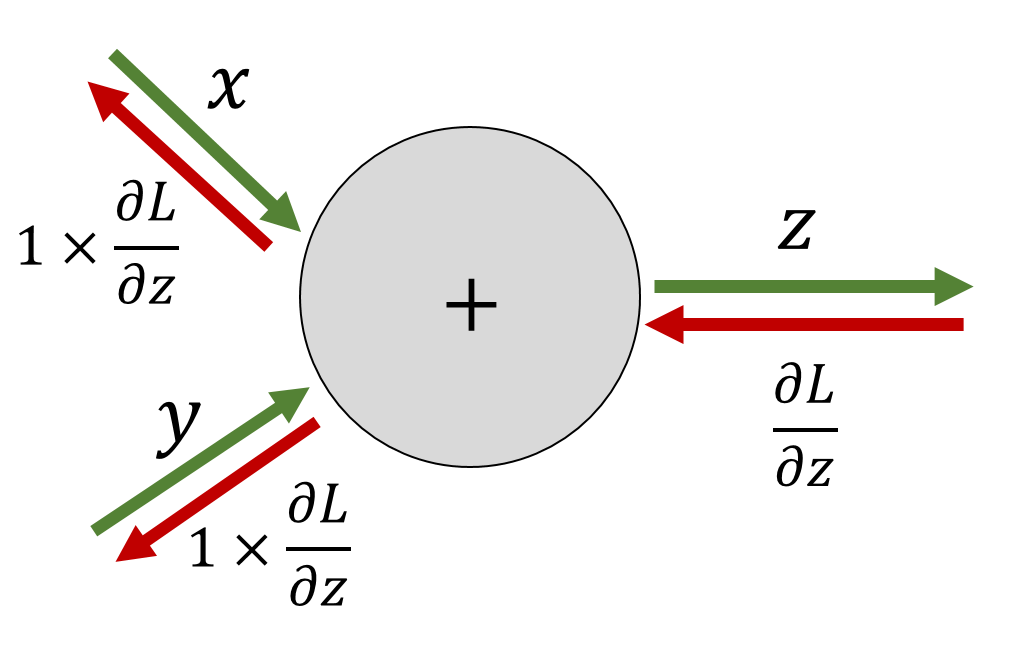
이 방법은 최적화가 비교적 쉽고, 단순한 지름길을 통해 x를 식에 추가하기만 하면 되기 때문에 기존 네트워크의 구조를 크게 변경하지 않고 학습을 진행할 수 있다. 또한, 매개변수의 수나 연산량의 증가도 없으며, 복잡도가 증가하지도 않는다. 그리고 신경망을 깊게 구성하더라도 기울기 소실 문제가 발생하지 않는다는 가장 큰 장점이 있다. 이는 전체 신경망에 걸쳐 가중치들을 최적화하는 것이 아니라, 짧은 레이어들로 이루어진 Residual Block마다 부분적인 학습이 진행되기 때문이다.
'Visual Intelligence > Image Classification' 카테고리의 다른 글
| [Image Classification] DenseNet (0) | 2022.09.13 |
|---|---|
| [Image Classification] ResNet (2) (0) | 2022.09.13 |
| [Image Classification] VGGNet (cats-and-dogs) (0) | 2022.09.06 |
| [Image Classification] VGGNet (0) | 2022.09.06 |
| [Image Classification] GoogleNet (0) | 2022.09.06 |



