728x90
반응형
SMALL
CNN 특징맵 ∙ 풀링맵 시각화
각 채널마다 어떻게 작동해서 특징맵이나 풀링맵이 생기는지 시각화한다.
import tensorflow as tf
from tensorflow.keras.layers import Flatten, Dense, Conv2D, MaxPooling2D, Dropout, Input
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.datasets import mnist
import numpy as np
from datetime import datetime
import matplotlib.pyplot as plt
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train / 255.0
x_test = x_test / 255.0
print('x_train.shape = ', x_train.shape, ' , x_test.shape = ', x_test.shape)
print('t_train.shape = ', y_train.shape, ' , t_test.shape = ', y_test.shape)x_train.shape = (60000, 28, 28) , x_test.shape = (10000, 28, 28)
t_train.shape = (60000,) , t_test.shape = (10000,)
sequential model
# sequential model construction
model = Sequential()
model.add(Conv2D(input_shape=(28,28,1), kernel_size=3, filters=32, strides=(1,1), activation='relu', padding='SAME'))
model.add(MaxPooling2D(pool_size=(2,2), padding='SAME'))
model.add(Dropout(0.25))
model.add(Conv2D(kernel_size=3, filters=64, strides=(1,1), activation='relu', padding='SAME'))
model.add(MaxPooling2D(pool_size=(2,2), padding='SAME'))
model.add(Dropout(0.25))
model.add(Conv2D(kernel_size=3, filters=128, strides=(1,1), activation='relu', padding='SAME'))
model.add(MaxPooling2D(pool_size=(2,2), padding='SAME'))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(10, activation='softmax'))
model.compile(optimizer=Adam(), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 28, 28, 32) 320
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 14, 14, 32) 0
_________________________________________________________________
dropout (Dropout) (None, 14, 14, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 14, 14, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 7, 7, 64) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 7, 7, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 7, 7, 128) 73856
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 4, 4, 128) 0
_________________________________________________________________
dropout_2 (Dropout) (None, 4, 4, 128) 0
_________________________________________________________________
flatten (Flatten) (None, 2048) 0
_________________________________________________________________
dense (Dense) (None, 10) 20490
...
Total params: 113,162
Trainable params: 113,162
Non-trainable params: 0
_________________________________________________________________
학습 전 특징맵 시각화
x_train = x_train.reshape(-1,28,28,1)
x_test = x_test.reshape(-1,28,28,1)
for layer in model.layers:
if 'conv' in layer.name:
print(layer.name, layer.output.shape)conv2d (None, 28, 28, 32)
conv2d_1 (None, 14, 14, 64)
conv2d_2 (None, 7, 7, 128)for idx in range(len(model.layers)):
print('model.layers[%d] = %s, %s' % (idx, model.layers[idx].name, model.layers[idx].output.shape))model.layers[0] = conv2d, (None, 28, 28, 32)
model.layers[1] = max_pooling2d, (None, 14, 14, 32)
