XGBoost
부스팅 (Boosting) 알고리즘은 앙상블 (Ensemble) 알고리즘의 하나로, 결정트리 기반의 알고리즘이다. 또 다른 앙상블 알고리즘인 배깅 (Bagging) 기법과의 차이점은, 배깅 기법이 평행하게 학습시키는 반면, 부스팅은 순차적으로 학습시킨다는 점이다. 첫 번째 약한 학습기가 분류를 진행하며, 잘못 분류된 데이터에 가중치를 두고 두번째 학습기가 다시 분류를 하게 된다. 이러한 방식으로 잘못 분류된 데이터에 가중치를 두면서 순차적으로 학습을 하여 결론적으로 강한 학습기를 구축한다.
XGBoost는 Gradient Boosting 알고리즘을 분산환경에서도 실행할 수 있도록 구현해놓은 라이브러리이다. Regression, Classification 문제를 모두 지원하며, 성능과 자원 효율이 좋아서, 인기 있게 사용되는 알고리즘이다.
|
XGBoost는 여러개의 Decision Tree를 조합해서 사용하는 Ensemble 알고리즘이다. 여러개의 이진 노드를 겹쳐서 피쳐별로 판단을 해서 최종 값을 뽑아내는 형태가 된다.
Ensemble은 여러 개의 모델을 조합해서 그 결과를 뽑아 내는 방법이다. 정확도가 높은 강한 모델을 하나 사용하는 것보다, 정확도가 낮은 약한 모델을 여러개 조합 하는 방식이 정확도가 높다는 방법에 기반한 방법인데, Ensemble은 방식에 따라서 Bagging과 Boosting으로 분류된다.
Bagging
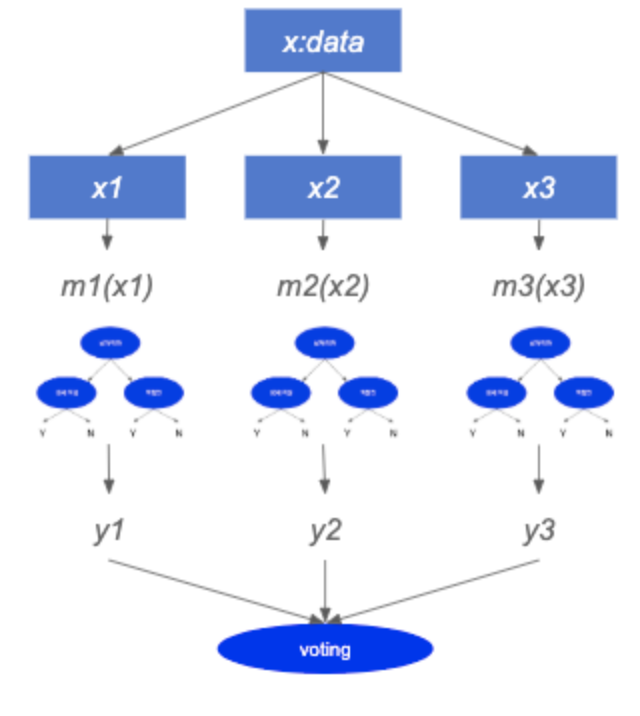
Bagging은 여러 모델을 사용할때, 각 모델에서 나온 값을 계산하여, 최종 결과값을 내는 방식이다. 예를 들어, 그림과 같이 모델 m1, m2, m3 3개의 모델이 있을 때, 입력 데이터 X를 모델 m1~3에 넣고, 그 결과값을 받아서 합산 (또는 평균등 여러가지 방법이 존재)해서, 최종 결과를 취하는 방식이다. 모델 m1~m3로 데이터를 넣을때는 원본 데이터 x에서 매번 다시 샘플링을 해서 다른 샘플 데이터를 각각 모델에 넣는 방식이 된다.
Boosting
Boosting은 원리가 다른데 먼저 m1~3 모델이 있을때, m1에는 x에서 샘플링된 데이터를 넣는다. 그리고 나온 결과 중에서 예측이 잘못된 x값 중에 가중치를 반영해서 다음 모델인 m2에 넣는다. 마찬가지로 y2 결과에서 예측이 잘못된 x’에 값들에 가중치를 반영해서 m3에 넣는다. 그리고 각 모델의 성능이 다르기 때문에 각 모델에 가중치 W를 반영한다. 이를 표현하면 다음과 같은 그림이 된다.

이를 다시 표현해 보면 y=m1(x)+error(x)
모델 m1이 x에 대해서 제대로 예측할 확률이 y라고 가정 한다. 여기서 정확도를 높이려면 error(x)를 작게 하는 모델을 적용하면
error(x) = m2(x) + error2(x)
마찬가지로 error(x)를 작게 하려면 error2(x)를 작게 하기 위해 다른 모델을 적용하면,
error2(x) = m3(x)+error3(x)
여기서 식을 합치면,
y= m1(x)+m2(x)+m3(x)+error3(x)
여기서 m1, m2, m3 모델의 가중치가 같기 때문에, 모델이 서로 간섭하여 좋은 결과를 내기 어렵다. 그래서 각 모델에 가중치를 반영하면,
y = W1m1(x)+W2m2(x)+W3m3(x)+error3(x)
Boosting 기법을 이용하여 구현한 알고리즘은 Gradient Boost가 대표적이다. 이 알고리즘을 병렬 학습이 지원되도록 구현한 라이브러리가 XGBoost이다.
https://xgboost.readthedocs.io/en/stable/
XGBoost Documentation — xgboost 1.6.0 documentation
© Copyright 2021, xgboost developers. Revision f75c007f.
xgboost.readthedocs.io
'Learning-driven Methodology > DL (Deep Learning)' 카테고리의 다른 글
| [Deep Learning] 딥러닝 프레임워크 비교 (0) | 2022.05.19 |
|---|---|
| [Deep Learning] 딥러닝 프레임워크 (Deep Learning Framework) (0) | 2022.05.19 |
| [Deep Learning] Orion을 통한 불안정한 시계열 이상 감지 (0) | 2022.05.03 |
| [Deep Learning] Basic Guide to Spiking Neural Networks for Deep Learning (3) (0) | 2022.01.17 |
| [Deep Learning] Basic Guide to Spiking Neural Networks for Deep Learning (2) (0) | 2022.01.17 |


