728x90
반응형
SMALL
디렉토리 설정
mkdir work
cd work
mkdir spark
cd spark
Pandas로 CSV 읽기
pyenv activate py3_11_9
pythonimport pandas as pd
url = 'https://raw.githubusercontent.com/losskatsu/data-example/main/data/iris.csv'
df = pd.read_csv(url)
df.head(3)
CSV 추출 및 parquet 변환
df.to_parquet('/home/ubuntu/work/spark/iris.parquet', index=False)
df.to_csv('/home/ubuntu/work/spark/iris.csv', index=False)
quit()
SQL
pyspark.sql은 데이터프레임과 SQL을 사용해 데이터를 조작하고 분석하는 기능을 제공한다.
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("CSVReader").getOrCreate()
csv를 읽기 위한 앱네임을 지정한다.
df = spark.read.option("header", "true").csv("/home/ubuntu/work/spark/iris.csv")
df.show(5)
다음으로, parquet을 읽기 위한 앱네임을 지정한다.
spark = SparkSession.builder.appName("ParquetReader").getOrCreate()
df = spark.read.parquet("/home/ubuntu/work/spark/iris.parquet")
df.show(7)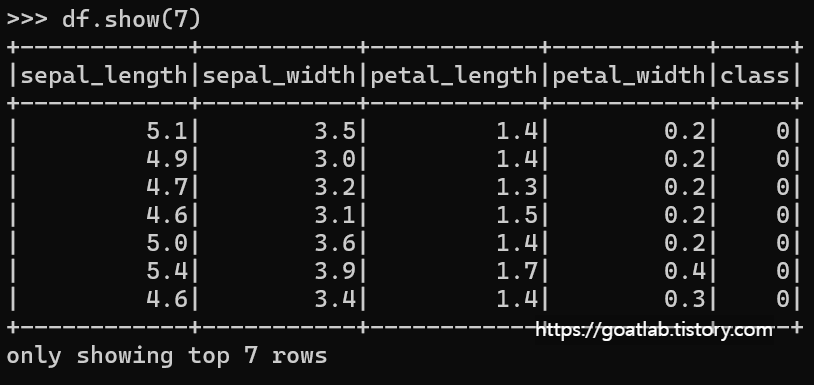
728x90
반응형
LIST
'Data-driven Methodology > Spark' 카테고리의 다른 글
| [Spark] Jupyter Lab (0) | 2024.07.15 |
|---|---|
| [Spark] PySpark 설치 (0) | 2024.07.15 |
| [Spark] 스파크 클러스터 (0) | 2024.01.08 |
| Apache Spark (0) | 2024.01.08 |