model.layers[2] = dropout, (None, 14, 14, 32)
model.layers[3] = conv2d_1, (None, 14, 14, 64)
model.layers[4] = max_pooling2d_1, (None, 7, 7, 64)
model.layers[5] = dropout_1, (None, 7, 7, 64)
model.layers[6] = conv2d_2, (None, 7, 7, 128)
model.layers[7] = max_pooling2d_2, (None, 4, 4, 128)
model.layers[8] = dropout_2, (None, 4, 4, 128)
model.layers[9] = flatten, (None, 2048)
model.layers[10] = dense, (None, 10)# 첫번째 층, 즉 0 번째 층만 떼어냄
partial_model = Model(inputs=model.inputs, outputs=model.layers[0].output)
partial_model.summary()Model: "model_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_input (InputLayer) [(None, 28, 28, 1)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 28, 28, 32) 320
=================================================================
Total params: 320
Trainable params: 320
Non-trainable params: 0
_________________________________________________________________random_idx = np.random.randint(0, len(x_test))
print(random_idx)
plt.imshow(x_test[random_idx].reshape(28,28), cmap='gray')8856
<matplotlib.image.AxesImage at 0x7f395cff4490>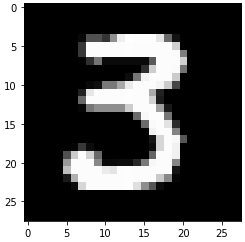
feature_map = partial_model.predict(x_test[random_idx].reshape(-1,28,28,1)) # 부분 모델로 테스트 집합을 예측
print(feature_map.shape)
fm = feature_map[0] # 0번 이미지의 특징 맵을 시각화
print(fm.shape)(1, 28, 28, 32)
(28, 28, 32)plt.figure(figsize=(10, 8))
for i in range(32): # i번째 특징 맵
plt.subplot(4,8,i+1)
plt.imshow(fm[:,:,i], cmap='gray')
plt.xticks([]); plt.yticks([])
plt.title("fmap"+str(i))
plt.tight_layout()
plt.show()
학습 전 풀링맵 시각화
# 첫번째 층, 즉 0 번째 층만 떼어냄
partial_model = Model(inputs=model.inputs, outputs=model.layers[1].output)
partial_model.summary()Model: "model_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_input (InputLayer) [(None, 28, 28, 1)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 28, 28, 32) 320
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 14, 14, 32) 0
=================================================================
Total params: 320
Trainable params: 320
Non-trainable params: 0
_________________________________________________________________pooling_map = partial_model.predict(x_test[random_idx].reshape(-1,28,28,1)) # 부분 모델로 테스트 집합을 예측
print(pooling_map.shape)
pm = pooling_map[0] # 0번 이미지의 풀링 맵을 시각화
print(pm.shape)(1, 14, 14, 32)
(14, 14, 32)plt.figure(figsize=(10, 8))
for i in range(32): # i번째 풀링 맵
plt.subplot(4,8,i+1)
plt.imshow(pm[:,:,i], cmap='gray')
plt.xticks([]); plt.yticks([])
plt.title("pmap"+str(i))
plt.tight_layout()
plt.show()
모델 학습
start_time = datetime.now()
hist = model.fit(x_train, y_train, batch_size=64, epochs=50, validation_data=(x_test, y_test))
end_time = datetime.now()
print('\n\nElapsed Time => ', end_time - start_time)model.evaluate(x_test, y_test)import matplotlib.pyplot as plt
plt.plot(hist.history['accuracy'])
plt.plot(hist.history['val_accuracy'])
plt.title('Accuracy Trend')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train','validation'], loc='best')
