728x90
반응형
SMALL
MNIST

MNIST 데이터베이스 는 손으로 쓴 숫자들로 이루어진 대형 데이터베이스이며, 다양한 화상 처리 시스템을 트레이닝하기 위해 일반적으로 사용된다. 이 데이터베이스는 또한 기계 학습 분야의 트레이닝 및 테스트에 널리 사용된다. NIST의 오리지널 데이터셋의 샘플을 재혼합하여 만들어졌다.
import tensorflow as tf
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
(x_train, t_train), (x_test, t_test) = mnist.load_data()
print('')
print('x_train.shape = ', x_train.shape, ', t_train.shape = ', t_train.shape)
print('x_test.shape = ', x_test.shape, ', t_test.shape = ', t_test.shape)Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
11493376/11490434 [==============================] - 0s 0us/step
11501568/11490434 [==============================] - 0s 0us/step
x_train.shape = (60000, 28, 28) , t_train.shape = (60000,)
x_test.shape = (10000, 28, 28) , t_test.shape = (10000,)
25개 이미지 출력
import matplotlib.pyplot as plt
plt.figure(figsize = (6, 6))
for index in range(25):
plt.subplot(5, 5, index + 1) # 5행 5열
plt.imshow(x_train[index], cmap = 'gray')
plt.axis('off')
plt.show()
plt.imshow(x_train[9], cmap = 'gray')
plt.colorbar()
plt.show()
데이터 전처리
# x_train, x_test 값 범위를 0 ~ 1로 초기화
x_train = x_train / 255.0
x_test = x_test / 255.0
print('train max = ', x_train[0].max(), ', train min = ', x_train[0].min())
print('text max = ', x_test[0].max(), ', test min = ', x_test[0].min())train max = 1.0 , train min = 0.0
text max = 1.0 , test min = 0.0# 정답 데이터 one-hot encoding
t_train = to_categorical(t_train, 10)
t_test = to_categorical(t_test, 10)
print('train label = ', t_train[0], ', decimal value = ', np.argmax(t_train[0]))
print('test label = ', t_test[0], ', decimal value = ', np.argmax(t_test[0]))train label = [0. 0. 0. 0. 0. 1. 0. 0. 0. 0.] , decimal value = 5
test label = [0. 0. 0. 0. 0. 0. 0. 1. 0. 0.] , decimal value = 7
모델 구축 및 컴파일
from tensorflow.keras.optimizers import SGD
model = Sequential()
model.add(Flatten(input_shape = (28, 28, 1)))
model.add(Dense(100, activation = 'relu'))
model.add(Dense(10, activation = 'softmax'))
model.compile(optimizer = SGD(),
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
dense (Dense) (None, 100) 78500
dense_1 (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________
모델 학습
hist = model.fit(x_train, t_train, epochs = 30, validation_split = 0.2)
모델 (정확도) 평가
model.evaluate(x_test, t_test)313/313 [==============================] - 1s 3ms/step - loss: 0.1099 - accuracy: 0.9688
[0.10988297313451767, 0.9688000082969666]
손실, 정확도
plt.title('Loss Trend')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.grid()
plt.plot(hist.history['loss'], label = 'training loss')
plt.plot(hist.history['val_loss'], label = 'validation loss')
plt.legend(loc = 'best')
plt.show()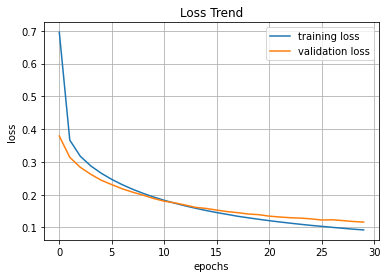
plt.title('Accuracy Trend')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.grid()
plt.plot(hist.history['loss'], label = 'training accuracy')
plt.plot(hist.history['val_loss'], label = 'validation accuracy')
plt.legend(loc = 'best')
plt.show()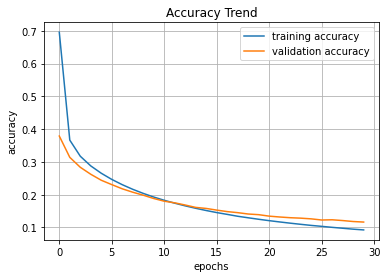
예측
pred = model.predict(x_test)
print(pred.shape) # 입력 : 10,000 / 출력 : 10
print(pred[:5])(10000, 10)
[[2.47125226e-05 9.41667935e-08 4.55119327e-04 9.51758772e-03
2.68577605e-08 1.28551646e-05 4.31200603e-10 9.89943504e-01
1.48223171e-05 3.13286109e-05]
[1.60143209e-05 3.11233511e-04 9.98242259e-01 7.63157965e-04
5.11713616e-10 1.65575620e-05 2.92068580e-04 7.99445440e-11
3.58617574e-04 9.49742174e-10]
[9.39205347e-05 9.84965324e-01 2.76321894e-03 9.09237191e-04
4.20741271e-04 3.95900395e-04 4.91019455e-04 6.11370383e-03
3.54454620e-03 3.02398985e-04]
[9.99855399e-01 1.17819205e-07 3.06073744e-05 1.49597452e-06
7.35541164e-07 2.91437154e-05 1.38678743e-05 4.04107523e-05
1.97497926e-07 2.80292970e-05]
[7.03856858e-05 1.86522607e-06 1.27948762e-04 6.76886975e-06
9.76610422e-01 6.29926399e-06 1.87695157e-04 7.62023556e-04
1.49609084e-04 2.20768899e-02]]728x90
반응형
LIST
'Visual Intelligence > Image Deep Learning' 카테고리의 다른 글
| [시각 지능] CNN (Convolutional Neural Network) (0) | 2022.08.06 |
|---|---|
| [시각 지능] 컨벌루션 (Convolution) (0) | 2022.07.31 |
| [시각 지능] Fashion MNIST (0) | 2022.07.31 |
| [시각 지능] 컴퓨터 비전 (Computer Vision) (0) | 2022.07.30 |
| 시각 지능 (Visual Intelligence) (0) | 2022.07.09 |



