트랜스포머 (Transformer)
트랜스포머 (Transformer)는 2017년 구글이 발표한 논문인 "Attention is all you need"에서 나온 모델로 기존의 seq2seq의 구조인 인코더-디코더를 따르면서도, 논문의 이름처럼 어텐션 (Attention)만으로 구현한 모델이다. 이 모델은 RNN을 사용하지 않고, 인코더-디코더 구조를 설계하였음에도 번역 성능에서도 RNN보다 우수한 성능을 보여주었다. 트랜스포머의 가장 큰 특징은 Convolution, Recurrence를 사용하지 않는다.
seq2seq 모델의 한계
기존의 seq2seq 모델은 인코더-디코더 구조로 구성되어져 있다. 여기서 인코더는 입력 시퀀스를 하나의 벡터 표현으로 압축하고, 디코더는 이 벡터 표현을 통해서 출력 시퀀스를 만들어냈다. 하지만 이러한 구조는 인코더가 입력 시퀀스를 하나의 벡터로 압축하는 과정에서 입력 시퀀스의 정보가 일부 손실된다는 단점이 있었고, 이를 보정하기 위해 어텐션이 사용되었다.
Long-Term Dependency / Parallelization
RNN에서 “I go home”이란 문장을 번역한다고 하면, 'home'이 입력으로 들어가는 타임 스텝에서도 앞서 등장한 'I'와 'go'의 정보도 담겨져있다. RNN은 타임 스텝 수만큼의 정보가 전달이 되기 때문에, 멀리 있는 스텝까지 전달되는 과정에서 정보 유실이 발생할 수 있다. 이러한 문제를 “Long-Term Dependency”라고 부른다.
| bi-directional RNN | forward 와 backward 두 개의 RNN을 만들고 히든 스테이트 (hidden state)를 RNN마다 각각 가져와서 concat한 후 2배 차원을 가지는 히든 스테이트로 인코딩 결과값을 내준다. 이렇게 동작하는 RNN모델을 “bi-directional RNN”이라고 부르며, 단일 RNN보다 멀리있는 정보도 비교적 잘 반영해준다 (완벽하진 않음). |
| Transformer | 모델에 들어가는 입력과 출력의 세팅은 RNN과 동일하다. 주어진 쿼리 (Query)에 대해서 어느 키 (Key)와 유사도가 높은지 점수를 계산하고 산출된 점수에 소프트맥스 (softmax)를 취해서 Value 벡터에 곱해준다. 이후, 선형 결합을 거쳐서 한개의 아웃풋 백터를 만들어주는 것을 Transformer 알고리즘이라고 부른다. |
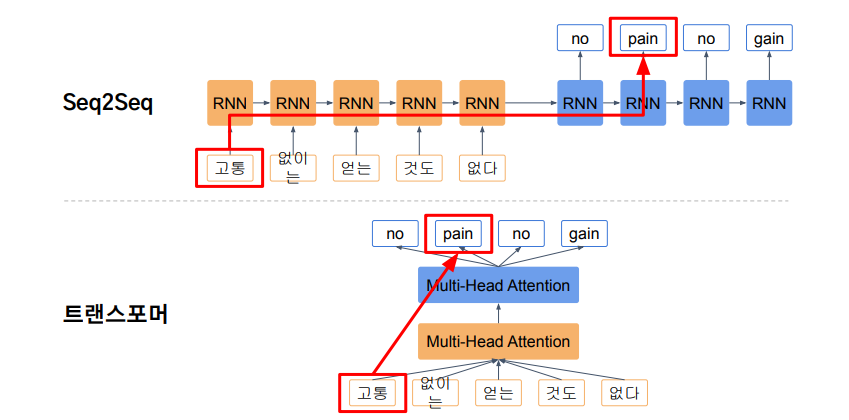
RNN은 이전 hidden state를 사용함으로써, 순차적으로 계산이 되어야 한다 (병렬화 불가능). 트랜스포머는 행렬 연산을 병렬화하여 빠르게 계산가능하다. 또한, 어떤 정보와 다른 정보 사이의 거리가 멀 때, 해당 정보를 이용하지 못하는 것이 RNN의 문제점이다. 이것을 Attention mechanism으로 해결한다.
Query / Key / Value

쿼리로 Training이 들어오면 Thinking , Machine 두 개의 키에 대해 내적하여 스코어를 구해준다. 마찬가지로 다음 쿼리로 Machine이 들어 오면, Thinking,Machine 두 개의 키에 대해 내적하여 스코어를 구해준다. 구해진 스코어를 기반으로 기존 벡터 (Value, 벨류)에 곱해서, 선형결합을 거쳐 한 개의 어텐션 벡터를 준다. 이렇게 내적에 대한 유사도만 높으면, 거리가 멀더라도 정보를 알맞게 잘 가져올 수 있다. RNN에서는 연속적으로 스텝 수 만큼 통과해서 전달해 정보의 손실이 발생하는 것과 달리, 어텐션은 거리와 상관없이 잘 작동할 수 있다.
'Learning-driven Methodology > DL (Deep Learning)' 카테고리의 다른 글
| TabNet (0) | 2024.04.21 |
|---|---|
| [Deep Learning] 트랜스포머 구조 (0) | 2023.12.28 |
| [Deep Learning] Attention Mechanism (0) | 2023.12.28 |
| [Deep Learning] Seq2Seq (Sequence to Sequence) (0) | 2023.12.27 |
| [Deep Learning] 1D CNN (0) | 2023.09.27 |