plt.grid()
plt.show()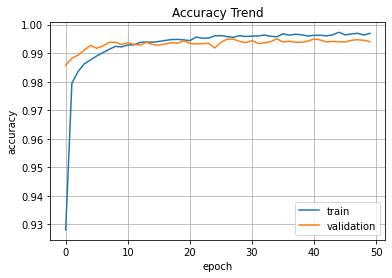
plt.plot(hist.history['loss'])
plt.plot(hist.history['val_loss'])
plt.title('Loss Trend')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train','validation'], loc='best')
plt.grid()
plt.show()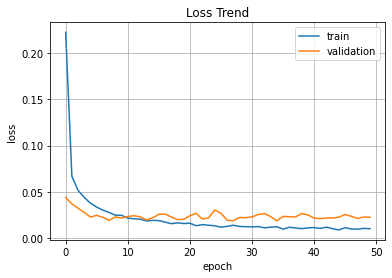
CNN 특징맵 시각화
for idx in range(len(model.layers)):
print('model.layers[%d] = %s, %s' % (idx, model.layers[idx].name, model.layers[idx].output.shape))model.layers[0] = conv2d, (None, 28, 28, 32)
model.layers[1] = max_pooling2d, (None, 14, 14, 32)
model.layers[2] = dropout, (None, 14, 14, 32)
model.layers[3] = conv2d_1, (None, 14, 14, 64)
model.layers[4] = max_pooling2d_1, (None, 7, 7, 64)
model.layers[5] = dropout_1, (None, 7, 7, 64)
model.layers[6] = conv2d_2, (None, 7, 7, 128)
model.layers[7] = max_pooling2d_2, (None, 4, 4, 128)
model.layers[8] = dropout_2, (None, 4, 4, 128)
model.layers[9] = flatten, (None, 2048)
model.layers[10] = dense, (None, 10)# 첫번째 층, 즉 0 번째 층만 떼어냄
partial_model=Model(inputs=model.inputs, outputs=model.layers[0].output)
partial_model.summary()Model: "model_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_input (InputLayer) [(None, 28, 28, 1)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 28, 28, 32) 320
=================================================================
Total params: 320
Trainable params: 320
Non-trainable params: 0
_________________________________________________________________feature_map = partial_model.predict(x_test[random_idx].reshape(-1,28,28,1)) # 부분 모델로 테스트 집합을 예측
print(feature_map.shape)
fm = feature_map[0] # 0번 영상의 특징 맵을 시각화
print(fm.shape)(1, 28, 28, 32)
(28, 28, 32)plt.figure(figsize=(10, 8))
for i in range(32): # i번째 특징 맵
plt.subplot(4,8,i+1)
plt.imshow(fm[:,:,i], cmap='gray')
plt.xticks([]); plt.yticks([])
plt.title("fmap"+str(i))
plt.tight_layout()
plt.show()
학습 후 첫 번째 풀링맵 시각화
for idx in range(len(model.layers)):
print('model.layers[%d] = %s, %s' % (idx, model.layers[idx].name, model.layers[idx].output.shape))model.layers[0] = conv2d, (None, 28, 28, 32)
model.layers[1] = max_pooling2d, (None, 14, 14, 32)
model.layers[2] = dropout, (None, 14, 14, 32)
model.layers[3] = conv2d_1, (None, 14, 14, 64)
model.layers[4] = max_pooling2d_1, (None, 7, 7, 64)
model.layers[5] = dropout_1, (None, 7, 7, 64)
model.layers[6] = conv2d_2, (None, 7, 7, 128)
model.layers[7] = max_pooling2d_2, (None, 4, 4, 128)
model.layers[8] = dropout_2, (None, 4, 4, 128)
model.layers[9] = flatten, (None, 2048)
model.layers[10] = dense, (None, 10)# 첫번째 층, 즉 0 번째 층만 떼어냄
pooling_map_1st_model=Model(inputs=model.inputs, outputs=model.layers[1].output)
pooling_map_1st_model.summary()Model: "model_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_input (InputLayer) [(None, 28, 28, 1)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 28, 28, 32) 320
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 14, 14, 32) 0
=================================================================
Total params: 320
Trainable params: 320
Non-trainable params: 0
_________________________________________________________________pooling_map_1st = pooling_map_1st_model.predict(x_test[random_idx].reshape(-1,28,28,1)) # 부분 모델로 테스트 집합을 예측
print(pooling_map_1st.shape)
pm = pooling_map_1st[0] # 0번 영상의 풀링 맵을 시각화
print(pm.shape)(1, 14, 14, 32)
(14, 14, 32)plt.figure(figsize=(10, 8))
for i in range(32): # i번째 풀링 맵
plt.subplot(4,8,i+1)
plt.imshow(pm[:,:,i], cmap='gray')
plt.xticks([]); plt.yticks([])
plt.title("pmap"+str(i))
plt.tight_layout()
plt.show()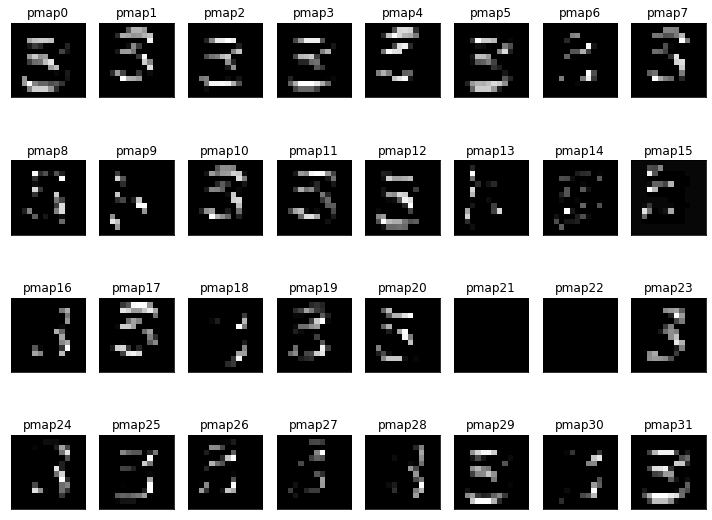
학습 후 두 번째 풀링맵 시각화
for idx in range(len(model.layers)):
print('model.layers[%d] = %s, %s' % (idx, model.layers[idx].name, model.layers[idx].output.shape))model.layers[0] = conv2d, (None, 28, 28, 32)
model.layers[1] = max_pooling2d, (None, 14, 14, 32)
model.layers[2] = dropout, (None, 14, 14, 32)
model.layers[3] = conv2d_1, (None, 14, 14, 64)
model.layers[4] = max_pooling2d_1, (None, 7, 7, 64)
model.layers[5] = dropout_1, (None, 7, 7, 64)
model.layers[6] = conv2d_2, (None, 7, 7, 128)
model.layers[7] = max_pooling2d_2, (None, 4, 4, 128)
model.layers[8] = dropout_2, (None, 4, 4, 128)
model.layers[9] = flatten, (None, 2048)
model.layers[10] = dense, (None, 10)from tensorflow.keras.models import Model
feature_map_2nd_model = Model(inputs=model.inputs, outputs=model.layers[4].output)
feature_map_2nd_model.summary()Model: "model_6"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_input (InputLayer) [(None, 28, 28, 1)] 0
conv2d (Conv2D) (None, 28, 28, 32) 320
max_pooling2d (MaxPooling2D (None, 14, 14, 32) 0
)
dropout (Dropout) (None, 14, 14, 32) 0
conv2d_1 (Conv2D) (None, 14, 14, 64) 18496
max_pooling2d_1 (MaxPooling (None, 7, 7, 64) 0
2D)
=================================================================
Total params: 18,816
Trainable params: 18,816
Non-trainable params: 0
_________________________________________________________________pooling_map_2nd = pooling_map_2nd_model.predict(x_test[random_idx].reshape(-1,28,28,1)) # 부분 모델로 테스트 집합을 예측
print(pooling_map_2nd.shape)
pm = pooling_map_2nd[0] # 0번 영상의 풀링 맵을 시각화
print(pm.shape)WARNING:tensorflow:6 out of the last 6 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7fb31b005710> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
(1, 7, 7, 64)
(7, 7, 64)plt.figure(figsize=(12, 10))
for i in range(64): # i번째 풀링 맵
plt.subplot(8,8,i+1)
plt.imshow(pm[:,:,i], cmap='gray')
plt.xticks([]); plt.yticks([])
plt.title("pmap"+str(i))
plt.tight_layout()
plt.show()
728x90
반응형
LIST
'Visual Intelligence > Image Deep Learning' 카테고리의 다른 글
| [시각 지능] 사전 학습된 CIFAR-10 모델로 이미지 예측 (1) | 2022.08.13 |
|---|---|
| [시각 지능] CIFAR-10 (0) | 2022.08.07 |
| [시각 지능] false prediction (0) | 2022.08.06 |
| [시각 지능] CNN Basic Architecture (0) | 2022.08.06 |
| [시각 지능] CNN (Convolutional Neural Network) (0) | 2022.08.06 |



